What is an ETL Pipeline? Benefits, ETL pipeline tools, and use case examples

Data pipelines collect, organize, and deliver data so that it’s ready for analysis. One of the easiest and most common approaches is to use the Extract, Transform, and Load (ETL) pipeline.
This method worked well when data volumes were smaller and systems were hosted on-premises. But businesses now collect a lot more data, and they need to process it faster. By 2025, the amount of data generated worldwide is forecast to hit 181 zettabytes.
Traditional ETL pipelines often struggle to keep up with this pace. Let’s learn how ELT pipelines powered by automated data pipeline tools like Fivetran offer a way forward.
What is an ETL pipeline?
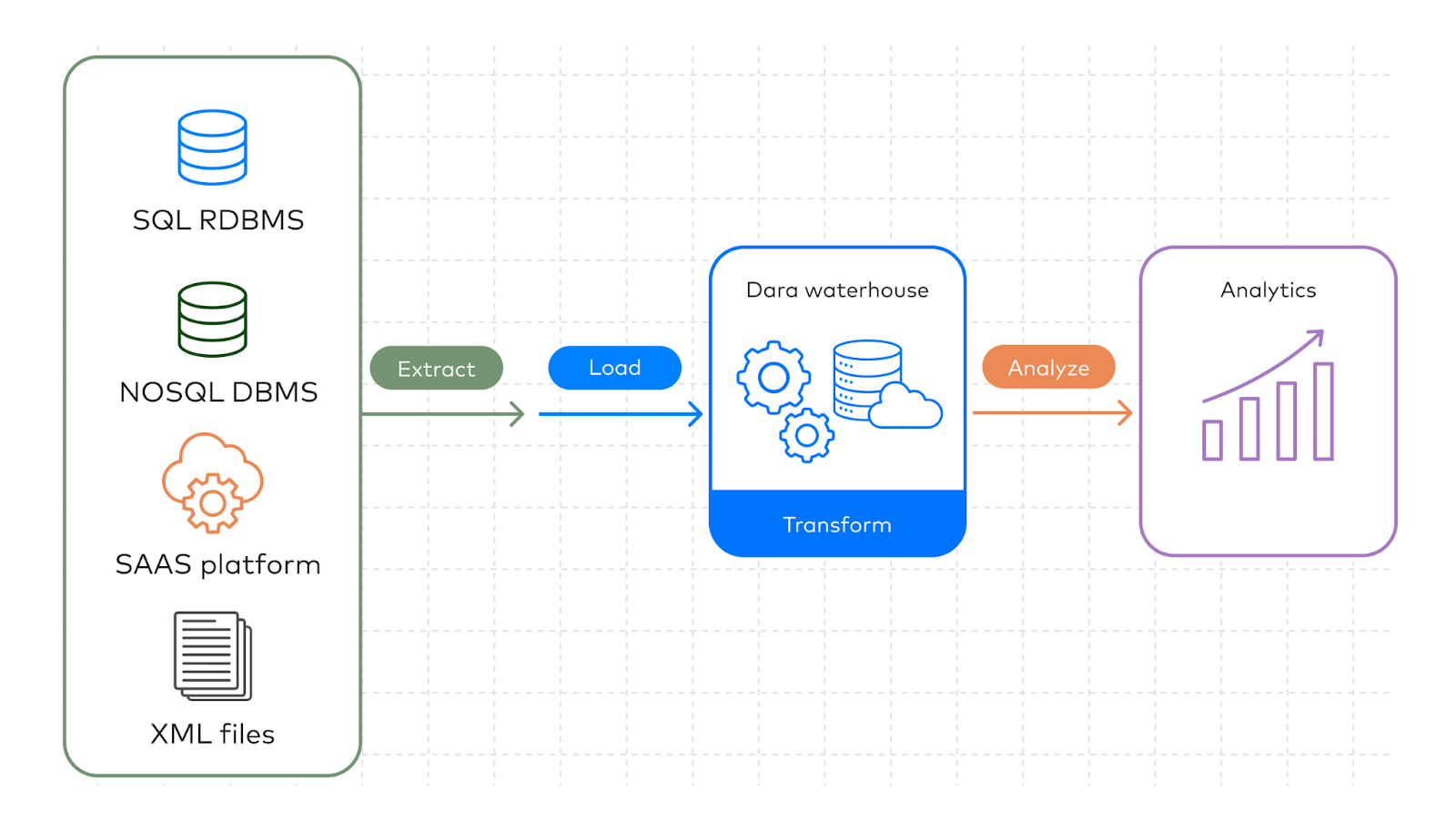
An ETL pipeline extracts data from various sources, transforms it, and then loads it into a destination.
Using the ETL data integration method, analysts get access to a central repository of cleaned and formatted data. They can use this data for marketing analytics and business intelligence (BI).
There are 3 stages in the ETL process:
Extraction phase
In the extraction stage, data from multiple sources is collected and loaded onto a staging area or intermediate destination. Common data sources include:
- SaaS applications
- CRM platforms
- Sales and marketing tools
- Event streams
- SQL or NoSQL databases
Data from these sources can be synced synchronously or asynchronously, depending on data analysis requirements. For example, data from a CRM tool can be updated twice a week, whereas customer app data can be collected daily.
Transformation phase
Transformations prepare extracted data for downstream applications by cleaning and formatting it. The objective is to get the data ready for querying in the target storage, such as a data warehouse like Google BigQuery, Redshift, and Snowflake or databases like MongoDB, and PostgreSQL.
The extracted data must be transformed into a standard format to fulfil the target database's schema requirements. This is done by running several functions and applying a set of rules to the data. The degree of manipulation necessary for ETL transformation totally depends on the extracted data and the business demands.
Some of the basic processing activities involved in the data transformation stage are as follows:
- Normalization: Makes data consistent by putting it into a standard format, like converting all dates into the same style.
- Cleansing: Removes errors or irrelevant information, such as fixing typos or deleting invalid entries.
- Restructuring: This process changes the organization of data to match a desired data model, such as splitting full names into first and last names.
- Deduplication: Identifies and eliminates repeated records so only 1 version of each unique entry remains.
- Data validation: This process checks the structured data against rules to ensure accuracy, such as confirming that an email field contains a valid address.
Depending on the use case, it can also include other actions like summarization, sorting, ordering, and indexing.
Load phase
The loading process moves transformed data to a centralized destination, like a database, data warehouse, data lake, or cloud data warehouse. In some cases, data can also be sent directly into BI tools, which are software platforms that let teams create dashboards, run reports, and turn raw numbers into business insights more quickly.
Types of ETL pipeline tools
Depending on various factors, like cloud-based, on-premise, real-time and others, you can basically divide the ETL tools into the following categories:
Custom ETL tools
Businesses with in-house data engineering and support teams can create their own tools and pipelines using languages like SQL, Python, and Java. While this approach offers maximum flexibility, it also requires the most effort and work. Plus, users are responsible for testing, documenting, maintaining, and continuously developing their solutions.
Batch ETL tools
For many businesses, the only workable ETL method up until very recently was batch processing in on-premises tools. In the past, processing vast amounts of data required a lot of time and energy and could quickly exhaust a company's computing and storage capacity during business hours.
Hence, it made more sense for businesses to use batch data processing with ETL tools during off-peak hours. These tools performed data extraction, transformation, and loading in batches.
Real-time ETL tools
Real-time ETL tools extract, transform, and load data onto the target system in real time. Batch processing works fine for some data updates.
However, we now need more frequent real-time access to data from various sources. Real-time demand is forcing us to process data in real-time rather than in batches, using a distributed paradigm and streaming capabilities.
As a result, these ETL tools are growing in popularity as businesses look for insights that can be immediately used. Numerous near-real-time ETL tools are available, both commercially and as open source.
On-premise ETL tools
Many businesses use older systems with on-premises data and repository configuration. Data security is the main driver for such an arrangement, so firms prefer to have an ETL tool installed on-site.
Cloud ETL tools
Companies increasingly use cloud-based ETL tools to ingest data from web applications or on-premises sources. Deployed in the cloud, these tools simplify extracting and loading data as most data and applications are cloud-supported.
This also conserves resources and reduces costs associated with setting up the ETL tool. Cloud ETL tools provide high availability, elasticity, and low latency, enabling resources to scale and meet the current data processing demands.
Open-source ETL tools
Numerous open-source ETL tools have been developed over the past decade. Since these ETL tools are readily accessible, a large testing community continually provides feedback to improve or expand their features.
Hybrid ETL tools
Integrating the features of the above ETL tool types will give you a hybrid ETL tool. So, multiple ETL tasks can be handled at scale by a single ETL platform.
ETL pipeline use cases: 3 Examples
- Data integration and standardization:
- ETL pipelines integrate data from diverse sources into a single, unified repository (often a data warehouse).
- They handle data cleaning and transformation before loading to a target destination.
- By centralizing and standardizing data, they can produce the consistent, unified datasets needed to power BI dashboards, AI, and machine learning.
- Legacy data migration:
- As organizations upgrade from legacy systems to modern platforms, ETL pipelines allow for smooth, secure database migrations.
- This transition supports faster processing speeds and faster time to insights.
- Audit trails and data governance:
- ETL pipelines can structure and store data in formats required by independent auditors and regulatory agencies.
- Audit logs make it easy to trace how data was handled, often including timestamps, source and destination identifiers, user actions, and transformation logic.
ETL pipeline challenges
Despite their benefits for some analytical use cases, ETL tools present certain challenges for organizations and data teams.
High engineering and operational costs
Engineers must build a new pipeline for every data source, adding to their workload of managing existing pipelines. Building and applying transformations adds another challenge.
Since ETL pipelines are built for specific use cases, qualified engineers with special training might be required to manage the system. They must constantly write custom scripts, manage connectors, and fix broken jobs.
These factors cost companies thousands of dollars in additional workers, extra working hours, and the facilities required to house these employees.
Scalability
ETL pipeline architecture relies on servers for data processing. As the volume and variety of data increase, the setup must also be scaled. Doing this involves a significant investment, especially if it requires on-premise hardware and takes time.
This system might work for batch processing. But, scaling an ETL pipeline becomes unfeasible as the need for real-time data processing grows. This eventually also slows down reporting cycles and prevents real-time analysis.
Fragility
ETL pipelines are tightly coupled with both their sources and destinations. So changes in upstream systems, like adding a new field to Salesforce or a scheme update in an ERP tool, can instantly break pipelines.
Data quality
In ETL, data transformations happen before reaching the data warehouses or . As a result, missing values, duplicate entries, or mismatched formats can result in data inconsistencies.
ETL vs ELT vs hybrid pipelines
We’ve already examined an ETL data pipeline, but it’s not the only approach. Understanding ELT and hybrid models is equally important.
ELT
ELT is a data integration method where data is collected from a source, loaded onto a cloud data warehouse or other destination, and then transformed by analysts when needed. It loads data first and relies on it for transformation.
Hybrid
Hybrid models combine both to offer flexibility when data comes from many different environments.
Despite the rise of cloud-native tools, ETL is still common in compliance-heavy environments where data must be transformed before leaving its source. It’s also common in organizations with legacy systems that can’t easily support ELT, or in cases where bandwidth restrictions make moving raw data impractical.
ETL is valuable for masking sensitive personally identifiable information (PII) early in the process and for building highly predictable, tightly controlled pipelines.
To make these trade-offs easier to understand, here’s a table that compares ETL, ELT, and hybrid architectures side by side.
Related resources:
ETL vs. ELT: Choose the right approach for data integration
Data pipeline vs. ETL: What they do and when to use each
Why ELT is the way of the future
ELT is the ideal data integration architecture for many of today’s business needs.
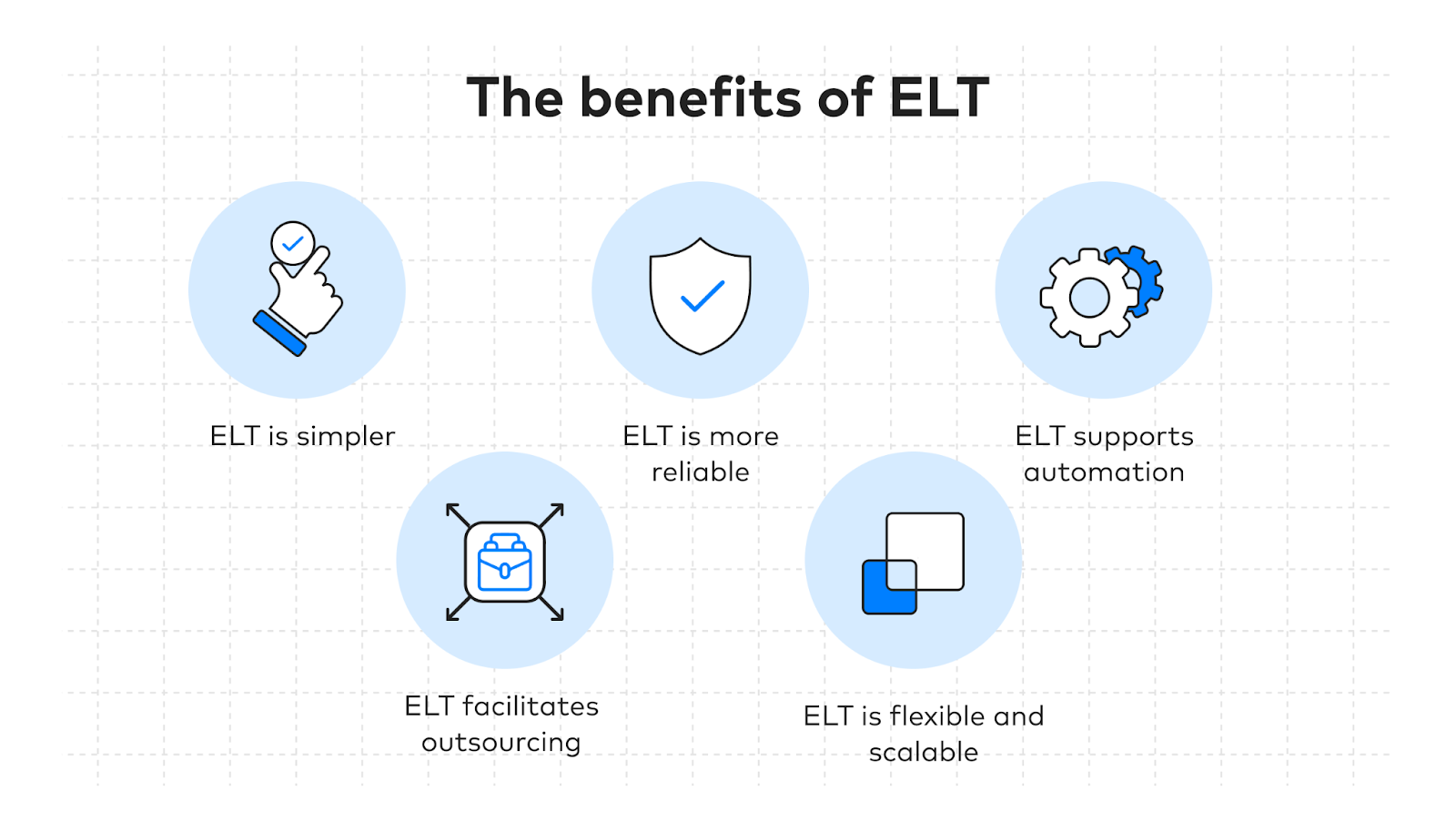
Organizations are switching to fully-managed ELT for 5 crucial reasons:
ELT is simpler
ELT simplifies data integration by populating databases directly from the source. This ensures data integrity and is easier for analysts, who can create better models to suit their analytical needs.
It also streamlines data engineering and development by enabling a no-code data pipeline set up in minutes. This reduces their workload and allows them to focus on more mission-critical tasks.
ELT is more reliable
ELT pipelines eliminate the need for constant pipeline rebuilding because the loading and transformation processes are independent. Data teams have faster access to data and can build and modify data models based on business use cases without interrupting data movement from the source.
If you choose a fully-managed solution like Fivetran, maintenance and troubleshooting are handled by the tool’s developers rather than yours. The platform is regularly updated to boost security and compliance and add more features.
ELT supports automation
ELT pipelines that third-party vendors handle automate mundane pipeline maintenance tasks like modifying data extraction scripts, keeping schema up-to-date and normalizing data source extracts.
Automation can also be powered by integration with other data management tools.
ELT facilitates outsourcing
Organizations using automated ELT can create standardized data models that can facilitate outsourcing. Outsourcing data pipeline management can save time and money while freeing up your data teams to focus on their core tasks.
Platforms like Fivetran allow role-based access so companies can control how contractors or third parties interact with their data. An easy-to-use interface also means pipeline modification can be done in a few clicks without needing specially-trained experts.
ELT is flexible and scalable
ELT pipelines don’t have to stick to specific transformations. Instead, they let data scientists and analysts decide what to do with the data and implement their own data analysis processes.
Moreover, cloud platforms are easy to scale. Fivetran, for example, uses a payment model where you only pay for what you use. Companies can unlock new resources by upgrading their subscription plan.
This eliminates the need for expensive on-premise upgrades or buying other systems to support a fast-growing ETL pipeline.
Fivetran: the modern alternative
Fivetran takes away much of the manual work that older ETL pipelines still require. Instead of building and maintaining complex scripts, teams can rely on ready-made automation.
Here’s what makes it different. Fivetran has over hundreds of automated connectors for the tools businesses already use, from CRMs and ERPs to marketing platforms and databases.
Fivetran supports schema migration handling. This means that even if there are some changes in source systems, data pipelines will stay intact and resilient.
For security, it offers enterprise-grade protections, including SOC 2, HIPAA, GDPR, PCI DSS, and ISO 27001. It also allows role-based access, so companies can control how contractors or third parties interact with their data. An easy-to-use interface also means pipeline modification can be done in a few clicks without needing specially trained experts.
Other key features:
- Allows teams to schedule syncs flexibly and set custom frequency options, so data updates match operational needs.
- Includes built-in tools to track users and log errors.
- Supports structured and unstructured data to unify analytics of different data formats.
- Works natively with platforms like Snowflake, BigQuery, and Redshift, making data ingestion painless.
- Uses a payment model where you only pay for what you use.
- Reverse ETL capabilities to push data back into the operational tools teams use.
Emery Sapp & Sons struggled with manual data pipelines and inconsistent Excel reporting, which slowed analysis and decision-making. Fivetran helped automate their data pipelines, saving them 20% of their time and 5-6 hours per month previously spent on creating reports. This automation enabled real-time dashboards and consistent data views, freeing their team from maintenance work.
Cars24 faced frequent MySQL downtime and a costly, lengthy internal pipeline project. Fivetran replaced its pipelines with reliable, zero-maintenance connectors to Snowflake. This freed analysts to run queries anytime, helped cut costs, and enabled better marketing budget decisions.
Conclusion
ETL data pipelines are suitable for organizations managing smaller data volumes that can tolerate slower insights through batch processing.
A fully managed ELT pipeline is ideal for companies looking for reliable data pipelines with minimal engineering overhead that can easily scale.
[CTA_MODULE]
Related posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







