Data pipeline vs. ETL: What they do and when to use each

ETL and data pipelines are closely connected, but they're not interchangeable. While both help teams move data and use much of the same terminology, they serve distinct purposes.
Whether building dashboards, syncing systems, or feeding real-time analytics, understanding their differences lets you design more efficient, scalable data workflows.
In this beginner-level data pipeline vs ETL guide, we'll explain the differences, show where they overlap, and help you choose the right approach based on your goals.
[CTA_MODULE]
What is a data pipeline?
A data pipeline is a system that moves data from one place to another. Pipelines connect:
- Data sources: Tools like CRM platforms, product databases, or event logs), and
- Destinations: A data warehouse, database, or other centralized location.
Pipelines can include multiple branches, loops, and processes, but they all share the same core components.
Pipeline components
Sources
This is where the data originates.
Common examples:
- APls
- Databases
- Data lakes
- SaaS tools.
Processing steps
This is where the transformation occurs.
Common processing activities:
- Cleaning (fixing errors or removing duplicates)
- Enriching (enhancing data to make it more useful)
- Aggregating (calculating subtotals or averages)
- Reshaping (changing the format or structure)
- Routing (sending data through a series of steps or workflows)
Destinations
This is where the data goes.
Common examples:
- Data warehouses
- Business intelligence platforms
- Operating systems
- Real-time analytics tool
- Executive dashboards
Those are just the basics. Depending on the organization’s needs, data might also go through more steps after reaching its destination — like temporary storage, quality checks (data validation), or other supporting workflows.
At their highest level, all pipelines aim to reliably move data from sources to end users.
What is ETL?
ETL is a sequential process used to move and prepare data for downstream use.. It’s always made up of 3 phases: extract → transform → load.
First, ETL retrieves data from various sources. Then, the transformation phase cleans, enriches, or reformats the data. And ultimately, it loads the clean data into a centralized location (like a data warehouse)
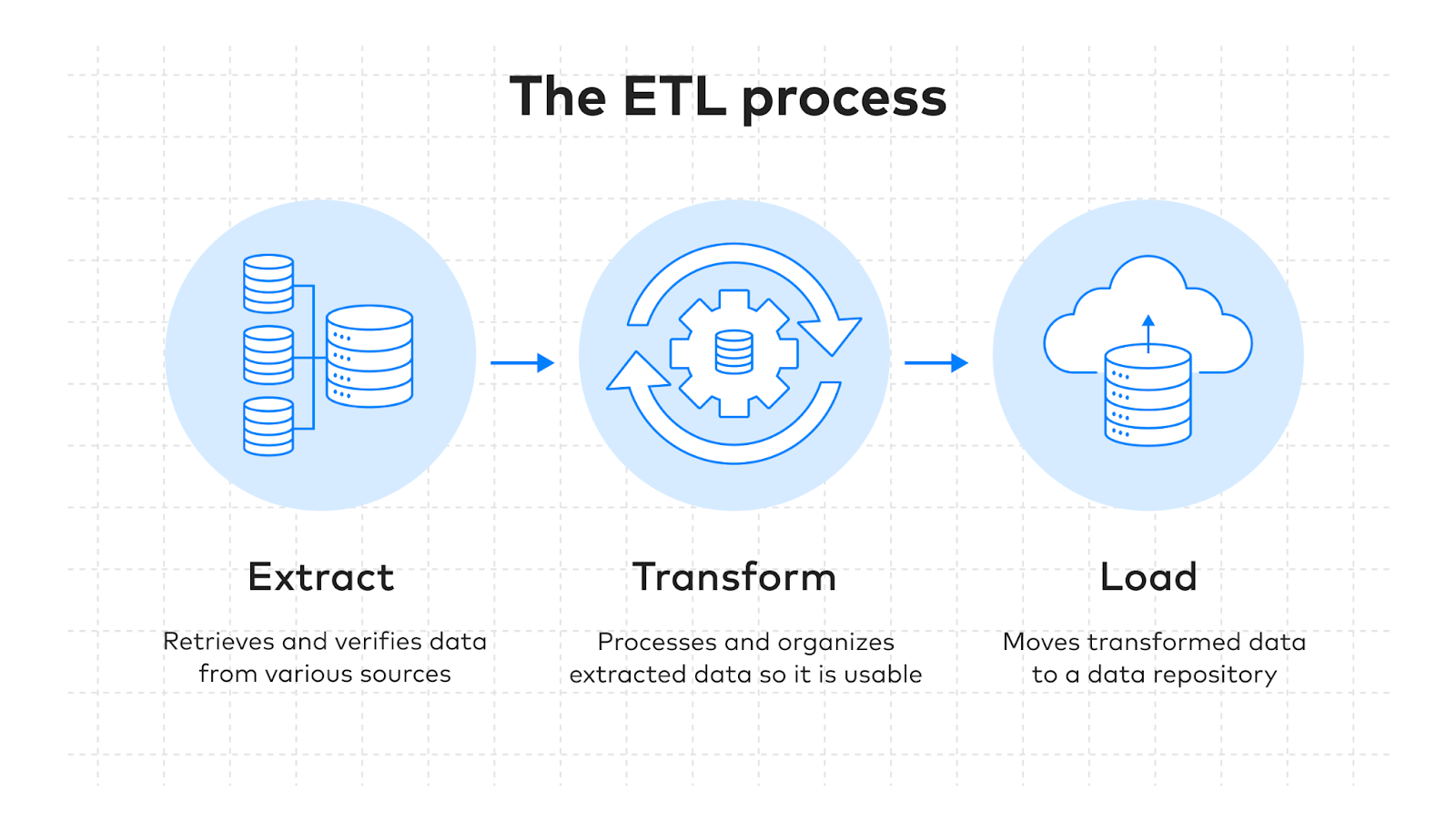
ETL is one of the most often-used ways to move and clean data. But it’s just one process within a larger data pipeline, not a wholly separate concept.
ETL pipelines are often used when:
- Structured, batch processing is required
- Data integrity and transformation control are high priority
- Destinations focus on analysis or reporting
For a more detailed breakdown of the process, see our in-depth ETL data pipeline guide.
Key differences: Data pipelines vs. ETL pipelines
If ETL is like a manufacturing assembly line — a structured, linear process performed in batches — then, a data pipeline would be the entire manufacturing facility.
While ETL processes may be at their core, data pipelines can connect to multiple other branches, loops, and systems beyond that.
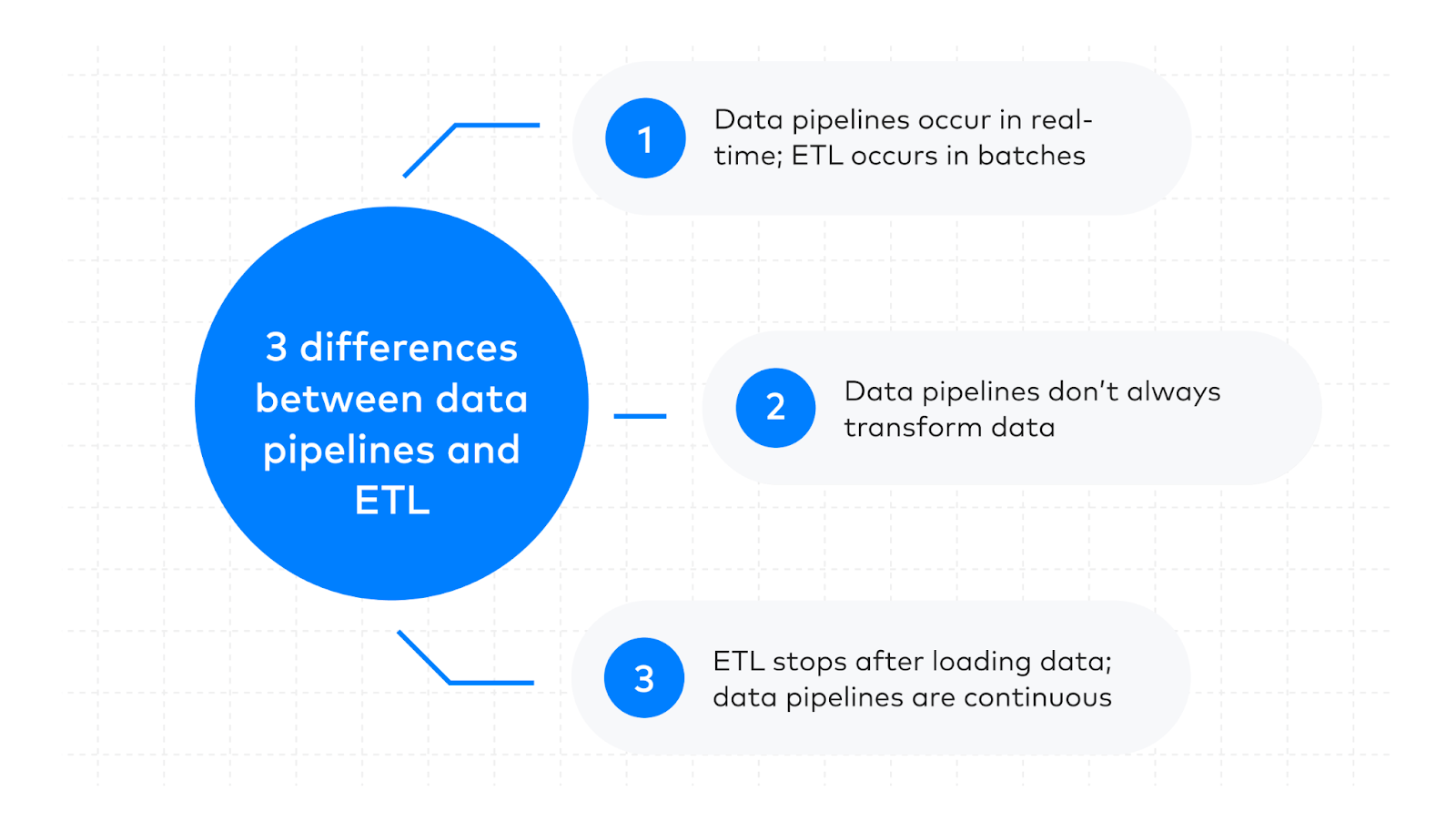
1. Real-time vs. batch processing
Traditional ETL pipelines only run in scheduled batches (e.g., hourly, daily, weekly), while many modern data pipelines are designed for continuous, real-time workflows.
That said, not all pipelines work in real-time, and not all ETL tools can only do batch processing. Today’s platforms are constantly evolving, and many ETL pipelines can now support near real-time processing.
2. Transformation timing
The transformation phase timing is the ETL pipeline’s defining trait. It must always transform data before loading it into a destination system.
Data pipelines can transform data at any stage: before loading, after loading, or not at all. Many big data applications prefer to wait and only perform transformation steps when needed.
3. Continuous workflow vs discrete process
ETL is a sequential process that ends when data is transformed and loaded into a warehouse or other destination. Any steps or actions that happen after — like analysis or further transformation — are separate from the ETL pipeline.
Data pipelines are ongoing workflows built around a specific purpose or organizational need. They may include ETL steps as supporting processes, but they also move, process, and analyze data beyond its initial destination.
Data pipeline vs ETL: Step-by-step decision guide
Use this guide to determine which integration method fits your architecture, processing, and real-time data integration needs.
Step 1: Do you need to pull data from multiple sources?
No → Use a data pipeline. Simple transfer between systems/platforms
Yes → Continue to Step 2 ⬇️
Step 2: Do you need to automate data transfers between systems?
No → Use a data pipeline. Lightweight tools may suffice.
Yes → Continue to Step 3 ⬇️
Step 3: Do you need to clean, reformat, or enrich the data?
No → Use a data pipeline. Move data to the destination as-is.
Yes → Continue to Step 4 ⬇️
Step 4: Do you need to combine and transform multiple data sources into a unified view?
No → Use a data pipeline with basic transformation/post-load processing.
Yes → Consider an ETL pipeline or ELT process (See our ETL vs ELT: Side-by-side comparison to learn more about how they differ)
When to use data pipelines
Consider data pipeline if you need to:
- Store raw or structured data in flexible formats for future use
- Move data into a lake architecture to support scalable analytics
- Route information across systems without transforming it first
- Stream data continuously for live metrics or business intelligence dashboards
- Use cloud storage as part of your pipeline design
- Connect multiple tools or destinations across workflows
- Automating AI workflows with continuous data feeds
When to use ETL pipelines
Consider ETL when you need to:
- Replace manual spreadsheets with reliable, repeatable jobs
- Clean and organize data before storing
- Combine multiple data sources into unified reports
- Standardize formats across tools/platforms (e.g., dates, currencies)
- Load verified, structured data into a warehouse
- Automate recurring reports (daily, weekly, monthly)
- Secure data with compliance-ready workflows
- Feed dashboards or analytics tools with fresh, reliable data
Pro Tip: In reality, it’s rarely an either/or decision. Most modern architectures mix batch ETL with real-time workflows. The key is to select a method that works with your data sources, latency requirements, and business needs.
Get the best of both with Fivetran
The best method will always depend on your needs. ETL pipelines work best when you need to store pre-cleaned, structured data. But if speed matters, modern data pipelines are more suited for real-time workflows.
Need an option that scales across use cases?
If you're working with flat files, legacy systems, or dozens of SaaS platforms, Fivetran helps you move data reliably — whether it’s in batches or real time.
Start your free trial today to start building smarter workflows with Fivetran.
Related resources:
- Modern data pipeline guide - Learn how ETL, ELT, and streaming tools converge in modern architectures.
- ETL vs ELT comparison - Understand transformation strategies and tooling tradeoffs.
- Fivetran connectors catalog - Discover prebuilt connectors by source, destination, and category.
- Fivetran product overview - Explore features, automation, and supported workflows.
- The Ultimate Guide to Data Integration - Exactly what it sounds like.
Related posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







