Top Snowflake ETL tools for data teams

Snowflake’s performance depends on many factors, including its architecture, quality, timeliness, and scale of loaded data. Since organizations produce vast amounts of data every day, they need a reliable and fast tool to get it into a ready-to-use format.
For this reason, the choice between Snowflake ETL tools and ELT processes can determine whether Snowflake will produce real-time information or turn into delayed/incomplete data storage.
Selecting the right ETL tool for Snowflake isn’t just about finding a tool that costs less or has more connectors. It’s about matching tool capabilities with requirements, whether that means minimal maintenance, complex change support, or governance and security requirements.
What are Snowflake ETL Tools?
Snowflake ETL tools are software platforms that:
- Extract source data from databases, snowflake data warehouses, data lakes, SaaS applications, APIs, event streams, or other data storage
- Load it into Snowflake using custom or prebuilt connectors
- Perform cleaning, enriching, reshaping, and other data transformation processes inside Snowflake
- Prepare data for downstream use in dashboards, models, and other reporting tools or applications
- Support both batch and real-time data processing pipelines
Some of these tools focus on traditional ETL processes (where data is transformed before being loaded), whereas others use ELT (where raw data is first loaded and then transformed with Snowflake compute). Their primary purpose is to ensure that data reaches Snowflake consistently, in the correct format, and at the right frequency for business use cases.
Top 6 Snowflake ETL/ELT Tools
Now, we will compare 6 commonly used ETL tools and highlight their strengths, limitations, and pricing to help you identify the best option for your needs. We will also discuss how these tools compare with respect to their integration and working with Snowflake.
1. Fivetran
Best for: Teams that need automated ETL/ELT pipelines with minimal engineering overhead
Fivetran is a fully managed ELT platform that simplifies data ingestion into Snowflake. It has an extensive library of 700+ pre-built, no-code source connectors for SaaS applications, databases, APIs, and event streams.
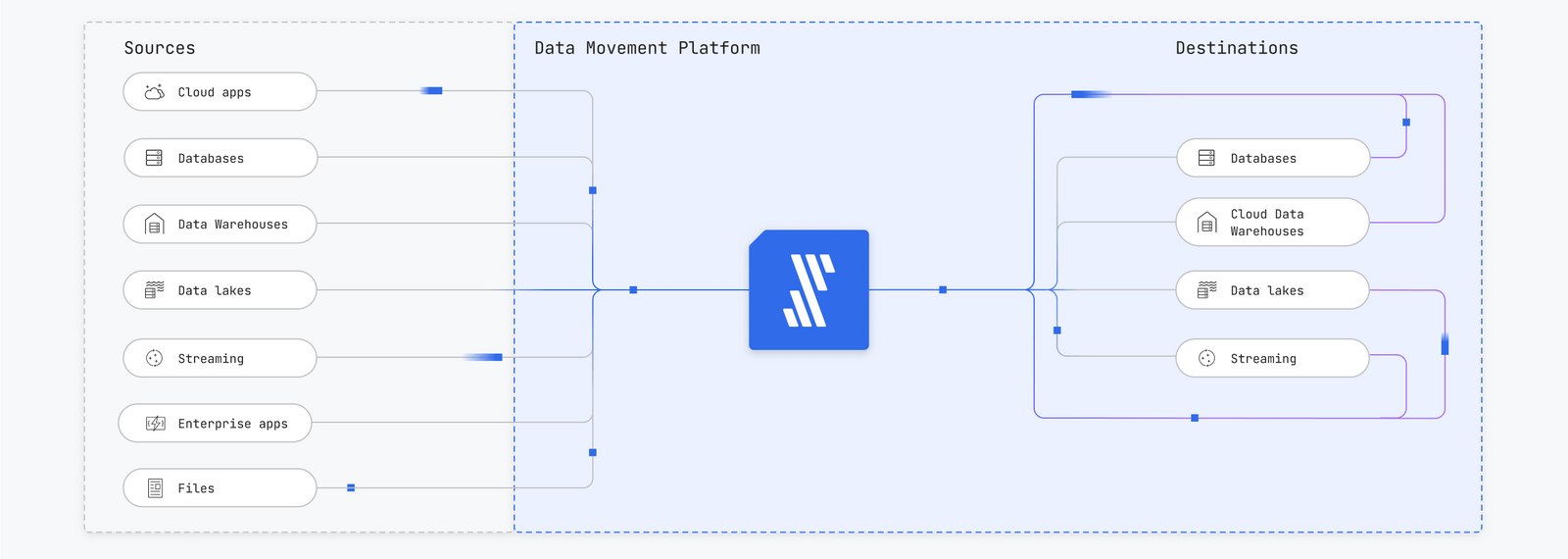
The automated change data capture and schema drift handling make Snowflake tables update automatically when source fields change. Teams don’t need to define every column before loading data and can apply data definition language (DDL) later if required. This reduces manual maintenance and keeps pipelines accurate, even when sources change frequently.
This ELT tool also provides prebuilt connectors and quick-start data models for analytics-ready datasets. For example, if you are using Salesforce CRM, these models will transform incoming Salesforce CRM objects into Fivetran output objects/outputs that allow you to run analytics immediately.
Fivetran supports ELT and reverse ETL processes and can be deployed in managed, hybrid, or self-hosted modes. It supports SQL modeling with a defined schema and entity-relationship diagrams (ERD), which simplifies analytics. Its high-volume replication capabilities move up to 50 GB per hour, making real-time synchronization possible.
This ELT tool is preferred by those analytics and business intelligence (BI) teams who want real-time data without dedicating engineering resources to pipeline maintenance. It fits organizations that pull from multiple data sources and need frequent or near real-time reporting. However, it is less suitable for teams that require custom logic or complex orchestration.
Fivetran provides limited transformation capabilities. Users also have limited customization options.
Fivetran's pricing is based on monthly active rows (MAR). This means that you pay for only the processed records, and as your data volume increases, the cost per row decreases.
2. Talend
Best for: Teams that need enterprise-grade integrations and governance features.
Talend is a data integration platform that provides 100+ connectors for various sources, including databases, SaaS applications, cloud data warehouses, and big data platforms. This makes it useful for teams with strong data engineering capabilities who need to pull data from multiple sources. It also supports both batch and streaming, as well as row-by-row transformation, which is helpful for conditional logic.
Talend's dynamic schema feature lets users load data without predefined table columns. It also provides master data management (MDM) and data quality tools to keep Snowflake synchronized with updated data streams.
The platform also supports continuous integration and continuous delivery/deployment (CI/CD) pipelines. Its role-based access controls and metadata management make it a great choice in environments like healthcare, finance, and telecommunications, where strict governance and compliance are top priorities.
Talend follows a subscription-based pricing model. It provides a free community edition, “Talend Open Studio,” with limited capabilities, and a professional paid version, “Talend Data Fabric,” starting at $1170 per user per month (and also offers enterprise-wide licensing plans). They also provide other features like real-time big data streaming, Spark integration, and machine learning, but these require separate paid extensions. Another drawback is that it focuses on Java-based transformations, making it unsuitable for SQL or Python-based workflows.
3. Matillion
Best for: Teams that need SQL-based transformations with a user-friendly interface.
Matillion is also a cloud-based ETL/ELT tool designed for data warehouses, such as Snowflake. It has a browser-based, low-code interface for building data pipelines. Their push-down ELT approach enables direct transformation in Snowflake, leveraging its compute power.
This platform supports 80+ pre-built connectors for SaaS applications, databases, and APIs. It also includes workflow features like scheduling, job chaining, collaboration, version control, and orchestration. These make it suitable for teams that want more control than a fully managed tool like Fivetran but less complexity than an enterprise solution such as Talend. However, this platform is suitable only if the data stack is Snowflake-centric.
Matillion's pricing model is credit-based, which means credits are spent when loading multiple rows or using virtual core hours to run ETL jobs. They charge between $2 (for basic features) and $2.70 (for using all the features) per credit.
It has minimal clustering support, which negatively impacts its performance on very large datasets. This makes it harder for multiple team members to work on the pipeline simultaneously. Connectors like DynamoDB are not supported, which is also a con and requires extra integration steps.
4. Apache Airflow
Best for: Teams that need orchestration and full customization.
Apache Airflow is an open-source tool used to create, schedule, and monitor custom data pipelines. It focuses on orchestration rather than transformation, which means engineers define their workflows using Python-based directed acyclic graphs (DAGs).
Airflow enhances Snowflake by providing scheduling for data ingestion, overseeing transformations, and developing downstream workflows. Its flexibility allows for conditional workflows when integrated with tools like Fivetran or dbt, simplifying the management of job scheduling, dependencies, and automation within the data pipeline.
The tradeoff with Airflow is that it’s self-hosted and needs a lot of work to keep it running. Unlike the previous solutions, it doesn't have built-in connectors. This means you'll need to manually connect everything, so it’s not ideal for teams that don't have engineering resources.
Overall, Airflow is a useful orchestration platform, but it’s best suited for organizations with strong DevOps or data engineering teams that manage their own infrastructure and need complete control over custom workflows.
5. Informatica
Best for: Organizations requiring high security, scalability, and good compliance.
Informatica is an enterprise-grade data integration tool that supports both ETL and ELT processes with Snowflake. It provides features like dynamic schema handling, runtime table creation, transaction support for DDL and data manipulation language (DML) statements, error notifications, and 128-bit SSL encryption for secure data transfer. The role-based access and centralized key management features make it a suitable tool for industries such as government or finance, which require strict compliance.
The platform enables parallel processing and partitioning, facilitating the efficient management of large datasets at high speeds. It can be deployed in hybrid and multi-cloud environments, allowing enterprises to deploy it on-premises or in cloud environments. Its features, such as parameterization, runtime overrides, and connection reusability across different environments, provide additional flexibility.
This Snowflake tool can be an excellent choice for larger organizations that manage large amounts of sensitive data and require full compliance, security, and performance. However, it comes with some challenges. Its pricing is subscription-based and is higher than that of other ETL tools.
Organizations must budget for both Snowflake usage and Informatica licensing to use it. It is complex to use and has some migration constraints that require aligning schemas for both the source and destination. These limitations slow down its use. Its full push-down optimization only works via open database connectivity (ODBC), so additional drivers are required.
6. dbt (Data build tool)
Best for: Analytics team focusing on transformation within the Snowflake environment.
dbt is an ELT framework built explicitly for transformation purposes rather than extraction or loading. It allows teams to transform raw data loaded into Snowflake using tools like Fivetran, Talend, or Matillion using a modular, SQL-based workflow. Transformations are executed directly within the data warehouse using Snowflake’s compute engine.
This framework allows users to write transformations as version-controlled code, create modular and reusable models, add automated tests to ensure data reliability, and automatically generate documentation that improves transparency for downstream analytics. It is also highly collaborative due to its CI/CD workflow and scalability.
dbt is an essential tool for a data engineering and analytics team that already has a reliable data pipeline and wants to focus only on maintainable, testable, and well-documented transformations. It is helpful for organizations following the modern data stack, where various specialized tools manage ingestion, transformation, and orchestration separately.
This platform is available in two forms: the open-source “dbt Core”, which is free to use, and the managed “dbt Cloud”, which includes features like job scheduling, collaboration tools, logging, and an IDE. For the cloud version, organizations need to pay $100 per user per month. However, dbt can only handle transformation in the ELT process and cannot extract or load data. To extract and load data, teams need to connect dbt with other ingestion tools and orchestration platforms to create a full-scale pipeline.
What to consider when comparing Snowflake ETL tools
The performance of Snowflake depends heavily on the data pipelines that feed it. Choosing the right ETL or ELT processes requires balancing automation, scalability, and cost effectiveness according to the organization's specific priorities. In addition to connector numbers or setup speed, you should also focus on long-term goals such as workload patterns, latency requirements, transformation strategies, and data governance needs.
When choosing a Snowflake ETL tool, consider:
- Pricing model: Tools have different pricing models, e.g., Fivetran charges based on usage, Matillion charges based on computing credits, Integrate charges on a connector-based fee, or some allow flat-fee subscriptions. You can align the pricing according to your data volume, update frequency, and other factors to avoid huge costs.
- Batch vs. streaming support: Some tools support continuous or event-driven pipelines, while others only handle scheduled batch jobs. Choose the one that best suits your needs.
- Real-time latency: Evaluate how quickly data is available in Snowflake; this can range from near-real-time syncs to hour-long delays.
- Transformation staging options: Consider whether to perform the transformations externally before loading or inside Snowflake using its compute.
Build a reliable pipeline with Fivetran
There is no universal "best" platform. Some excel at real-time data ingestion, while others prioritize flexibility or complex data transformation tasks. That’s why it’s essential to make sure a tool’s capabilities align with your team’s needs. Before choosing a tool, ask yourself:
- Do we need real-time ingestion or will batch updates suffice?
- Is the transformation phase best staged before or inside Snowflake?
- Do we prioritize low-code automation or full customization?
- What are our compliance and governance requirements?
- How much engineering overhead can we support?
After a thorough pre-purchase evaluation and carefully considering your team's data processing needs, you'll find the right tool to provide the foundation for analytics and decision-making.
[CTA_MODULE]
Frequently asked questions (FAQs)
What is Snowflake?
Snowflake is a cloud-based data warehouse that separates the compute environment from the storage and supports high-performance analytics, even as datasets grow. It can handle structured, semi-structured, and unstructured data for various requirements.
What is reverse ETL?
Reverse ETL is a process that moves data directly from a warehouse to general-purpose platforms like marketing tools and CRM. It allows teams to use data stored in the data lake for real-time use cases and reporting purposes.
How does ETL work in Snowflake?
ETL in Snowflake works by extracting data from sources such as APIs, SaaS applications, and databases, transforming it, and then loading it into Snowflake tables. These pipelines can work in batch or streaming mode.
Can Snowflake handle real-time data ingestion?
Yes, Snowflake handles both batch and real-time streaming data using third-party tools, such as Fivetran. Its speed heavily depends on the used tool, with some allowing real-time updates, while others can sync data on a minute-by-minute, hourly, or daily basis.
Does Snowflake have its own built-in ETL tools?
No, Snowflake does not provide any native ETL tools. However, it works with many third-party ETL or ELT platforms. Teams can use these tools to connect data sources while relying solely on Snowflake’s built-in features to handle the data pipeline.
Can I use Python for ETL with Snowflake?
Yes, you can create your custom ETL pipeline in Python using Snowflake’s built-in Python connector. This provides flexibility but requires extensive coding and maintenance.
Related posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







