How to build a data pipeline: A step-by-step guide


According to a study from Cornell University, 33% of faults with data pipelines occur due to incorrect data types. If you don’t know how to build a data pipeline, even minor problems can translate into your pipelines breaking.
This guide details the 6 core components of building a data pipeline, from source ingestion to monitoring, so you can design scalable, reliable systems.
How to build a data pipeline
This section will focus on 6 steps to build a data pipeline, based on its corresponding core components.
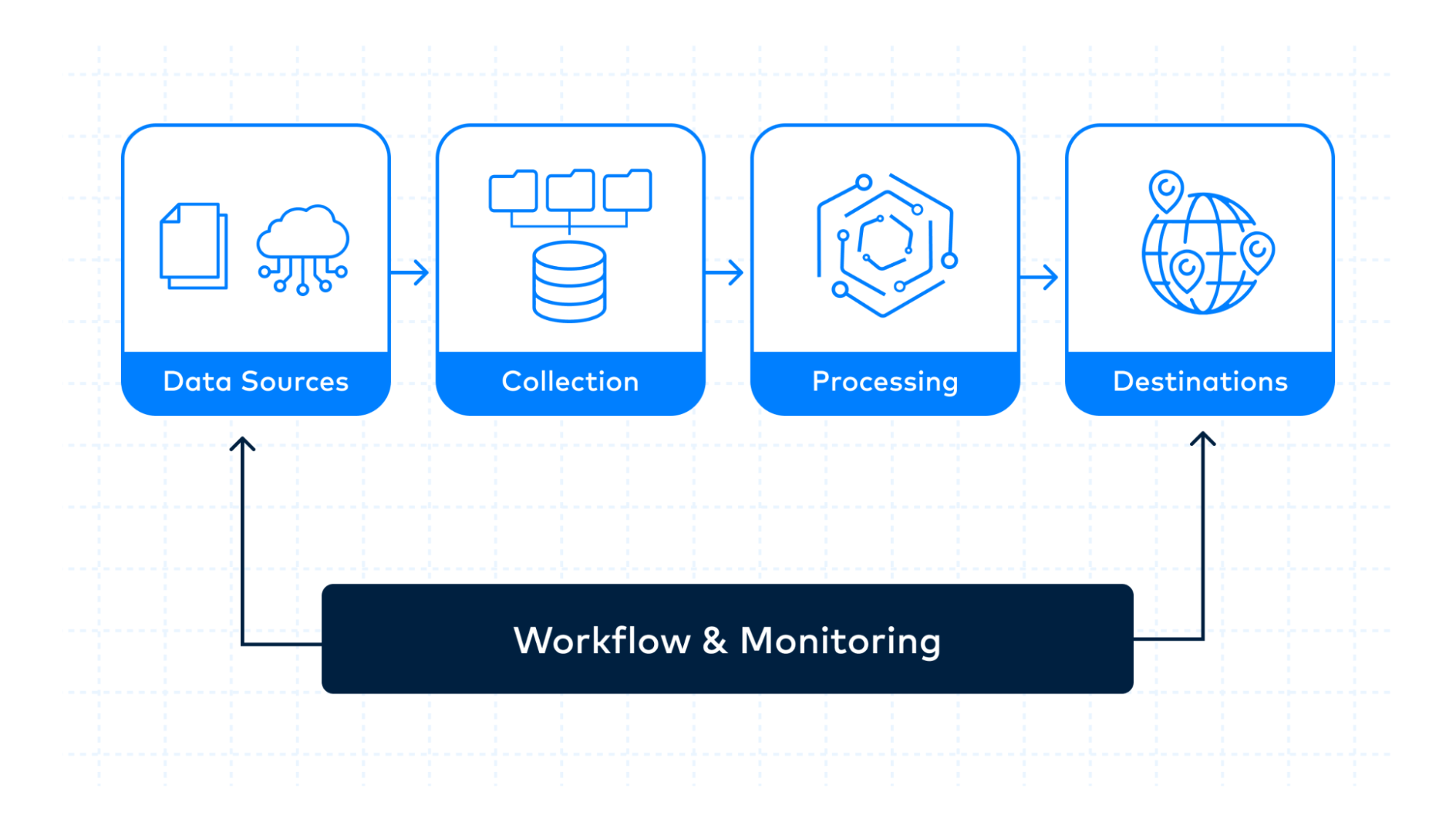
1. Identify and organize your data sources
The first step in working with data is knowing where it comes from.
Any system or software that generates or collects data for your organization is a data source. Make sure you’re aware of all of your sources, whether they be internal platforms for work and communication or customer-facing software.
Here are some common categories and examples of data sources:
Data sources can generally be divided into three types based on where they originate from:
- Analytics data: Information about user or market behavior.
- Third-party data: Useful data from outside your company.
- Transactional data: Individual data about sales, payments, or products.
Most businesses have hundreds, even thousands, of data sources. A flexible and robust data pipeline is only possible if these sources are correctly managed and collected.
Below are instructions you can implement to have a clean, detailed data inventory:
2. Collecting your data
After taking an inventory of your data sources, the next step is to pull data from those sources into your data pipeline. This process is called data collection or data ingestion.
The ingestion process also handles how data sources are combined and prepared for processing.
Depending on your platform, you can build a pipeline that supports batch and streaming pipelines, or even both, if your analytics and business needs demand it. Here are some examples to help you understand the differences:
- Batch ingestion: An online store that works nightly to process all orders from the last 24 hours. It then makes sales and inventory reports for the next business day.
- Stream ingestion: A ride-sharing app streams real-time GPS data from both the customer and rider to calculate an estimated time of arrival.
Let’s look at some other steps to perform for proper data ingestion:
3. Processing your data
Once data is in your pipeline, you need to process and transform it to make it more useful to analysts. This step, called data integration, ensures that data is complete, accurate, and ready to be used.
There are two main approaches for data integration: Extract, Transform, Load (ETL), and Extract, Load, Transform (ELT).
Your choice of ETL vs ELT shapes the architecture of your data pipeline (more on this in a later section).
Choosing between ETL and ELT isn’t the only step in data integration. After you’ve chosen your architecture, you still need to validate, clean, standardize, and transform your data.
Below is more detail on these points.
4. Choosing a destination
A destination is a centralized location that stores all the processed data. It affects everything from compatibility to cost to disaster recovery, making choosing a destination an especially important part of the pipelining process.
Though choosing a specific data destination is grueling, the first decision you need to make is whether to use a data warehouse, a data lake, or a data lakehouse.
Bear in mind, the choice between these three isn’t necessary. If you think the data coming through your pipeline is more complex than just one of these destination types, you can split your data into multiple streams. Each stream goes to the type of destination you want.
Data can also flow directly into an API, which can be useful in some instances, such as fraud detection, push notifications, or live personalization. However, it's almost always better to store data in a persistent destination before it’s sent elsewhere.
5. Workflow
The workflow defines the order in which tasks run and how they depend on one another.
Here’s an example of an ELT workflow:
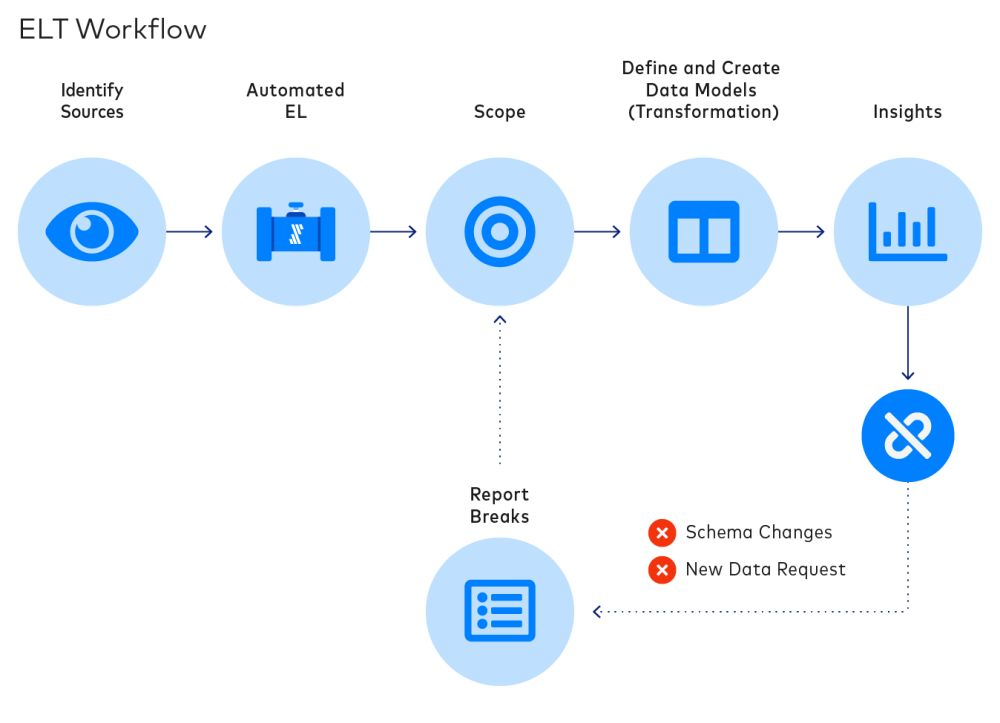
Workflows often encompass both technical and business dependencies.
- Technical dependency: A technical process or task that must be done before the next step in the pipeline can start, like checking the data before changing it.
- Business dependency: A dependency driven by business rules or processes, such as checking sales data with finance records before making reports.
Developers can match these technical or business dependencies by setting up matching workflows.
6. Monitoring and testing your pipeline
Since data pipelines are complex systems with multiple components, they must be monitored to ensure smooth performance and quick error correction.
The following are some of the components that are a must for effective monitoring:
- System health checks: Watching for performance issues like network congestion, offline sources, or slow queries.
- Data quality checks: Catching anomalies in data like missing values, schema changes, or duplicate records.
- Alerts and logging: Notifying engineering teams of any problems in real-time while also saving logs for troubleshooting.
With safeguards in place, engineering teams can fix problems as soon as they arise. Good monitoring not only prevents errors from spreading but also ensures that your organization’s analytics and business decisions remain accurate and trustworthy.
Wondering how to manage the costs associated with data pipelines?
Data pipeline architecture
The architecture of your data pipeline dictates how the processes mentioned in the previous section interact with one another. As noted, one of the most significant factors influencing your data pipeline architecture is the choice between ETL and ELT.
Here’s an overview of the differences:
ETL
If you choose ETL, your data will be transformed before it’s loaded into storage.
Here’s an illustration to help better understand the structure of an ETL pipeline:
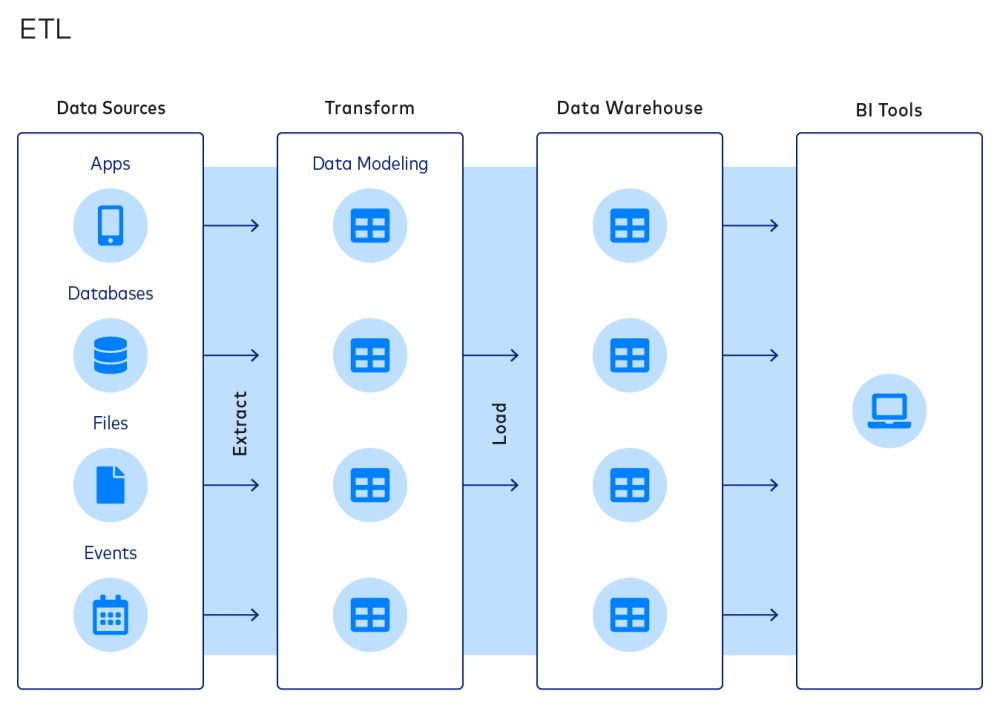
Strengths of ETL include:
- Faster analysis: Since the data is transformed and structured before being loaded, the data queries are handled more efficiently, allowing for quicker analysis.
- Compliance: Organizations can comply with privacy regulations by masking and encrypting data before it’s loaded into storage.
- Cloud and on-premise environments: ETL can be implemented in data pipelines that rely on cloud-based and on-premise systems.
Though it offers benefits, most companies are moving away from ETL.
Scaling is difficult with ETL as data sources increase, making it hard to recommend it to people with large data volumes.
It works great for smaller datasets requiring complex transformations or in-depth analyses.
ELT
As you could’ve guessed, the ELT process involves data being loaded before it is transformed.
Here’s a diagram to better illustrate the difference between ELT and ETL:
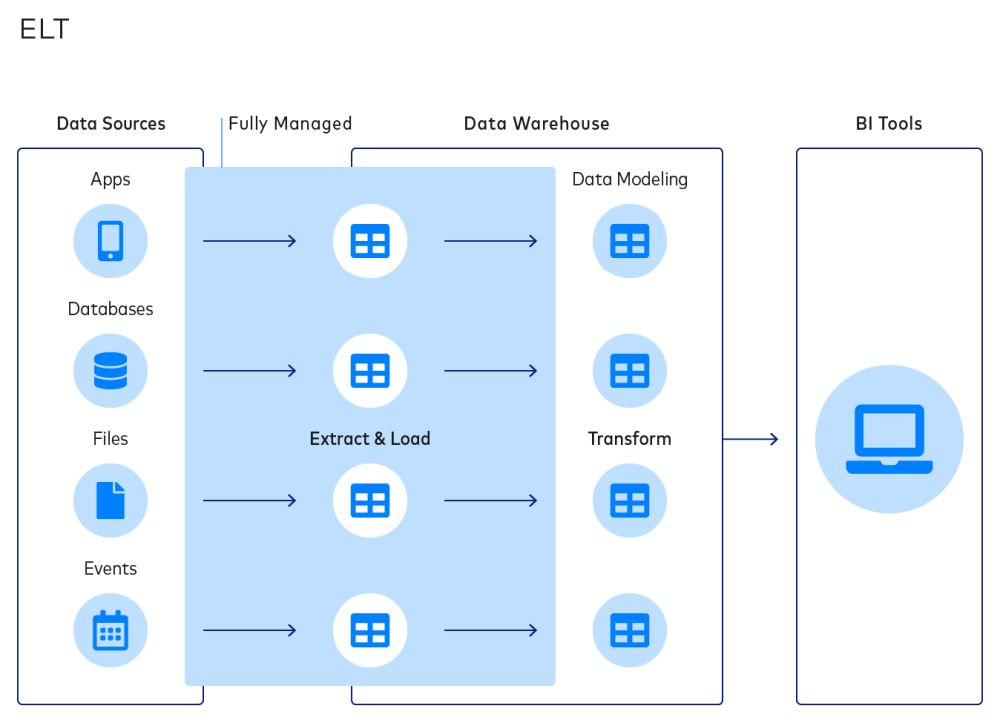
Most companies prefer ELT for the following reasons:
- Automation: ELT allows teams to standardize data models, which promotes automation and outsourcing.
- Faster loading: This framework loads data before the transformation, providing immediate access to the information.
- Flexible data format: ETL supports both structured and unstructured data, so it can ingest data in any format.
- High data availability: If you’re using tools that don’t require structured data, they can instantly collect and act on data from the data lake.
- Easy implementation: ELT can work with existing cloud services or warehouse resources, easing implementation roadblocks and saving money.
- Scalability: Since most ELT pipelines are cloud-based, companies can easily scale their data management systems using software solutions.
ELT has the downside of being slower in analyzing large volumes of data, as the transformations are applied after the data is loaded.
However, feature-rich, fully managed ETL solutions like Fivetran help speed up transformations and the entire pipeline process by completely automating them.
Technical considerations for data pipeline architecture
This section will discuss the five vital factors that affect your data pipelines.
Automation
Writing scripts manually can consume a lot of company resources and engineering effort. Automated pipelines remove this burden by continuously moving data from source to destination on a designated schedule.
Automated pipelines handle workflows by nature. Here’s an overview of how they apply to the rest of the major steps in making a data pipeline:
- Extraction and loading: Pulling data from sources and loading it into the warehouse without manual intervention.
- Transformations: Applying rules to clean, enrich, and standardize data so it’s immediately useful for analysis.
- Monitoring and alerts: Instantly flag errors or anomalies so engineers can act before they affect downstream analytics.
With automation, teams can focus on improving data pipelines instead of just maintaining them. This saves your organization costs on engineering talent and helps scale your company by enabling growth.
Performance
A data pipeline fails its purpose if it interferes with core business processes when running or if the data it presents is too stale to be useful.
Organizations utilize technologies like change data capture (CDC) to make sure that relevant data is delivered on time, improving performance. There are various techniques that help boost performance, such as:
- Parallelization and distribution: Running tasks in parallel across multiple nodes to handle larger data volumes.
- Buffering and compartmentalization: Isolating sensitive or resource-heavy operations to prevent bottlenecks.
- Scalability: designing an architecture that can grow as data demands increase.
Make sure that the pipelines you set up are quick and responsive enough to be more of a valuable tool than a hassle to maintain.
Reliability
An unreliable data pipeline hinders analysis and drives up business costs. Several problems cause unreliability, such as:
An automated, fully managed data pipeline like Fivetran removes these grievances by automating data syncs, adapting to schema changes, and ensuring reliable, low-maintenance pipelines.
Scalability
Scalable data pipelines are vital for business growth. As your company develops, you want pipelines that can handle more data sources, higher data volumes, and complex performance requirements.
Expecting engineers to build and maintain connectors for each new data source constantly is time-consuming and frustrating. It also leads to slower insights. For growing businesses, it’s best to design a system that programmatically controls your data pipeline.
Security
Security and compliance are key to storing sensitive customer, client, and business data. Organizations must comply with regulatory standards to ensure no personal information is stored or exposed within their data pipelines.
Many organizations use ETL for this, allowing them to encrypt data before its storage. However, an ELT pipeline with process isolation and robust security features, such as data encryption in transit and rest and the blocking or hashing of sensitive data before storage, can ensure compliance while providing superior performance.
Buying instead of building
Designing, building, and implementing a data pipeline is a complex, labor-intensive, and expensive process. Engineers must build the source code for every component and then design relationships between them without errors. Moreover, a single change can necessitate rebuilding the entire pipeline.
That is why most organizations choose to buy instead of build.
[CTA_MODULE]
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







