What is Fivetran?


Fivetran is a modern, cloud-based automated data movement platform, designed to offer organizations the ability to effortlessly extract, load and transform data between a wide range of sources and destinations.
This includes both the traditional data integration use case, in which data is moved from applications, databases and files to a central repository in order to consolidate a “single source of truth” for analytics, as well as the general capability of moving data between databases, data warehouses and data lakes to aid business operations.
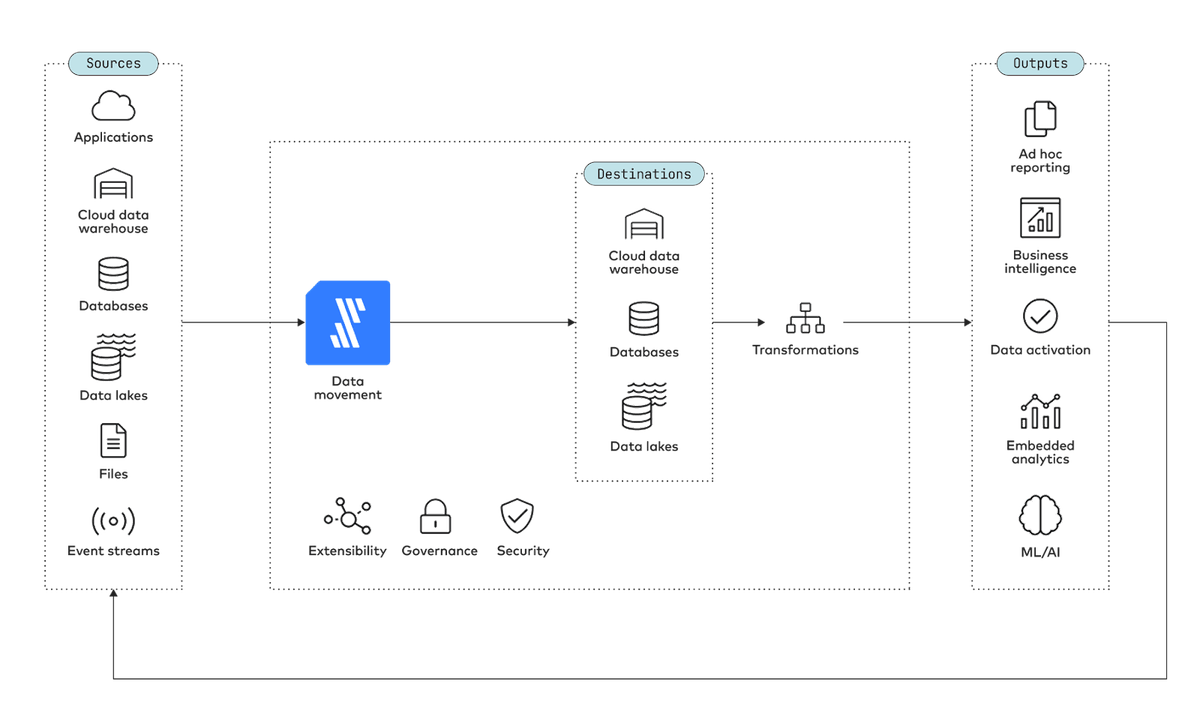
Moving data from source to destination requires a high-performance system that can be deceptively complex to engineer. Considerations include properly scoping and scaling an environment, ensuring availability, recovering from failures and rebuilding the system in response to changing data sources and business needs. Many common data integration tools provide frameworks for solving these tasks but still demand a considerable degree of configuration and engineering work from end users.
Moreover, it is not uncommon for organizations to use dozens to hundreds of different applications, tools and operational systems that produce data, each of which leaves behind valuable digital clues.
.png)
These challenges impose significant costs in time, labor and money on organizations that attempt to move data using any kind of bespoke, high-configuration solution. Building an efficient, reliable and scalable data operations infrastructure from scratch, or even with the assistance of a framework, is an exercise in frustration and lost opportunities.
By contrast, an automated data movement solution that works off the shelf obviates the need for an organization to build such a solution in-house.
Automation, reliability and scalability
From the perspective of the end user, the ideal data movement workflow should consist of little more than:
- Selecting connectors for data sources from a menu
- Supplying credentials
- Specifying a schedule
- Pressing a button to begin execution
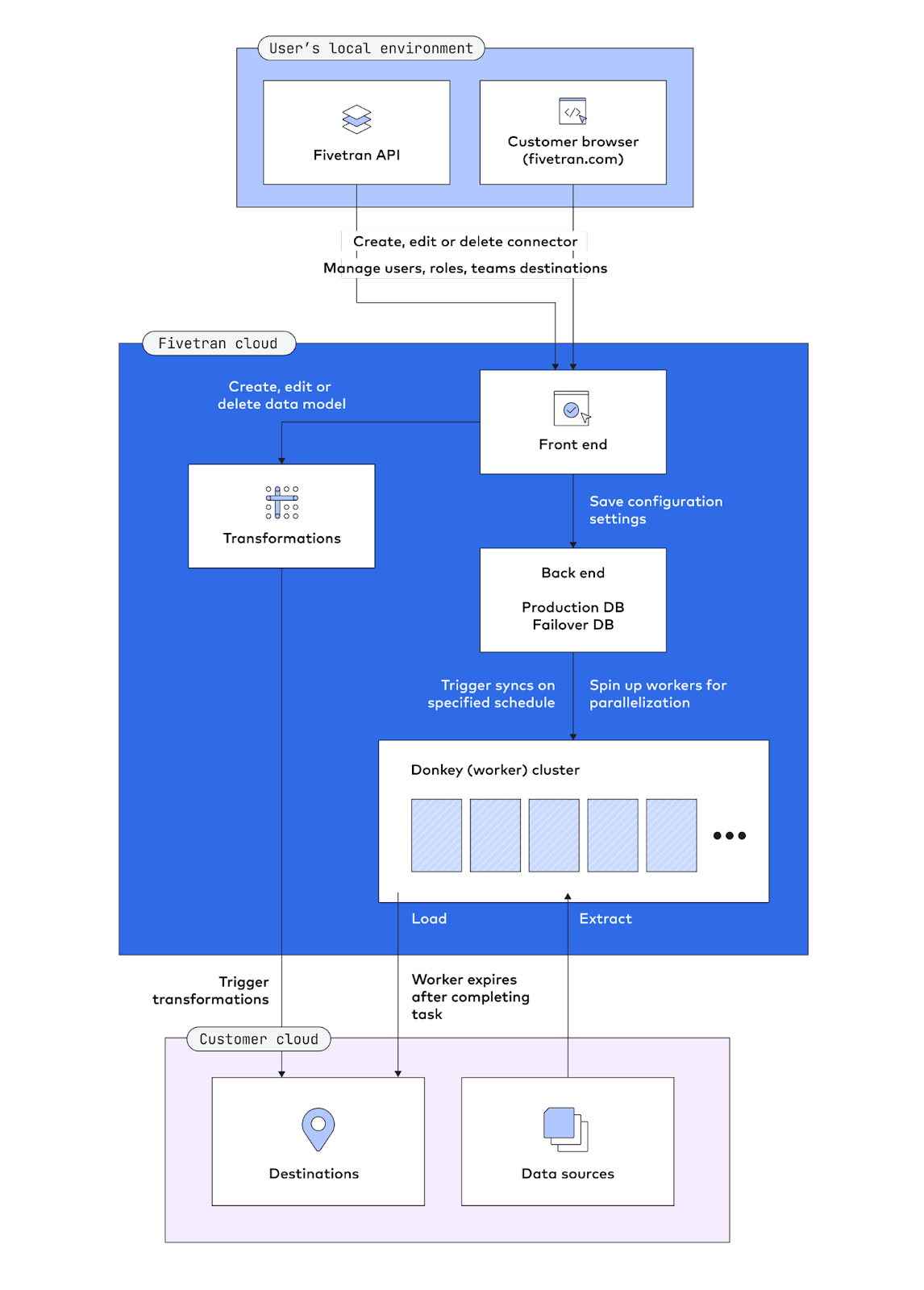
The simplicity of this workflow belies considerable complexity under the hood. The Fivetran architecture is strictly divided between a user’s local environment, Fivetran cloud and customer cloud. This division is essential for ensuring both security and performance. In terms of security, the strict separations between the front end, back end and customer cloud ensure there are no ways sensitive data can be exposed through the front end. For the sake of performance, as a cloud-native tool, Fivetran makes extensive use of on-demand parallelization.
The following architectural diagram lays out the standard cloud-based Fivetran approach to automated data movement:
Note that for organizations with security requirements that limit the ability to use cloud-based SaaS solutions, Fivetran also offers hybrid and on-premises architectures.
A typical workflow follows these steps:
- The user accesses the Fivetran front end through the Fivetran.com dashboard or API.
- The user creates and configures connectors.
- The user’s choices are recorded in the Fivetran production database.
- Based on the settings saved in the production database, the Fivetran backend spawns a number of workers on a schedule.
- Each worker extracts and loads data, with some light processing. Workers expire when they are no longer needed.
- Transformations to produce analyst-ready data models are separately triggered and run on the destination. Fivetran data models are produced through our integration with dbt™ to power transformations.
In order to ensure that the workflow described above operates smoothly and reliably, Fivetran is also designed with a number of considerations that aren’t easily captured in an architectural diagram.
- Incremental updates ensure timely updates and minimal disruption to source systems. Instead of extracting and loading the entire data source with every sync, Fivetran detects new or modified records and reproduces the changes at the destination. Full syncs are only used for an initial sync or to fix serious data integrity issues such as corrupted records. The main mechanism by which Fivetran achieves incremental updates is change data capture (CDC).
- Idempotence is the ability of a data connector to easily recover from failed syncs. In the context of data movement, idempotence ensures that if you apply the same data to a destination multiple times, you will get the same result. Without idempotence, a failed sync means an engineer must sleuth out which records were and weren’t synced and design a custom recovery procedure to remove duplicate records. With idempotence, the data connector can simply replay any data that might not have made it to the destination. If a record is already present, the replay has no effect; otherwise, the record is added.
- Schema drift handling involves accurately representing data even as sources change. Schema drift handling also involves data type detection and coercion, balancing accurate replication and preservation of data with the reliable functioning of data connectors. Fivetran mainly addresses this problem with live updating, in which data is perfectly reproduced between source and destination.
- Ensuring pipeline and network performance requires minimizing latency and performance bottlenecks. Fivetran accomplishes this through algorithmic optimization, parallelization, pipelining and buffering.
Why Fivetran is a platform, not just a pipeline
Fivetran is more than a point solution that solves the single, discrete problem of centralizing data for analytics. Longer term, organizations must also consider democratizing access to data and finding ways to monetize data. Mindful of these needs, Fivetran provides security, governance and extensibility features.
Security features are must-haves to ensure regulatory compliance, manage brand risk, protect internal operations and intellectual property, and safeguard customer information or other business critical data in an ethical manner as it is moved around. When considering platform security, common features include flexible deployment and secure networking options, security compliance certifications for SaaS platforms, end-to-end encryption data protection and process isolation.
In a similar vein, data governance is essential for enabling organizations to know, access and protect their data. Data governance features include easy integration with data catalogs, graphical exposure of data model lineage, metadata capture and other auditing tools.
Finally, extensibility features enable an organization to programmatically control a growing ecosystem of data management tools and embed data assets into products. As data needs grow in scale and complexity over time, organizations will need the ability to manage users at scale, integrate with other data operations technologies and construct custom processes and workflows that depend on data.
[CTA_MODULE]
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







