Build vs. buy data pipelines: Costs to consider

There's a good chance your company is among the 150,000+ global customers of Salesforce. Chances are also strong that you use services like Marketo, Zendesk, Jira and Zuora to gain a comprehensive view of your business operations.
Experts estimate that more than 80% of business intelligence efforts fail, in part because of outdated technology, clunky processes and inaccessibility. The path to failure can be expensive, too, and the goal of this article is to present some of the costs in money, time and anguish associated with building a bespoke business intelligence solution.
In periods of market uncertainty, why not do more with less?
[CTA_MODULE]
The setup costs of buying vs. building data pipelines
The first expense you'll need to consider is the initial cost of getting your data flowing from your data sources into your destination of choice. Building might be a viable option if you’re looking to transfer data from a single source to a data destination. However, most of the time, operational data sits in different sources, and organizations often need to pull that data together to gain a comprehensive view of the company.
For example, let’s assume your company wants to build a data pipeline to pull financial, customer and marketing from NetSuite, Salesforce and Marketo to Google’s BigQuery data warehouse for analytics. A typical task breakdown consists of:
- Assembling your team – database admins, data engineers, and other data professionals
- Analyzing the source/destination requirements and system architecture
- If you build your solution, you will have to write software to pull data from different sources. By contrast, if you buy a solution, you will have to choose a third-party data integration tool
- Testing the data integration
One of the most resource-intensive parts of the project would be step three. Let's analyze the cost in the following build vs. buy scenarios.
Build
According to Wakefield Research’s survey of hundreds of data analytics and business leaders, it typically costs around $520,000 a year for a team of data engineers to build and maintain data pipelines. Data engineers spend about 44 percent of their time building and maintaining data pipelines, taking their attention away from higher-value analytics and engineering tasks.
[CTA_MODULE]
In practice, this means project turnaround times measured in weeks or months for individual pipelines. Greg Roodt, head of data platforms at Canva, notes that their data engineers needed three months to create, test and deploy custom integrations from Braze, AppsFlyer and Apple App Store. "They are excellent engineers," Greg says. "But it took so long because they had to slog through confusing and outdated API documentation, set up the infrastructure in AWS, create a monitoring mechanism and make sure it all worked as intended." Likewise, Ashley Van Name, general manager of data engineering at JetBlue, observes that it regularly took “engineers weeks, if not months, to fully build, test and deploy” their old pipelines.
Considering the number of data sources an organization might use, plus the complexity of building data connectors, merging different data sources together and the cost it takes to train new data engineer talent, this cost can grow exponentially.

Building a data pipeline is a substantial investment, especially considering that large IT projects routinely run 45 percent over budget.
Buy
With a fully managed data pipeline solution, the most resource-intensive part of the process — writing code to move data — is taken care of. You only determine what to buy and then configure it to suit your needs.
Data integration solutions like Fivetran use a consumption-based pricing model, where your cost is based on your use. For example, with 1 million monthly active rows on the enterprise plan, you get an estimated cost of $1,000 per month, which comes with access to over 700 data connectors — a fraction of the cost it takes to build data pipelines manually.
Anand Bhatt, head of business analytics at Australian fashion boutique Princess Polly, found that switching to Fivetran saved the equivalent of hiring one full-time data engineer. Some companies experienced even better results. Leon Van Dyk, head of data and decisioning at Kuda, Nigeria's pioneer digital bank, said adopting a scalable solution like Fivetran saved the work of five data engineers, allowing them to focus on more important parts of the business.
Apart from cost savings in talent, you benefit from fewer upfront costs to start your project and less risk that the development cost will skyrocket due to unaccounted-for complexity and bugs. Also, you can often try out the product through free trials and demos at no risk to get a good idea of what the annual spend might look like before making a commitment.
The maintenance costs of buying vs. building data pipelines
Data pipelines must be rebuilt whenever upstream data schemas change at the source or a business needs new downstream data models. Maintenance imposes an ongoing burden that forces your data engineers to frequently revisit old code written by other people and distracts them from higher-value work. This problem scales as data sources are added.
Build
When you build your data pipeline, you also own all of the maintenance – bug resolution, upgrades and security. As the Wakefield research shows, most data leaders (80 percent) have to rebuild data pipelines after deployment. Some 39 percent of data leaders report that they constantly rebuild data pipelines, and this problem is especially acute at younger companies, of which 52% report constantly rebuilding pipelines.
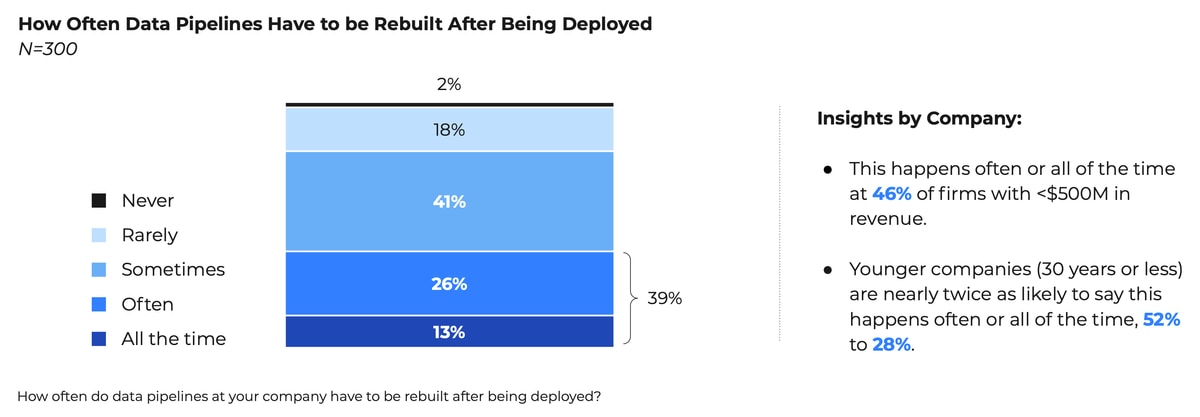
Earlier, we established that a typical cost for building and maintaining data pipelines is $520,000. The time commitment required for maintenance presents a tremendous opportunity cost that far exceeds the nominal monetary cost of building and maintaining data pipelines.
Buy
Fully managed data pipeline solutions factor in regular maintenance costs, so data teams don’t have to worry about ongoing overhead maintenance costs. When you can relieve yourself of the pressure of maintenance, data teams can focus on higher value activities, such as:
- Building internal apps and automation that leverage analytics data
- Working on new data models, predictive models, dashboards and reports
- Exploring and testing new data tools
- Advising key decision-makers within the enterprise
- Training the rest of the company in data literacy
Also, most engineers dread maintenance work. Guli Zhu, head of marketing analytics at Square, had this to say after switching to Fivetran: "Our data engineers and analysts are more excited about building new things. When you’re able to relieve yourself of ongoing maintenance overhead of data plumbing, you can be so much more impactful to the organization."
Opting for an automated data pipeline solution reduces maintenance cost significantly. For example, Oldcastle saved over $360,000 in immediate engineering costs by using Fivetran, and gained an ROI to the tune of $25 million through cost savings, improved margins and higher sales. A notable amount for companies looking to save money and thrive amid uncertain market conditions.
The opportunity costs of buying vs. building data pipelines
When making a build vs. buy decision, consider the best use of your engineering team's time and assign resources where your top talent can have the highest impact. For instance, if you allocate existing resources to building and maintaining data pipelines, where are you taking resources away from, and what will you have to give up?
Build
If you want to keep your analysts, engineers and managers happy, you should consider the following problems associated with building your own connectors or manual reporting:
- Diversion from other software engineering, data science or analytics duties — this is a very common irritant among new data scientists at understaffed organizations and leads to turnover
- Frustration and exhaustion from the complexity of maintaining data integrity, particularly by persons lacking the appropriate training
- Continually increasing complexity (and downtime) as additional sources of data are added
- Misguided decisions caused by lags between requests for business intelligence and delivery of actionable insights — insights that might be stale by the time they arrive
If your data engineering team spends 22 weeks per year building and maintaining data pipelines, you're pulling them away from other core projects that generate value for the business. You are also entangling them in an architecturally complex undertaking involving many moving parts and technical considerations.
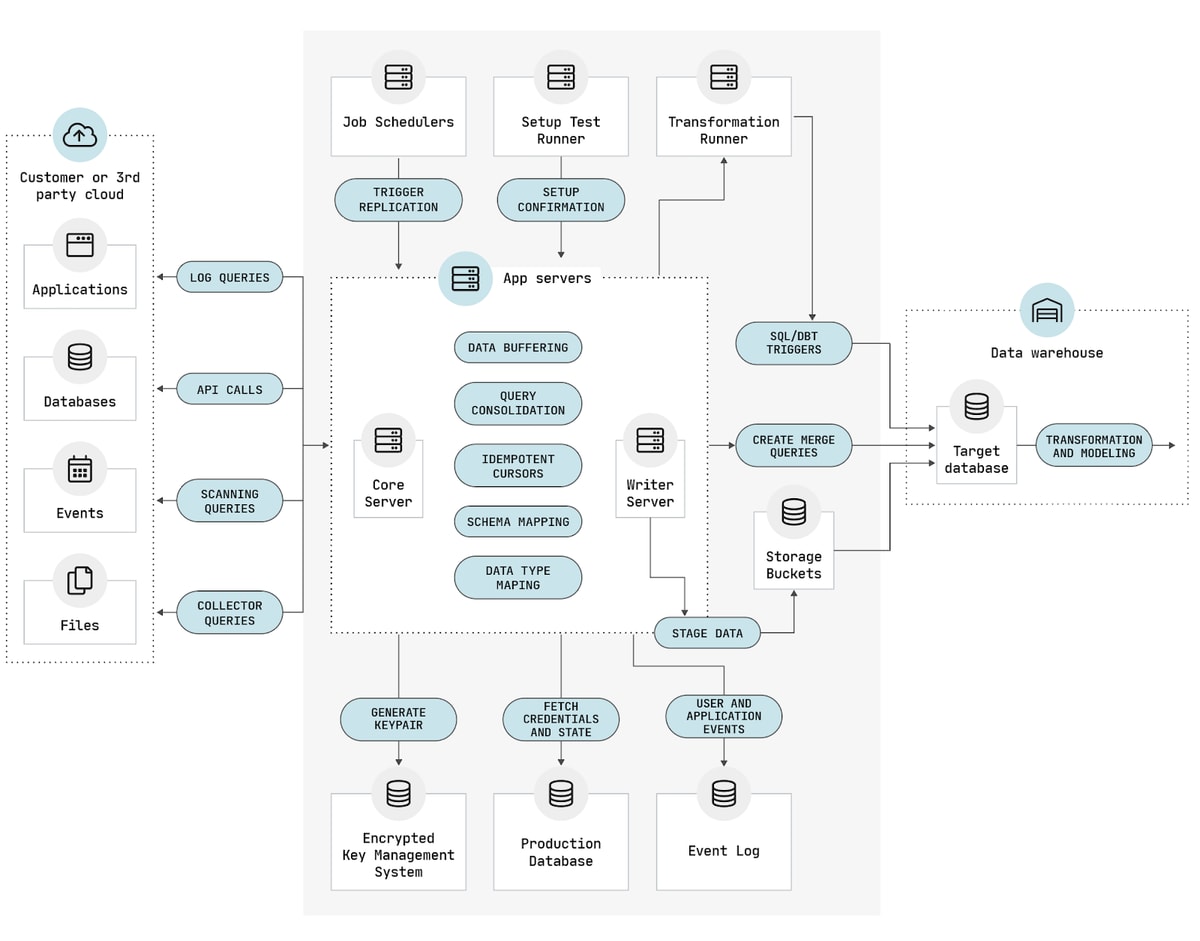
According to the Wakefield report, 97 percent of data and analytics leaders say business outcomes would improve if their teams could spend less time on manual pipeline management and 71 percent of data leaders characterize manual oversight of data pipelines as wasted time.
Buy
If your company aims to quickly utilize data to achieve business objectives, buying a fully managed data pipeline solution reduces the time spent on building a data pipeline, allowing your team to be more productive.
By investing in an off-the-shelf data pipeline provider like Fivetran, data loading would no longer require manual backfill and thousands of lines of Python code. For example, you can schedule data transfers from different sources to your BigQuery or Snowflake warehouse with just a few clicks and a matter of minutes.

Label Insight, which aggregates consumer goods data, saw a time savings of over 140 hours every week and an estimated 200 percent ROI by switching to Fivetran. Similarly, Carlos Mareco, director of data engineering and business intelligence at World Fuel Services reported 200 monthly engineering hours saved by eliminating the need to create, manage and update data connectors manually.
Engineers generally like to build things that are interesting or innovative rather than rehashes of solved problems. Igor Chtivelband, co-founder and VP of data and CRM at Billie.io says "As a data engineer, I like to build things, but after trying out Fivetran's data pipelines, if I had to choose between build or buy again, I would always choose buy."
Finding the right data pipeline solution for your business
The division of labor is directly responsible for humanity’s greatest commercial, scientific and technological accomplishments.
But many of the data engineering skills necessary to construct data pipelines are not formally taught in academic programs, boot camps, or training programs. It is scarce human capital that is often developed the hard and expensive way — through experience, trial and error. People in adjacent roles — analysts, software engineers and data scientists — often find themselves performing these duties poorly and against their druthers.
Given the value of labor specialization, there’s no reason for you and the thousands of other companies using Salesforce, Marketo and other software to build your own API connectors when an off-the-shelf solution exists. Fivetran has already scaled the learning curve for you so that you can spend your time and energy building your core product and making sense of your operations.
Building an in-house solution gives you total flexibility over the design of your data pipeline, but it comes with increased costs and complexity. While buying an off-the-shelf solution may require sacrificing some bespoke configurations, it is cost-effective and saves time and frees you to explore multiple options. You will also benefit from the expertise and ongoing support of the vendor.
Fivetran can save you setup, maintenance and time costs. From solo data analysts to global enterprise companies, Fivetran’s pricing plan covers everyone. With over 700 connectors, Fivetran can securely connect to all the databases and apps that drive your business, centralize your data in minutes and accelerate your analytics within a five-minute setup. Sign up for your free trial today.
[CTA_MODULE]
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







