Why Fivetran beats iPaaS for faster, simpler data integration


Over the past two decades, SaaS adoption has exploded — today, companies rely on 100+ applications on average, and large enterprises often manage thousands. For years, iPaaS tools like MuleSoft, Boomi, Workato, and Zapier were the go-to for connecting them. But these point-to-point solutions weren’t built to scale. The modern data stack — automated pipelines with cloud data warehouses and data lakes — offers a better way.

Why point-to-point integration falls short
Although point-to-point integrations may be convenient and useful on an ad hoc basis, organizations that rely on point-to-point iPaaS struggle with the following shortcomings:
- Trigger-based workflows are rigid: Generally, iPaaS workflows, such as updates to fields, must be triggered by events rather than change detection. This means data can’t be sent between systems until that trigger criterion has been met.
- Transformations and data modeling can become complex and maintenance-intensive: Transformation logic has to be housed within the individual iPaaS workflow components, creating additional complexities and dependencies. More complicated functionality may need to be implemented through custom SQL. This means that data integrations are performed piecemeal, workflows are highly technical, and workflows require ongoing maintenance. Each additional dependency, whether from additional sources or additional stages in a workflow, makes identifying, debugging, and fixing errors very challenging.
- Brittle integrations can’t cope with changing data: Data in SaaS tools is constantly being updated and changed as individual users update fields daily, so it’s only a matter of time before workflows break. Maintaining this at scale requires individual workflow updates, which become increasingly complicated as workflow counts grow. Building a new workflow means starting over entirely from scratch and implementing code and logic anew.
- iPaaS setups are costly and don’t scale: iPaaS implementations may start in the six figures for initial implementations, yet are not typically optimized for moving volume at scale (i.e., by the millions or billions of rows).
The upshot is that architectures that rely on iPaaS create considerable friction and complexity for business stakeholders, turning the data team into a cost center and source of aggravation instead of a center for insight, innovation, and reasonable time-to-value.
How Fivetran is different
Fivetran was built for the modern data stack, not for patching together one-off workflows. With fully managed, automated ELT pipelines, Fivetran helps enterprises eliminate the friction of point-to-point iPaaS.
- Centralized, automated pipelines: Move data from 700+ SaaS apps, databases, ERP systems, and files into a warehouse or lake for a single source of truth.
- Schema resilience: Fivetran automatically adapts to schema changes, so pipelines don’t break.
- Enterprise-grade scale and compliance: Designed for billions of rows and strict business/regulatory requirements.
- Faster time-to-value: Teams spend less time fixing workflows and more time driving analytics, AI, and business outcomes.
- Reverse ETL with Fivetran Activations: Push trusted warehouse data back into operational tools so every team has the latest insights.
A centralized data integration approach establishes a declarative model where organizations can simply define their data and point it toward an end system for data activation. Instead of setting up an unmanageable roster of individual point-to-point integrations, you simply have to define data and map it to the appropriate fields in the end destination.
The declarative model establishes a hub-and-spoke approach where everything flows in and out of the data warehouse — thus ensuring all operational systems are in sync with one another and powered by a single source of truth.
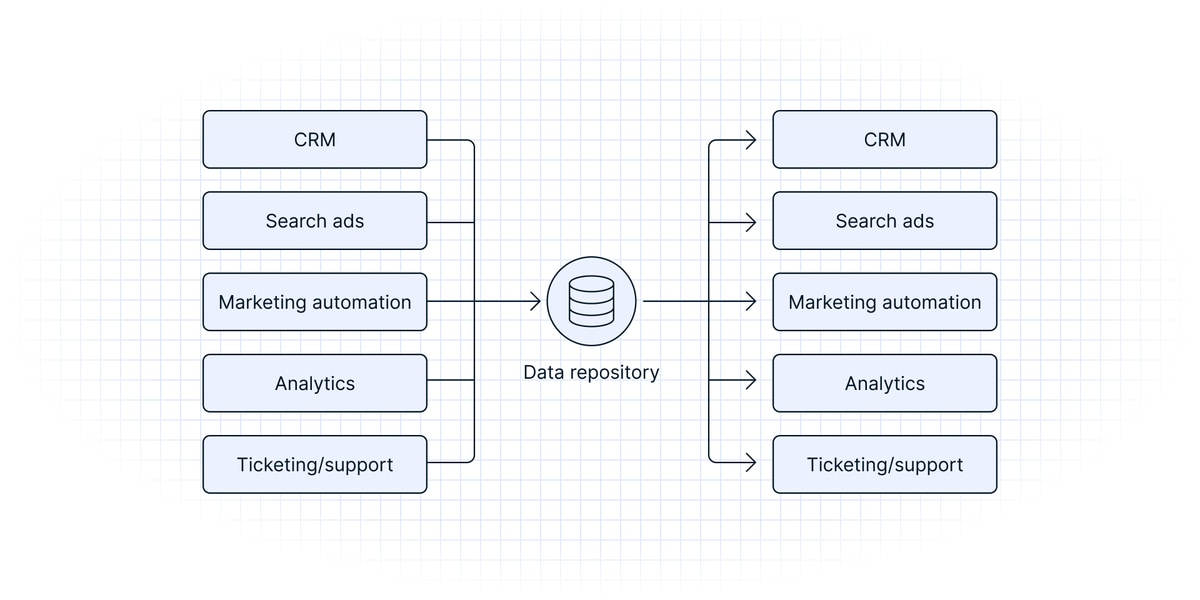
Centralized data integration beats point-to-point
Rebuilding point-to-point integrations around a central data repository vastly simplifies your data architecture and workflows (especially transformations) by consolidating a huge number of point-to-point pipelines into a much smaller number of one-to-many pipelines. You can reuse the same models to sync data to your operational tools, and you don’t have to start from scratch every time you want to build a new data pipeline.
Instead of managing various dependencies, if/then statements, trigger clauses, and transformation jobs, with Fivetran, you simply define what data you want to send to your end system. This is a lasting change enabled by continued technological development, and not just a fad. There is absolutely no reason to maintain workflows with dozens of steps when simpler integrations and transformations offer the same capabilities with far less expense and complexity.
Automated data integration with reverse ETL — powered by Fivetran Activations — is the future, and companies in every industry are simplifying their architecture to take advantage of this new approach. By doing so, they ensure that stakeholders all over have access to the same core business metrics in the tools they use every day.
[CTA_MODULE]
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







