


Schemas drift when an application’s data model evolves and its columns, tables and data types change. Many approaches to data integration fail to adequately address the challenge of building and maintaining a robust and reliable data pipeline. Reliable data replication is fundamentally about faithfully preserving the original values of data and ensuring its smooth passage from source to destination, even as the source schema changes.
Net-additive data integration and live updating
Reliable data replication means avoiding pipeline breakages while ensuring that data is faithfully reproduced in the destination.
One method is net-additive data integration. The basic behavior is as follows:
- When a column or table is added to the source schema, it is added at the destination as well.
- When a column or table is renamed, it is duplicated at the destination under its new name, so that both the old version with the old name and the new version with the new name are present. The old version is subsequently no longer updated, but the new version is.
- When a column or table is removed, it is kept in the destination but no longer updated.
The chief characteristic of net-additive data integration is that columns or tables are never removed despite schema changes. This means that schema changes never lead to lost data. This preservation of old data extends to individual records, as well. Rows that are deleted at the source are soft-deleted or flagged in the destination, so that analyses that depend on old data still function.
An alternative to net-additive data integration is live updating. Here, the basic behavior is as follows:
- When a column or table is added to the source, it is added to the destination as well.
- When a column or table is renamed, it is renamed at the destination.
- When a column or table is removed, it is removed at the destination.
Live updating dispenses with the retention of old schema elements by perfectly matching the data model in the destination with the data model in the source. This extends to individual records as well. Rows that are deleted at the source are deleted at the destination.
The behaviors described above are the ideal case. Depending on whether the data source features a changelog, some behaviors may not be possible. For both net-additive data integration and live updating, the ideal behaviors concerning renamed columns and tables are only possible if the data source 1) has a changelog and 2) tracks schema changes. Otherwise, renamed columns and tables are usually recognized as a removal combined with an addition.
History mode
One downside of both net-additive and live updating data integration is that values that change, but are not deleted, are updated in both the source and destination. This means the data pipeline cannot keep track of values that change over time.
History mode is a solution to keeping track of changes to row values. History mode retains current and all previous versions of all rows in a table. A history table specifically contains “start” and “end” timestamps for every version of every value, in which the most recent version has a NULL (or equivalent) “end” timestamp. Deletions are signified when all rows with the same primary key have a known end time stamp, meaning there is no current “live” version.
Note that keeping track of changes to the schema is a different matter, and schema changes must be represented in a separate table from history tables.
History mode can be costly due to the sheer volume of data that is retained. A good practice is to selectively apply it to certain tables rather than entire schemas. It can readily coexist with either net-additive data integration or live updates, applied toward the same table.
The hierarchy of data types
Besides a change in name, columns can also change by data type. The key to accommodating a data type change is to assign a new data type that is inclusive enough to handle both old and new values in that column; that is, we should assign a supertype.
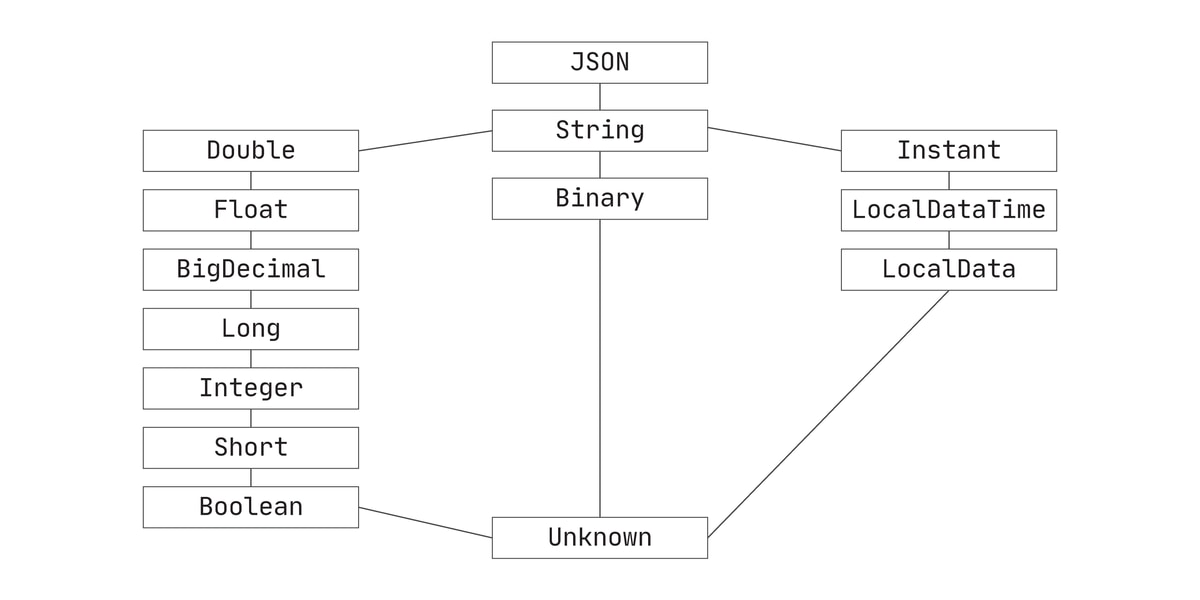
The chart above, from top to bottom, illustrates a hierarchy from the most inclusive data types to the least.
Let’s say a column consists of integers but fractional values/decimals are added to the column later on. At the destination, we will update the column’s data type to “double” instead of “integer,” because “double” can accommodate both types. Conversely, if a column consists of decimals that are converted to integers, its counterpart in the destination will stay a double because it’s more inclusive.
Reliable data replication consists of keeping a data pipeline running and ensuring faithful replication of source data in the midst of schema drift. It is more than a matter of simply copying and pasting data from one place to another, especially when large volumes of data are concerned and the ability to examine historical data is necessary. Keep the complexity of doing so in mind when you are looking for a data integration solution.
To experience reliable data replication for yourself, sign up for a free 14-day trial of Fivetran.







