It's time to ditch point-to-point data integration



Data pipelines are the hidden critical infrastructure of businesses today. Given the complexity of information and systems that even small organizations grapple with, moving data from point A to point B so teams can take action on it has taken on outsize importance. These pipelines are judged for their speed, quality and reliability. How quickly does the data get from point A to point B? Is it correct? Does it get there every single time?
In this post, we advocate for a new warehouse-centric approach to data pipelines. By using the data warehouse as a middleman, pipelines are marginally “slower,” but the benefits in quality and reliability far outweigh that change. Any time lost by passing through the warehouse en route to a destination is gained back many times over with improvements in debuggability and metric consistency.
Hear from Hightouch at this year's Modern Data Stack Conference on April 4-5, 2023. Register with the discount code MDSCON-P2P to get 20 percent off by March 15, 2023!
The history of point-to-point integrations
In the past, data transformations had to be performed "on the fly" as data moved from one place to another (whether it was a SaaS tool or a data warehouse). This meant data teams had to hard-code their data pipelines with specific transformations and make guesses about how they should model the data for downstream use cases. These transformations had to be written in code rather than SQL, leading to the development of point-to-point integrations and the creation of complex pipelines interweaving between systems.

Data teams faced two integration options: Building and maintaining in-house pipelines or using off-the-shelf iPaaS (integration platform as a service) tools. Integration platforms such as Informatica and Workato offered an out-of-the-box way to build and manage integrations from a single platform that could automatically integrate with various APIs. These platforms made creating workflows easier by providing visual UIs and drag-and-drop interfaces. They abstracted the complexity and replaced custom code and scripts with triggers, if/then statements and layers of dependencies.
[CTA_MODULE]
The challenges of point-to-point integrations
While point-to-point integrations provide low latency when transferring data between systems, they can be extremely challenging to scale and maintain. Integrations built on iPaaS tools rely heavily on event-driven workflows. This means that a trigger or key event must be defined each time data is transferred from a source to a destination (e.g., when a new lead is added to Salesforce, it is also added to Marketo). The more complex the transformation, the longer the workflow will be. iPaaS tools also have limited customization options and are designed with a one-size-fits-all approach, which can limit customization options.
In addition, point-to-point integrations are imperative, meaning that the user must instruct the workflow every step of the way, similar to writing code. Everything that happens behind the scenes must be accounted for when transferring data. If something goes wrong, it can be challenging to resync the data as data teams need to create new workflows from scratch.
Even if resources are not a concern, data engineers must consider all the maintenance required to keep data pipelines functioning correctly. A single change to a schema, data model or API can disrupt the entire data flow. While ETL processes can help automate relatively simple business processes and workflows, they become problematic when building more complex data models, which is why ELT is a better alternative.
Point-to-point integrations are limited to a single source and destination, which means teams cannot access or use all of their customer data. This single-point architecture is brittle and prone to failure. As the number of integrations grows, so does the complexity and difficulty of having complete pipeline visibility. A single faulty integration can have widespread consequences across the business.
The shift from ETL to ELT enables the warehouse middleman
In the past decade, data platforms like Snowflake and Google BigQuery have revolutionized the industry by separating storage and compute, and introducing unlimited concurrency. This has made data warehousing accessible to any organization (not just large enterprises with outsized budgets), as large amounts of data can be loaded and stored in the cloud.
These technological advances afforded by the modern data stack have shifted pipelines from traditional ETL (Extract-Transform-Load) to ELT (Extract-Load-Transform), where data is now commonly transformed in the warehouse post-processing instead of before loading into the warehouse.

Though subtle, this has a significant impact: Data teams no longer need to know their exact use case for data before ingesting data into the warehouse. This allows data teams to use the same raw source data for multiple use cases and create different schemas and metrics directly in the warehouse.
Transformations no longer have to be en route because raw source data can be staged in the data warehouse, and data teams can perform transformations for each specific metric that needs to be synced downstream.
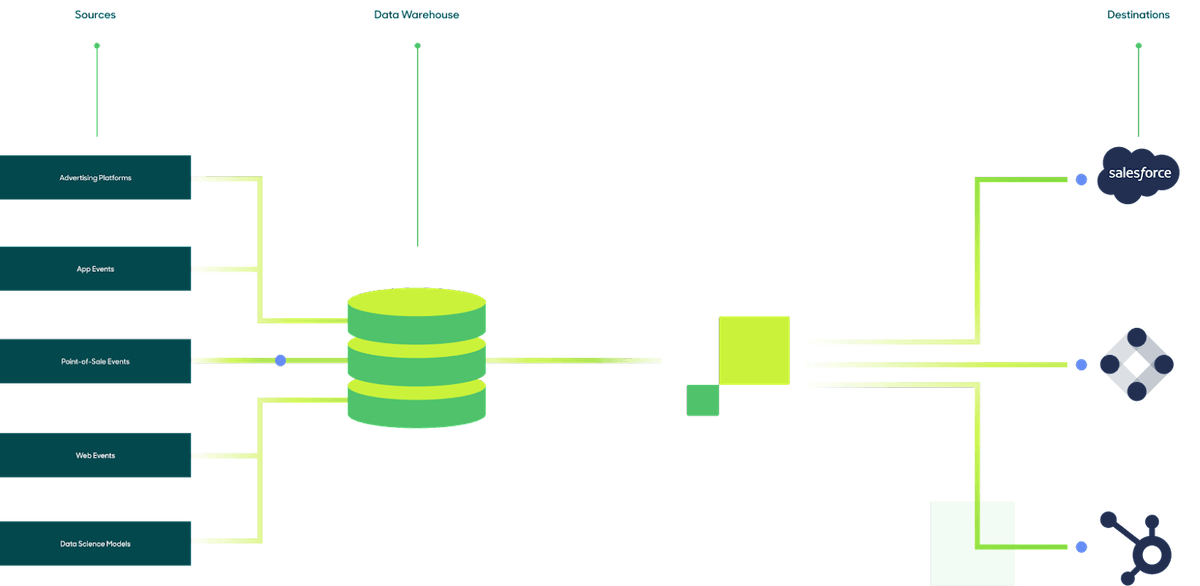
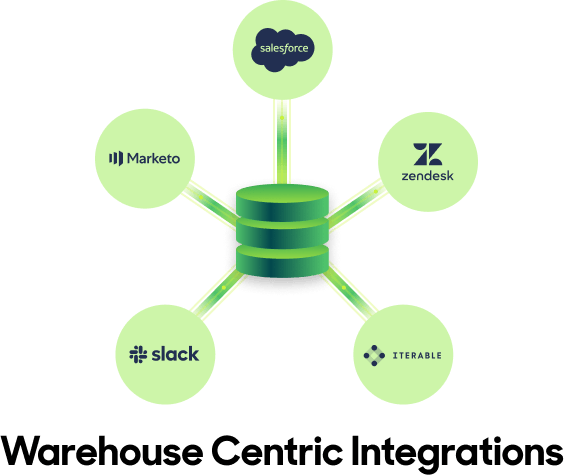
With those source of truth metrics in the warehouse, reverse ETL handles simultaneously syncing those metrics to every SaaS destination in the technology stack. Thus, if the definition for metric changes in the warehouse, then that exact change will simultaneously reflect in all downstream SaaS tools. This is the number one benefit of the hub-and-spoke model over point-to-point integrations.
Centralizing data flows through the warehouse
While using a data warehouse as a middleman in data integration can introduce some latency (typically around 15 minutes), most operational use cases do not require sub-minute latency. Many data teams prefer this batch-based approach for the following reasons:
- Because syncs are declarative, syncs are far easier to set up and do not require any code whatsoever. The logic for the sync is handled automatically and based entirely on SQL.
- The data warehouse has all data across the company, so source data can easily be enriched in SQL rather than syncing all data to the destination and joining it there. This gives users the opportunity to build fact tables in the warehouse.
- Less work is redone. Multiple SaaS destinations can rely on the same metric, rather than different SaaS tools potentially having different definitions of the same metric.
- Debugging is more straightforward. Users can see which source and intermediate tables were used to generate a sync, and they can backtrack what data was synced during every sync too.
- It’s easy to backfill and run full re-syncs. The “truth” for what data should have been synced always persists, which means no data is ever lost.
- Data can be validated, cleaned and checked in the warehouse before syncing.
- First-class support for rate limiting, retries, type checking, etc., without having to build the logic for those manually.
- The hub-and-spoke approach offers direct visibility of upstream and downstream schema structures before running a sync, so there is no trial and error.
Using the warehouse as a middleman offers considerably more reliability in metrics, debuggability in pipelines and ease of operation in a data team-centric way. It also introduces clear governance and security controls, ensuring that every business team can take advantage of all the unique insights and data models that live in the warehouse directly in their SaaS tools.
[CTA_MODULE]
Fivetran and Hightouch partner together to solve point-to-point integration using the data warehouse middleman
Data teams looking for a solution to building point-to-point data integrations should consider using Fivetran for data ingestion and Hightouch for reverse ETL. Adopting a hub-and-spoke model centered around the data warehouse avoids the complexity of traditional point-to-point integrations.
This approach offers several benefits, including consistent data flow from acquisition and ingestion to transformation and activation, thus establishing a single source of truth for all pipelines and all of the decisions that data informs. An efficient implementation is made possible with the “plug and play” functionality of Fivetran and Hightouch, which allow for simple mapping of fields and columns.
Data flows can also be streamlined and optimized by running Hightouch syncs as soon as Fivetran jobs are completed in the warehouse. This means that business teams always make decisions using the latest data, and data teams can automate the entire process after scheduling once upfront. With this automation, syncs can be run at near-realtime. But the benefits don't stop there.
This cohesive flow between ELT and reverse ETL allows for greater control over data and the ability to use all customer data, regardless of its origin. Working in parallel, Fivetran and Hightouch introduce a streamlined, efficient, effective and practical approach to data integration.

Conclusion
We strongly believe that organizations need to take a step back and look not just at the speed of a single point-to-point integration, but rather the total time invested in maintaining data quality and availability across a set of data pipelines.
Once they do so, we think it’s pretty clear that for most operational use cases it makes far more sense to take advantage of the data warehouse as an intermediary — the speed difference is minimal, while the quality and reliability go up dramatically.
If we want to help our organizations move faster, make better decisions, and be more successful it starts with the right architectural choices and using the warehouse as a hub with ETL and reverse ETL as the delivery mechanisms is the answer nine times out of ten.
[CTA_MODULE]
Hear from Hightouch at this year's Modern Data Stack Conference on April 4-5, 2023. Register with the discount code MDSCON-P2P to get 20 percent off by March 15, 2023!
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







