10 data pipeline challenges your engineers will have to solve

Data pipelines are essential to making sure your analysts have the data they need for analytics of all kinds, starting with visualizations, dashboards and reports. It can be tempting to try building your own solution to this challenge. After all, what can be complicated about moving data from one place to another?
It isn’t simply a matter of copying and pasting files, but a deep engineering undertaking that requires everything from domain knowledge to systems thinking. Moving data from one place to another is deceptively complex, and grows increasingly challenging as your organization handles greater volumes and variety of data and becomes ever more dependent on it. Like an iceberg, most of the phenomenon is hidden beneath the surface.
To build a reliable, well-functioning data pipeline, you will have to overcome the following challenges and technical problems.
[CTA_MODULE]

1. Reverse engineering the data model
Data pipelines are meant to provide analysts with the data assets they need to make sense of their data and support decisions. This requires a deep understanding of the underlying schema or data model for whatever source you’re extracting data from.
Unfortunately, the raw data exposed through an API isn’t always neatly organized into models that are usable or even intelligible to a human. If you’re lucky, the data source will provide detailed, accurate documentation that your engineers and analysts will have to pore over in order to understand what they’re getting. If you’re unlucky, you may have to spend a considerable amount of time reverse engineering the underlying data model. This may include using the data source extensively in order to understand its behavior or speaking with the developers.
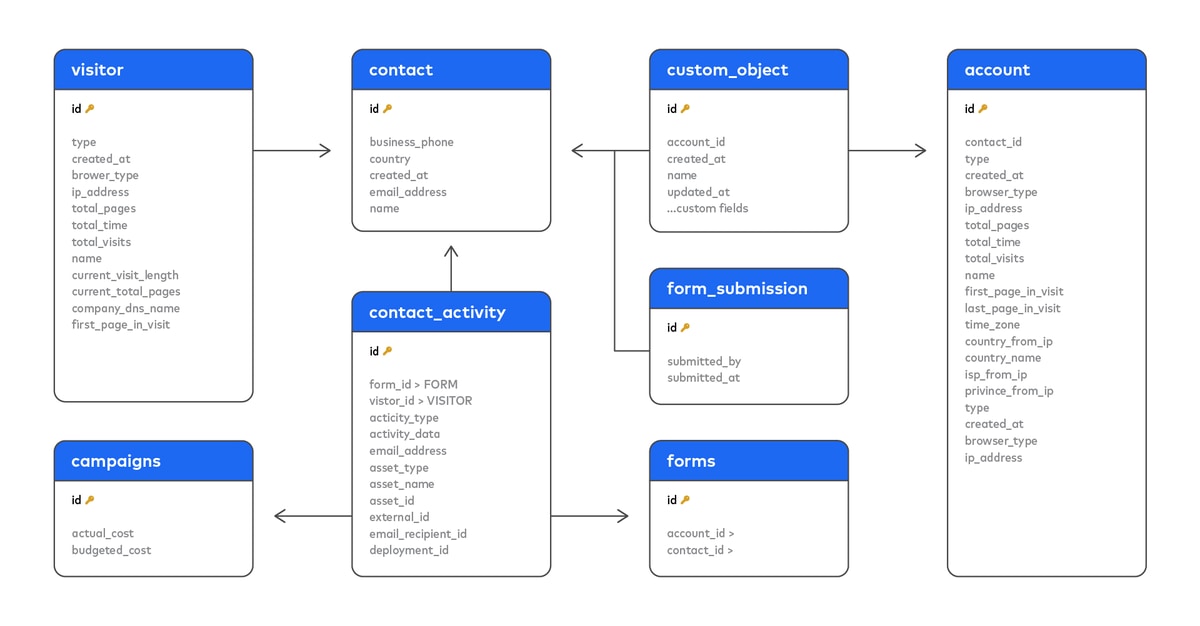
Clean entity-relationship diagrams (like below) don’t grow on trees. If they aren’t provided in the docs, you will have to painstakingly reconstruct them yourself.
2. Schema drift handling
The data model that you painstakingly reverse engineered is likely to change at some point, too. Modern cloud-based applications are in a constant state of change as SaaS providers add new features and build increasingly comprehensive data models. At any time, your typical SaaS API endpoint may add new columns and tables or fundamentally reorganize the entire schema.
You must find some way to faithfully represent these changes while ensuring that your analysts can reliably port old data to the new models. It is likely to be a huge pain.
3. Automation
The purpose of a data pipeline is to programmatically move data from a source to a destination instead of manually wrangling files. In order to do this, your data engineers need to design and build a system that enables users to easily set and forget the extraction, transformation and loading of data on a regular schedule, with a minimum of manual configuration and triggering.
At minimum, a data pipeline needs to enable users to easily create, edit, remove, run and monitor connectors. In order to make this process accessible to analysts and other users who are not primarily developers, the ideal solution is some kind of graphical user interface. Otherwise, you may find yourself giving your analysts a command line crash course or reserving access only to engineers, which will put a significant barrier between your analysts and the processes they depend on to do their jobs.
4. Transformations
Your analysts and data scientists are likely to continually discover new uses for data and new opportunities to build data-driven products. Innovation is a good thing! This also means, however, that they’re likely to want the ability to easily construct data models of their own.
How will you enable people to build new data assets in a sustained, collaborative and controlled manner?
5. Incremental updates
The simplest way to move data from one location to another is to simply copy and paste everything wholesale. Compute, storage and bandwidth are cheap these days, right?
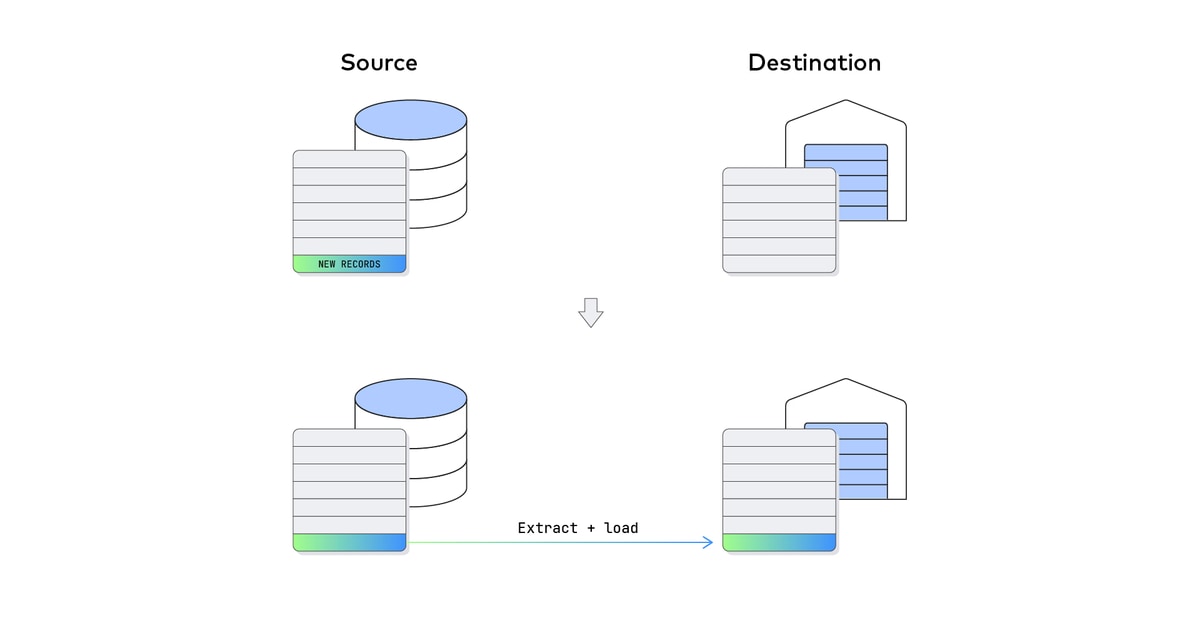
But if you have gigabyte- or terabyte-scale data sources, syncing the entire data set becomes prohibitively time- and resource-intensive. Instead, you will have to devise a system that can identify changes that have taken place at the data source between syncs. This practice is often referred to as change data capture (CDC) and requires a the use of cursors to identify where syncs have left off. For the sake of not missing any records, you may have to backtrack somewhat with each new sync, which will create duplicate records. Speaking of dealing with duplicate records…
6. Idempotence
Idempotence means that if you execute an operation multiple times, the final result will not change after the initial execution.
One way to mathematically express idempotence is like so:
f(f(x)) = f(x)
An example of an idempotent function is the absolute value function abs().
abs(abs(x)) = abs(x)
abs(abs(-11)) = abs(-11) = 11
A common, everyday example of an idempotent machine is an elevator. Pushing the button for a particular floor will always send you to that floor no matter how many times you press it.
In the context of data movement, idempotence ensures that if you apply the same data to a destination multiple times, you will get the same result. This is a key feature of recovery from pipeline failures. Without idempotence, a failed sync means an engineer must sleuth out which records were and weren’t synced and design a custom recovery procedure based on the current state of the data. With idempotence, the data pipeline can simply replay any data that might not have made it to the destination. If a record is already present, the replay has no effect; otherwise, the record is added.
Idempotence depends heavily on correctly identifying unique records and entities in a data model. You had better have done your homework when you reverse engineered that data model!
7. Parallelization
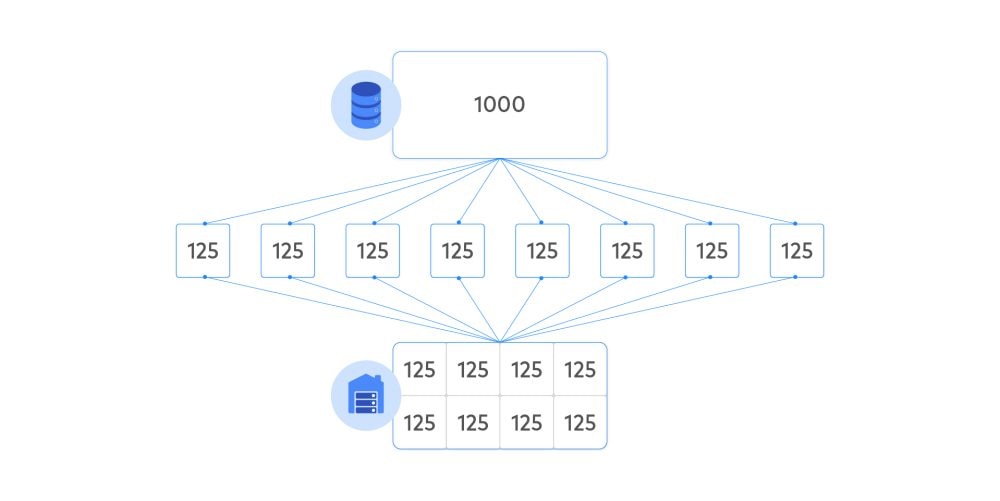
At some point, you are likely to run into performance bottlenecks as data volumes grow. One way to overcome such performance bottlenecks is to split and distribute the work into parcels to execute simultaneously rather than sequentially. Suppose you have 1,000 records and spawn eight processes. The original data can be split into eight queues of 125 records each that are executed in parallel rather than 1,000 in a single sequence.
This requires the ability to scale compute up and down as needed, so make sure you know what you’re doing before you get started.
8. Pipelining and buffering
You can’t parallelize your way through all performance bottlenecks (not to mention the expense involve in provisioning so many resources). Operations like deduplication affect entire data sets. They must be performed on monolithic blocks of data where the parts can’t be separated in order to produce the correct outputs.
To prevent backlogs and bottlenecks, you’ll have carefully stage the different elements of your data extraction, loading and transformation process into steps that can all be simultaneously populated. Consider a queue with 8 separate batches that must each be processed en bloc through steps A, B and C:
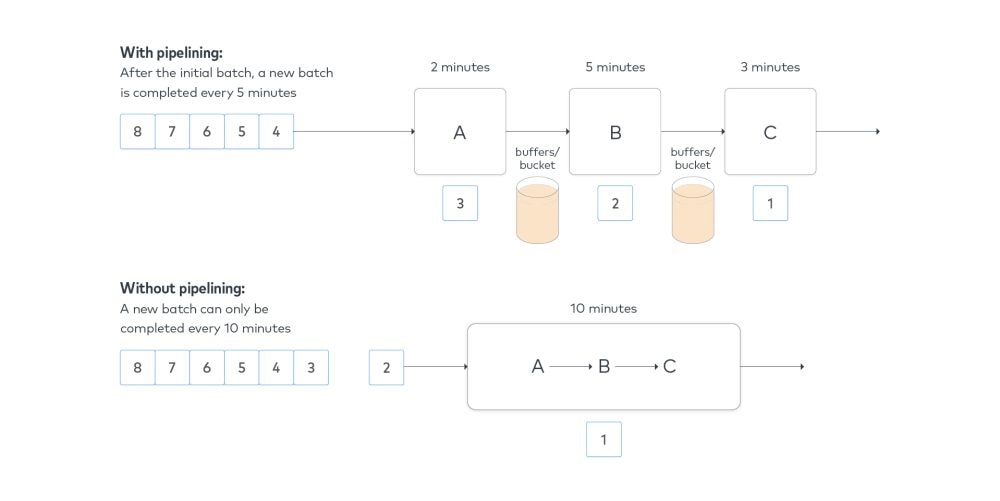
As you can see, the rate at which batches are completed depends on the slowest element of the sequence. With pipelining, step B takes the longest, so new batches will roll out every five minutes. Without pipelining, all steps are combined, so new batches can complete every 10 minutes.
You can liken this to an assembly line where there are staging areas between each process to ensure that every step remains active, so that there is always work being performed.
Similarly, you should consider buffering the different stages of the process.
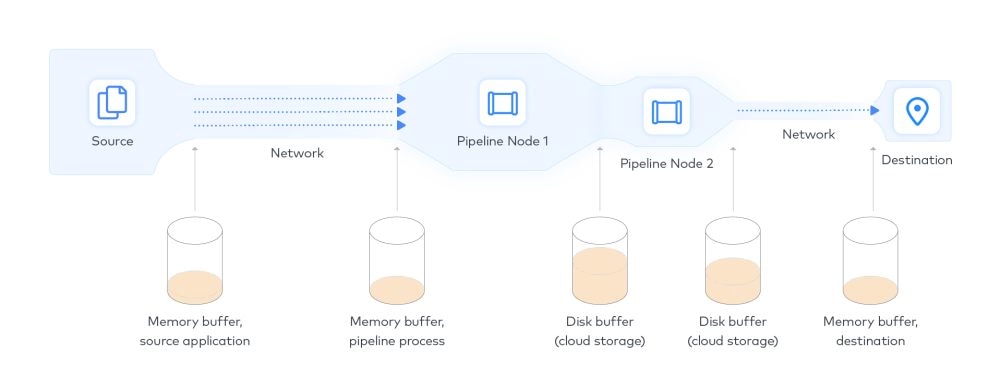
Buffers are staging areas that temporarily contain data, either in memory or on disk, whenever data is set to be handed off between machines. The more bottlenecked a subsequent stage of a handoff in comparison to the previous stage, the more the buffer will fill.
The presence of buffers can radically alter the behavior of a network. Without buffers, the movement of data along every node of the network takes place at a constant rate and is limited by the slowest bottleneck. With buffers, the flow is less brittle as nodes can act as staging areas to store batches of data.
9. Scaling and extensibility
As your organization’s use of data grows, you will have to grapple with an increasing number of sources, destinations and users. In order to responsibly manage this growth, you will need some combination of an expanded data engineering team, expanded cloud infrastructure and detailed internal processes.
At some point, these growing pains will become prohibitively expensive to solve with raw numbers of people and money.
10. Security and PID management
In order to comply with laws and regulations in many jurisdictions, you will need processes and procedures to prevent unauthorized access to and exposure of sensitive data, such as personal identifiable data (PID). Security is a high-stakes matter, with the average cost of a data breach well in the millions.
There is a dizzying array of region- and industry-based standards. Examples include:
- ISO 27001 – These standards require a vendor to
- Systematically account for information security risks
- Design and implement information security controls and contingencies
- Maintain plans to ensure continued and ongoing compliance
- PCI DSS – The Payment Card Industry Data Security Standards regulate merchants that process high volumes of data transactions a year, such as retailers
- HIPAA BAA – These are protected health information (PHI) standards for entities that handle healthcare data
- GDPR – GDPR is an EU-wide privacy rule positing that end users have the following basic rights regarding personal data:
- The right to access
- The right to be informed
- The right to data portability
- The right to be forgotten
- The right to object
- The right to restrict processing
- The right to be notified
- The right to rectification
- CCPA – similar to but more expansive than GDPR, CCPA is a California standard that encompasses household as well as personal data.
You may need to engage a third party to perform penetration testing to ensure that you aren’t exposing your organization to undue risk.
Of course, you can also obviate all of the above concerns with an automated data pipeline.
[CTA_MODULE]
Consider a free trial to witness firsthand how you can circumvent all of the problems we have listed above.
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







