Modern data architecture allows you to have your cake and eat it, too


Technological progress expands what economists call the production possibilities frontier, reducing scarcity and easing the pressure imposed by tradeoffs between competing priorities. In the data profession, the continued progress of technology has eliminated a number of vexing problems in succession.
Cloud-native platforms, automated data movement and technology-enabled data governance have radically expanded the capabilities of data teams and challenged the assumptions of well-established data integration and movement practices. The following is a walkthrough of how modern data architecture has resolved old tradeoffs, rendering old concerns irrelevant and creating new opportunities.
ETL vs. ELT
Since the 1970s, ETL – Extract, Transform, Load – has been the standard method for data integration and movement. It’s so ubiquitous that “ETL” is often used interchangeably with data integration. The ETL process requires transforming data before it’s loaded to a destination, typically through aggregation. This requires foreknowledge of how you’ll use data and strong assumptions about business logic.
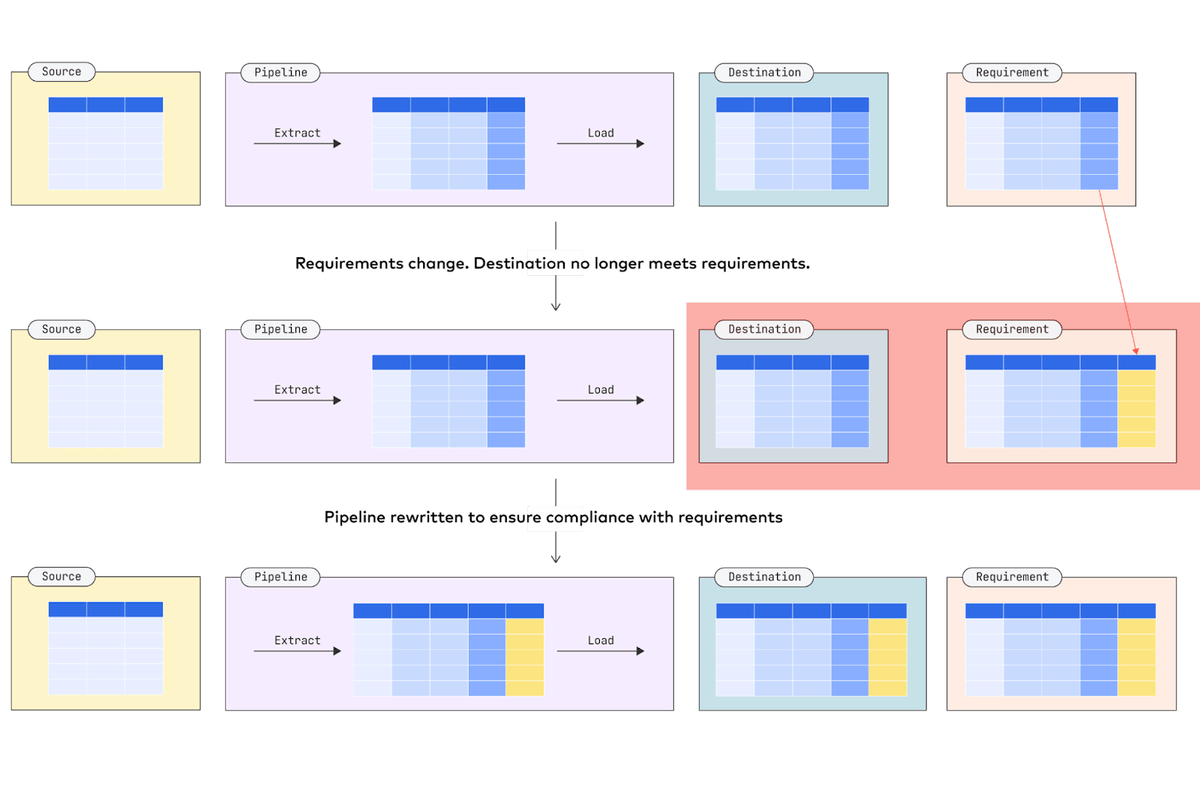
The downside to ETL is that every pipeline is a hand-built, bespoke solution that requires revision whenever the upstream schema changes or downstream data users need a new model. By tightly coupling extraction and loading, ETL saves technological resources at the expense of labor. The ETL standard emerged out of the prevailing constraints of the pre-cloud era, when compute, storage and bandwidth were all expensive and scarce.
By contrast, ELT (Extract, Load, Transform) defers transformations until the data is already in a destination, obviating the need to aggregate or otherwise preprocess data. This decouples extraction and loading from transformations and enables transformations to be performed in the destination, ensuring that the pipeline does not need to be rebuilt whenever schemas or models upstream or downstream change. Moreover, since the extraction and loading process simply outputs raw data, the pipeline can be commodified, outsourced and automated. In direct opposition to ETL, ELT saves labor by leveraging more powerful and accessible technology.
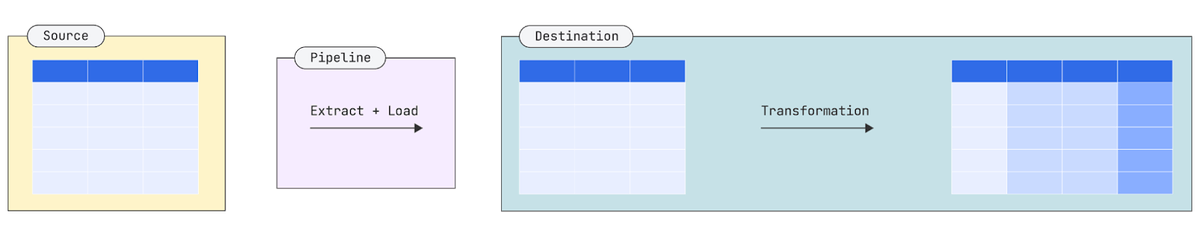
ELT is considerably more flexible than ETL but is simply not possible under conditions of legacy compute, storage and bandwidth scarcity. The modern cloud, however, with the ever-decreasing costs of compute, storage and bandwidth, has made it possible to not only adopt a more flexible data movement architecture but also entirely automate and outsource significant portions of the process. More importantly, it turns data movement from an engineering-centric process into one that is more visible and accessible to analysts, who are closer to the relevant business problems.
In short, the modern cloud has enabled a new data movement architecture under which organizations are no longer forced to preserve technological resources at the expense of labor, but may leverage radically more accessible and powerful technology to save labor. The final upshot is that organizations can save both money and engineering talent. Thus, ELT is the new standard for data movement.
Data science vs. data engineering
The occupation of “data scientist” has been in common use since the aughts, and is strongly associated with analytics and machine learning.

In practice, however, many data scientists are known to have spent more of their time on upstream technical tasks to support analytics and machine learning that are more properly characterized as data engineering. In fact, many data professionals who are hired as data scientists are not only de facto data engineers but end up changing titles (and putative careers) in response to this reality.
Before the emergence of automated data movement tools, this reality was a function of the scarcity of dedicated data engineering expertise – a highly specialized domain of software development – and off-the-shelf, plug-and-play data connectors for standard commodity data sources. Organizations that paid short shrift to data engineering found themselves unable to sustain or productionize their analytics and machine learning, relegating data science purely to the realm of ad hoc reports and prototyping.
The upshot is that data scientists, whose core strengths are in statistical analysis, were often forced to either spend considerable time on tasks that do not directly produce value and for which they may have limited interest or aptitude, or to rely on the efforts of other teams within the organization.
Automated, ELT-based data movement, itself enabled by the rise of the cloud, presents a solution to this problem by allowing data scientists to both assume direct control of the data integration process and to budget more of their time toward the analytics and machine learning activities, i.e. data science, they were hired to perform.
Access vs. compliance in data governance
Traditionally, organizations have been faced with a tradeoff between access and compliance. Different stakeholders in an organization have different needs and incentives toward data. Security and legal teams have strong incentives to err on the side of compliance and restrict access to data in order to maintain full visibility over all data assets, while data consumers may prefer less fettered access to meet the needs of their own roles. In practice, security and legal concerns tend to trump the desire for access, especially as organizations grow and stakes for data mishandling increase.
In order to properly govern data, an organization must know, access and protect its data. In the absence of dedicated tools for managing these tasks, organizations tend to impose layers of procedure and red tape between data and its consumers, restricting access in favor of compliance. This leads to stale data and a general lack of visibility and data literacy. Unfettered access in the absence of good data governance may lead to a proliferation of poorly understood data assets and even the exposure of highly sensitive data.
Organizations can ensure both access and compliance using an automated data pipeline that features robust security and data governance tools such as programmatic user provisioning, data model lineage and metadata capture and logging.
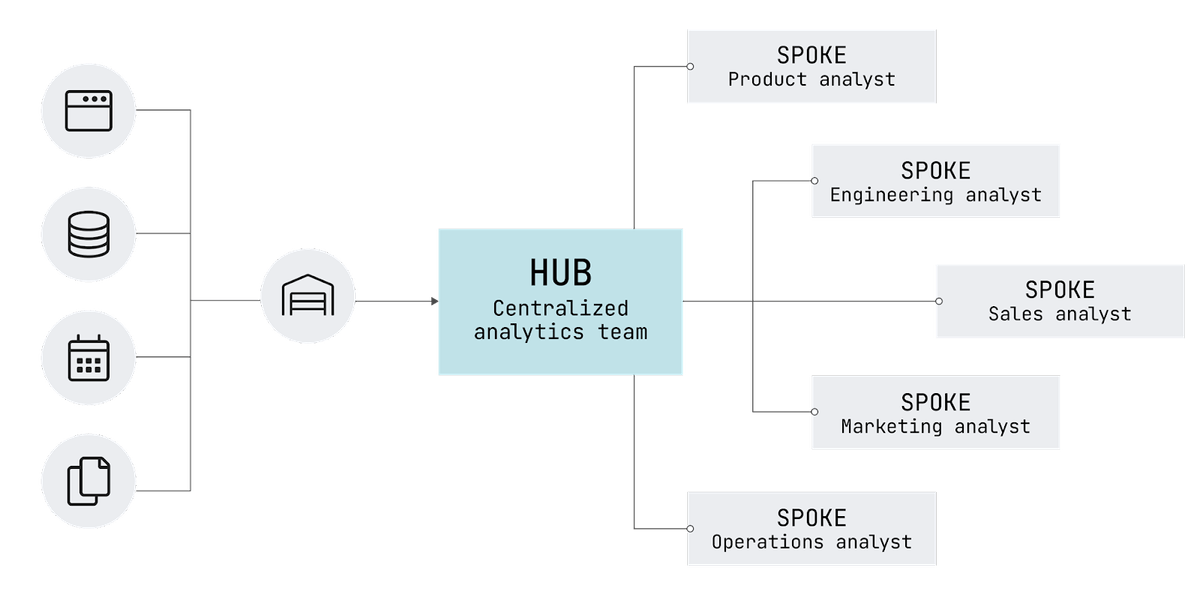
Centralized vs. decentralized decision making
When an organization has limited data governance capabilities, decision making is centralized because only the executives of an organization can see all of the (often limited) information and data available. This arrangement ensures control and coordination at the expense of agility and flexibility. Decentralized decision-making without robust data governance is apt to produce miscoordination.
Robust data governance, on the other hand, enables both coordination and agility by offering everyone in an organization a shared truth and preventing inappropriate access and usage of data. This allows decision making to be devolved down to departments and even individual contributors, eventually enabling data democratization.
Having your cake and eating it, too
The growth of the cloud enabled the transition from ETL to ELT, which also made automated data movement possible. In turn, automated data movement has solved one of the perennial tensions of data science, namely that data scientists don’t often get to do much data science. Good automated data movement tools also feature robust data governance features, allowing organizations to simultaneously ensure access and compliance. This, in turn, allows organizations to decentralize decision making, enabling flexibility while preserving central coordination and visibility.
As an automated data integration tool, Fivetran plays a critical role in helping organizations through the inflection points described above. Experience this for yourself through a demo or a trial.
[CTA_MODULE]
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







