Generative AI: A 2-year retrospective and what's next


ChatGPT was released to the public on November 30, 2022. Its debut was a defining moment for artificial intelligence, solidifying generative AI in the public imagination as an accessible and practical tool. While earlier advances in deep learning and transformer architecture laid the groundwork, ChatGPT’s immediate usefulness for tasks like information retrieval and ideation sparked widespread adoption and experimentation.
In the two years since its launch, generative AI has seen a flurry of innovation. From the rise of retrieval-augmented generation (RAG) architectures (see below) and vector databases that seamlessly integrate proprietary data with foundation models, to the emergence of commercial solutions by leading cloud platforms like Snowflake and Databricks, the generative AI landscape has expanded rapidly.

This retrospective examines the progress generative AI has made, the challenges organizations continue to face and the foundational role of data infrastructure in unlocking its potential. As we look ahead, it’s clear that the success of generative AI depends not only on advanced models but also on robust, accessible and centralized data systems.
[CTA_MODULE]
Hype can be real yet still outrun reality
However, despite broad-based enthusiasm for generative AI, progress routinely runs aground. A recent survey by Bain found that, in a five-month period spanning late 2023 and early 2024, rates of production implementations shrank even as pilot programs grew.
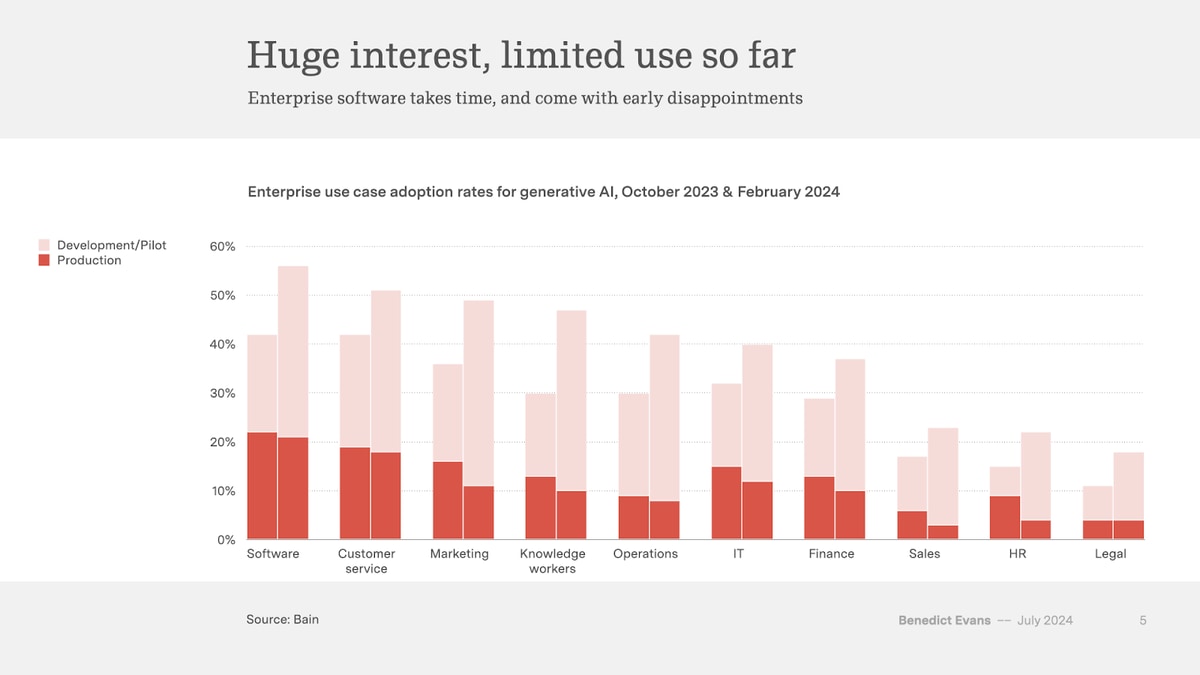
Since the height of the first “big data” hype cycle in the 2010s, the factoid that 80% of data science projects will fail has become conventional wisdom. Generative AI, with its dependency on a steady supply of data of all kinds, is no exception.
At Fivetran, we have identified two fundamental reasons generative AI projects fail to reach production. The first is a failure to establish a robust data architecture that can integrate all of the necessary data.
The dirty secret of AI is that the hardest part is the data. Are there data sources you can extract more from? That’s the secret sauce. That’s where Fivetran comes in.
– Ali Ghodsi, CEO of Databricks
As with all forms of analytics, ranging from business intelligence reporting to predictive modeling, the success of a generative AI model depends on timely, relevant, high-quality data. However, many organizations lack a cogent, systematic strategy or infrastructure for integrating this data, with data languishing in siloes and redundant infrastructure operated by separate teams.
The second obstacle to using generative AI is that, while teams may understand the benefits of using RAG to improve the quality of results, they may not practice additional measures for boosting the quality of query outputs. Data curation, augmenting a generative AI model with only the cleanest, most reliable, up-to-date and contextually relevant helpful data, is key to improving results. Prompt engineering – massaging the inputs sent to a generative AI model to help it produce the best possible output – is another measure. Finally, teams can impose guardrails on generative AI by encoding facts in data models such as knowledge graphs.
These issues are surmountable, especially as tools continue to improve. For the vast majority of organizations, RAG-based architectures are far preferable to building a foundation model from scratch.
[CTA_MODULE]
What Fivetran has accomplished using generative AI
By our standards, a robust AI product must meet the following criteria:
- High-quality output – it must be able to produce accurate or useful results for ambiguous, open-ended natural language problems
- Transparency – it can explain its reasoning and where its information came from
- Collaboration – it can respond intelligently to human input and course correct in response to new prompts
- Integration – it can be combined with other useful applications to improve workflows
- Governance – it ensures integrity of data and security of usage
We have made significant strides toward building practical AI applications of our own. One example is FivetranChat, an internal chatbot designed to function as an automated knowledge base and help desk. This project is the culmination of years of research and development into embedding and vector search, in some cases predating the popularization of RAG.
The Fivetran product forms the cornerstone of the FivetranChat architecture, with Fivetran connectors automatically extracting data every six hours from text-rich sources such as Zendesk tickets, Slab documents, Slack conversations, Height tickets, Salesforce interactions and Google Drive documents. A solid data foundation is essential to powering AI projects, and Fivetran connectors ensure a robust, steady supply of high-quality textual data.
Since its rollout in July 2024, FivetranChat, accessed via a Slack channel, has become an invaluable productivity aid for employees, addressing queries related to product functionality and engineering, company policies and operational procedures. The tool has radically reduced the need for manual document searches and asking colleagues for information, averaging nearly 300 queries per day and an 85% user satisfaction rate at a cost of $0.10 per query.
Another one of our generative AI initiatives, called CADE (CoIL Augmented Development Environment), is a labor-saving tool designed to accelerate both the development and maintenance of new data connectors. It automatically generates code based on API documentation and Fivetran product specifications. Along with other innovations in internal workflows for developing and maintaining connectors, CADE has helped Fivetran increase its roster of connectors by over 30% in a year. As of December 2024, Fivetran supports over 650 unique connectors – a significant jump from about 500 at the end of 2023.
Looking to the future
There are still many open questions regarding the future of AI. We don’t yet know, for instance, the degree to which more data and compute will yield further improvements to current foundation models. However, from the standpoint of most organizations, there is no question that augmenting existing foundation models with unique, proprietary data about their own operations can lead to practical and useful generative AI projects.
Unlike the subjects of previous hype cycles, such as blockchain, generative AI offers many practical industrial and consumer applications and is here to stay. A useful way to think of generative AI is as a power tool for the human mind. Its fundamental capability is to de-risk information acquisition of all kinds, accelerating the retrieval and synthesis of information.
Even relatively basic implementations of generative AI work like search engines on steroids, putting information that is otherwise invisible or inaccessible within reach of inquiring minds. The Washington Post recently reported that about one-third of the World Bank’s reports are never downloaded, despite almost certainly containing useful, actionable information. Studies, academic papers and other publications containing valuable information across many domains and industries similarly languish in obscurity. Language barriers prevent people from accessing the intellectual traditions of other cultures. Generative AI is changing all of this and more. As disciplines become ever more hyper-specialized, it may even offer our best chance of powering continued innovation and discovery.
At Fivetran, our mission is to make access to data as simple and reliable as electricity. For over a decade, we have been delivering analytics-ready data; now, we deliver AI-ready data, too. Much like electricity a century ago, generative AI today is still early in its development. The first power plants were built decades before industrial and consumer usage of electricity became mainstream. We now live in a time where information travels much more quickly, and opportunities for practical generative AI are very much already real.
[CTA_MODULE]
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







