Why RAG is the most accessible path to commercial AI


Since the public release of ChatGPT in late 2022, enterprises have been captivated by the promise of generative AI, yet many struggle to bridge the gap between concept and execution. To bridge this gap, organizations must first solve the challenge of integrating and managing their data, then optimize the way they interact with foundation models.
For instance, PGA Tour’s digital chief experienced a significant error when ChatGPT incorrectly stated how many times Tiger Woods had won the Tour. In response, the PGA now employs RAG to enhance foundation models like GPT-4 with accurate, context-rich data from sources such as internal documentation.
The benefits of RAG
For most enterprises, RAG offers a practical balance between innovation and feasibility. Other options, such as fine-tuning or building custom models, require massive investments of data, expertise and other resources. By contrast, RAG requires a modest volume of proprietary data and minor additions to a data stack.
However, to successfully implement RAG, organizations must solve two key challenges:
- Ensuring data is reliably moved into a platform accessible by the foundation model.
- Maximizing RAG’s capabilities to meet business needs.
Data integration: The foundation of RAG
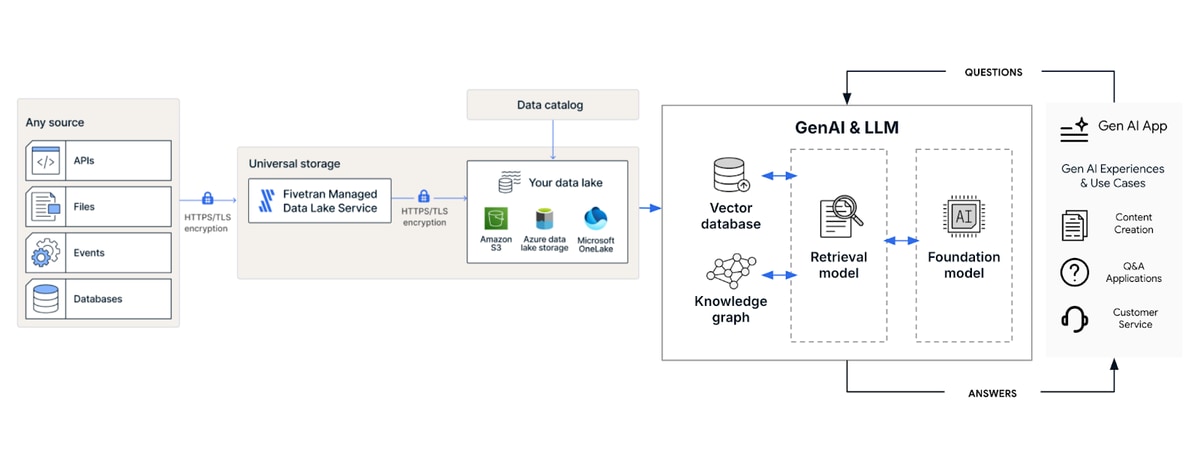
To power RAG, data must be moved from a variety of sources – databases, applications, documents and more – into formats that foundation models can access, such as vector databases and knowledge graphs. This is where automated, fully managed data integration becomes crucial.
Fivetran’s recommended RAG architecture involves two stages:
- Extracting and loading both structured and unstructured data to a data lake as a staging ground.
- Transforming and embedding the relevant data into a vector database and/or knowledge graph.
By using automated data pipelines and separating the data pipeline into these steps, a data team has a reliable, flexible and modular flow of data.
Maximizing RAG for immediate impact
Once data integration is in place, the next step is maximizing the value of RAG with a few critical strategies:
- Prompt engineering: Learning how to frame questions for the model can greatly improve accuracy. High specificity and clear context are crucial for getting reliable results.
- Data curation: Carefully selecting and refining the data used for RAG ensures the model provides relevant, accurate context. This iterative process prevents the model from producing false or "hallucinated" information.
- Knowledge graphs: While vector databases are commonly used with RAG, they produce results probabilistically, increasing the risk of errors. Knowledge graphs provide a more deterministic approach, encoding factual relationships to ensure accuracy, though they may require more computational resources.
Generative AI is still evolving
Generative AI is an extremely dynamic field, with new models and architectures appearing by the month. In the future, we may see a sudden profusion of custom foundation models for specific industries and professions, vastly improving the performance of commercial RAG deployments. New architectural developments could vastly simplify the flow of data between source systems and AI models, including live querying of production data. Public datasets could become so comprehensive, and computation so cheap, that any organization could spin up its own custom model for a modest cost.
Here and now, however, organizations can best commercialize AI by focusing on data integration and managing RAG effectively.
[CTA_MODULE]
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







