

From warehouse to AI-powered insights in minutes


You already use Fivetran Activations to turn your warehouse data into business impact. Now, we’re helping you do the same with AI. We’re introducing 2 new capabilities that open up powerful new workflows for data and AI teams:
- Embedding Columns — generate vector embeddings directly within your datasets using OpenAI or Gemini embedding models.
- New vector store connections — built-in support for Pinecone and turbopuffer, so you can sync embeddings directly to modern vector databases.
Together, these make it possible to go from raw data in your warehouse to AI-ready vectors in production — without building a single custom pipeline.
The challenge: Getting data ready for AI is hard
Every company exploring AI faces the same problem: you have rich, structured data in your warehouse — CRM records, support tickets, product feedback — but to make it usable with large language models or retrieval systems, that data needs to be turned into vector embeddings.
That usually means writing scripts, managing batch jobs, and keeping a vector database manually up to date. It’s tedious, fragile, and rarely gets the attention it deserves.
Now it’s just part of your Activations workflow. You can create embeddings as easily as you create a calculated column — and sync them anywhere.
Example workflow: Smarter support ticket search
Here’s what that looks like in practice. Your support team works in Zendesk or Intercom. Your analytics team uses Fivetran to bring that data into Snowflake. And you use Activations to model and sync it back into the business applications in your stack. Now, with Embedding Columns, you can make that data understandable and accessible in your AI workflows.
1. Add an Embedding Column
In your support_tickets dataset, use the Enrich & Enhance menu to add a new Embedding Column that converts the ticket text into an OpenAI embedding vector.
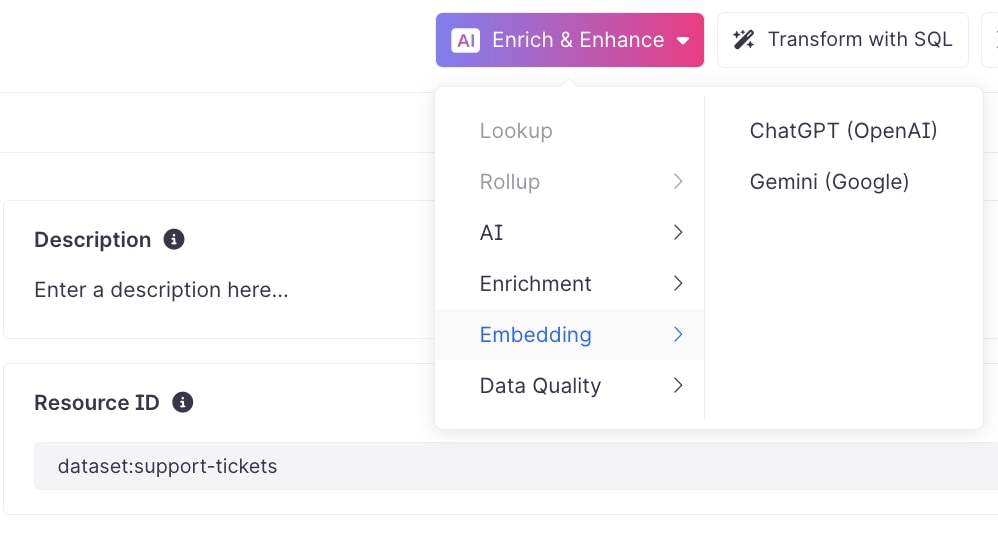
Each ticket now gets its own vector representation — a numerical encoding of meaning.
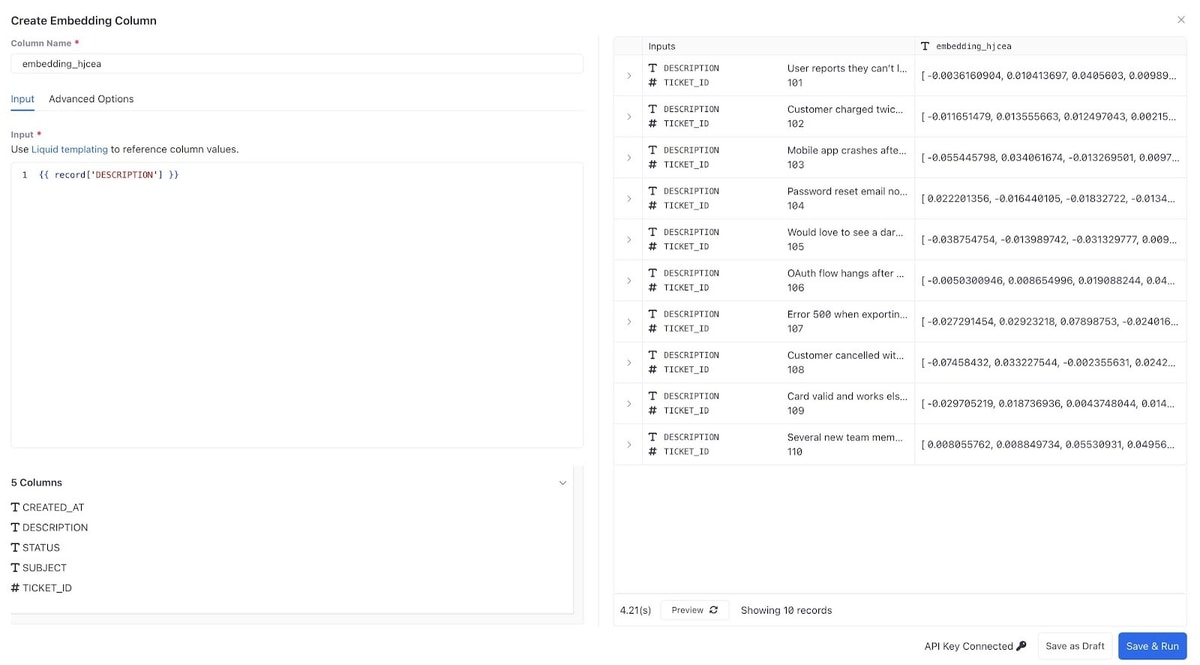
Similar tickets appear close together in vector space, even when phrased differently. One user might say “SSO login keeps failing,” another “can’t sign in with Okta.” With embeddings, AI recognizes they’re describing the same issue.
2. Sync to turbopuffer or Pinecone
Next, use our new turbopuffer or Pinecone connections to send that enriched dataset, including embeddings, directly to a vector store.
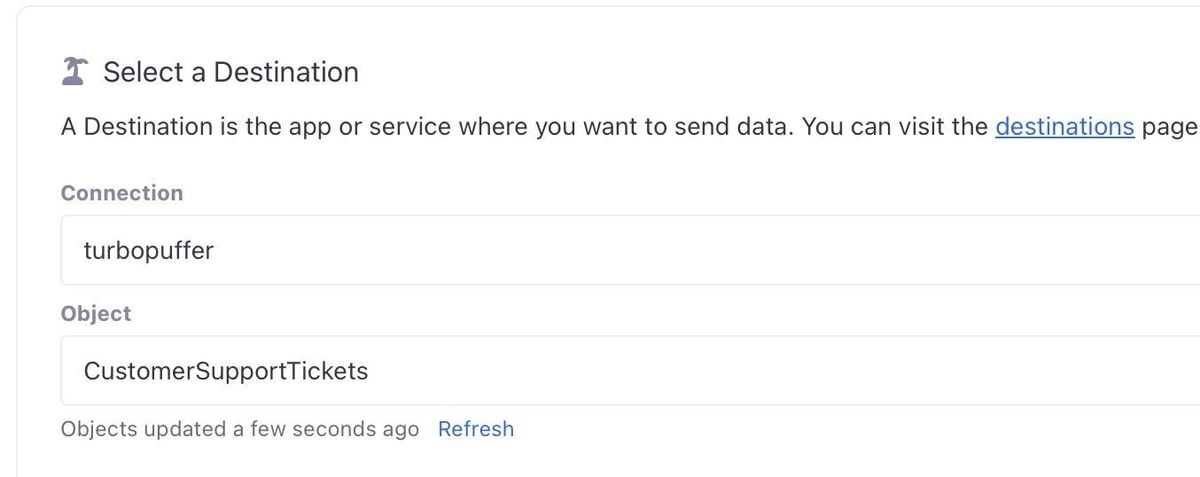
No separate ETL scripts. No batch jobs. Activations automatically keeps the vectors up to date whenever ticket data changes.
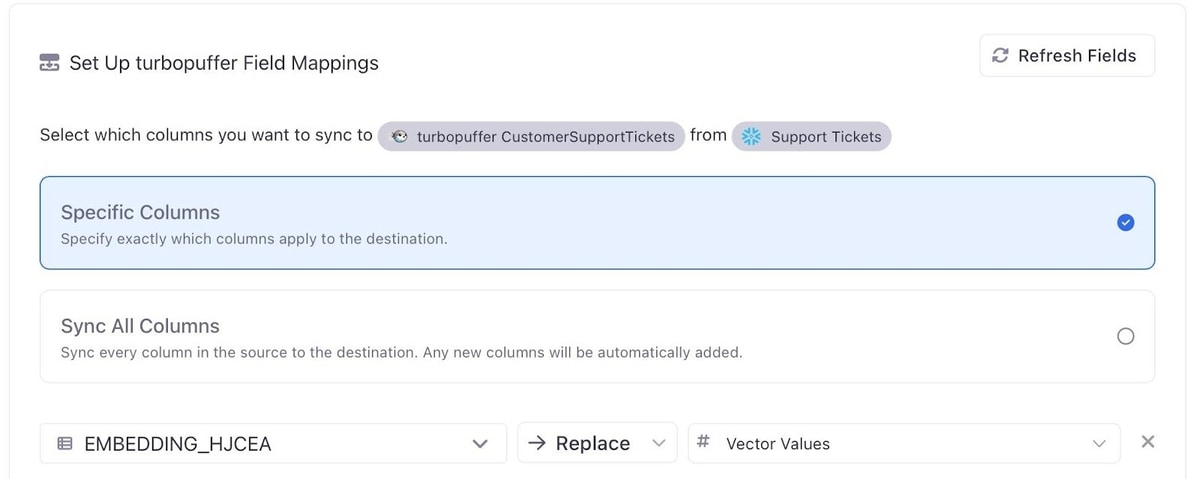
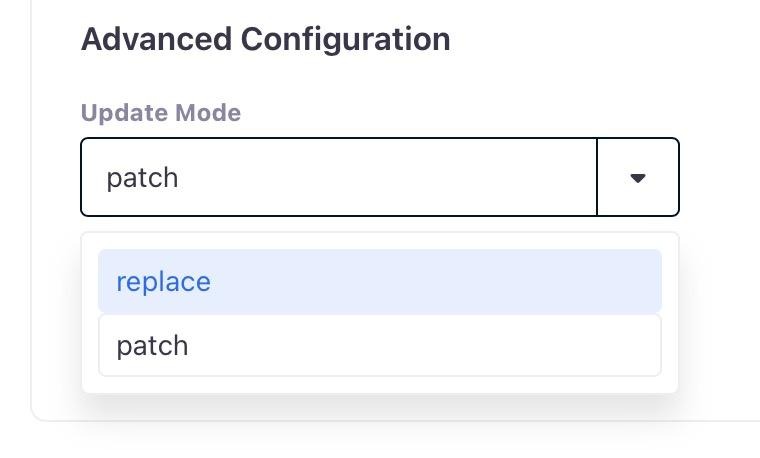
You can also augment data you might already have in turbopuffer via their “patch” ability.
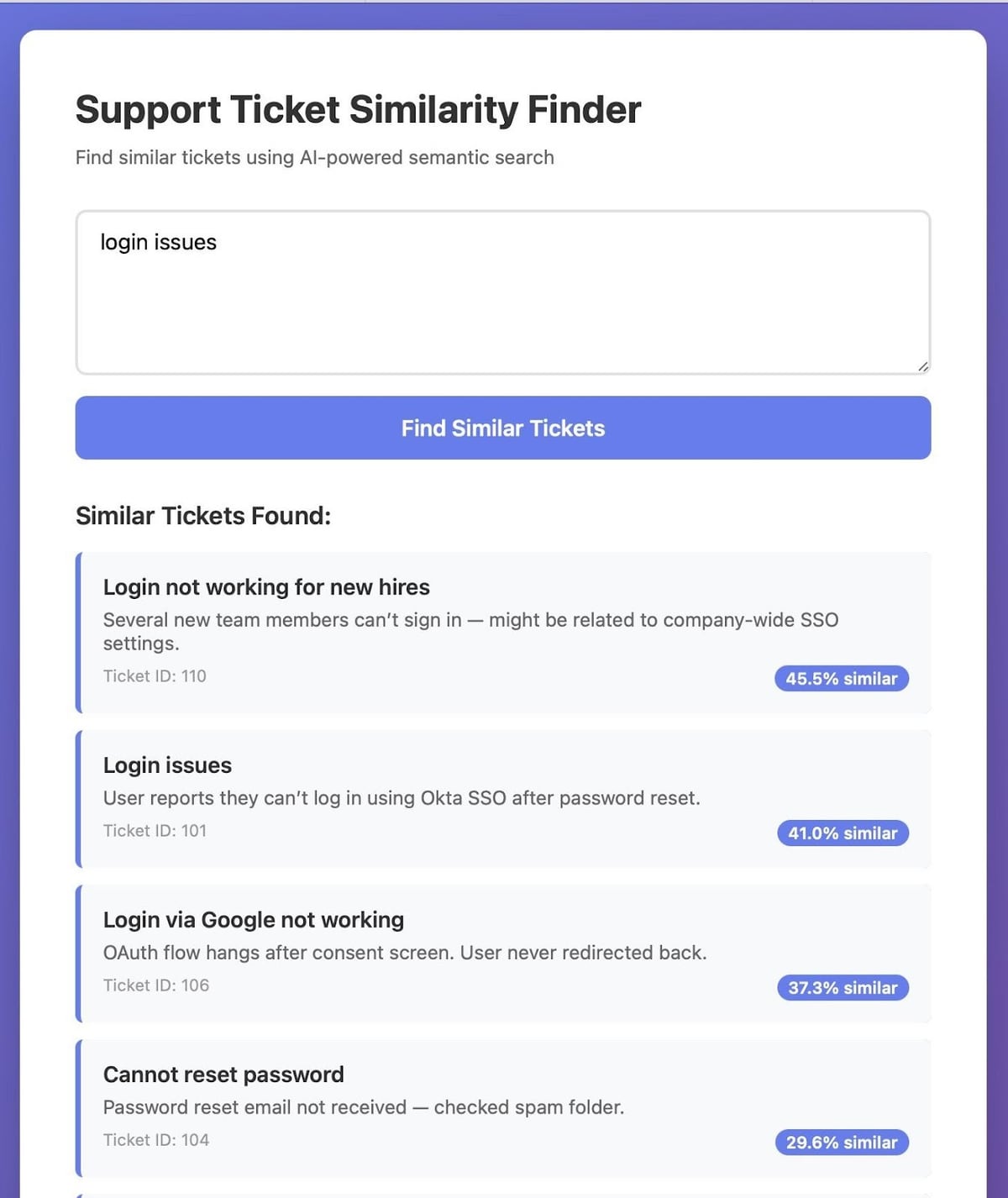
3. Build AI-powered search or suggestion tool
Your developers can now build an internal assistant or search tool that queries the vector store to find semantically similar tickets. When a new ticket comes in, your system can instantly surface:
- Related historical issues — even when phrased differently
- The resolutions that solved them
- The support agent who handled them best
It’s the beginning of smarter, retrieval-augmented support automation — powered by your warehouse and orchestrated entirely through Activations.
Why this matters
Embedding Columns and new vector store connections bring AI workflows closer to where your data already lives.
- Simplicity: No extra infrastructure or manual work. Just define your model and sync.
- Freshness: Embeddings stay current as data updates.
- Flexibility: Choose the embedding model and destination that fit into your stack.
- Governance: Everything runs through the same data contracts and lineage you already have in place.
Your warehouse isn’t just your source of truth for analytics — it’s now the foundation for AI.
What you can build next
This workflow can power countless AI-driven use cases:
- CRM intelligence: Identify similar accounts or leads based on notes or emails.
- Knowledge base search: Let employees query internal docs semantically.
- Feedback analysis: Group customer comments or survey text by meaning.
- Intelligent support: Service customers at scale with better context.
You already have the data. Now it can do more.
[CTA_MODULE]
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.






