A tale of three data platforms

At Fivetran, we regularly evaluate and benchmark the price, performance and features of leading cloud data platform vendors. One conclusion we have repeatedly drawn is that, in most important respects, cloud data platforms tend to be roughly equivalent in cost and performance. As with many technologies reaching maturity, the underlying design principles of the technologies are well-understood and savvy engineering teams will inevitably converge on similar solutions subject to similar technological constraints.
Beyond performance and cost, three leading data platforms – BigQuery, Snowflake and Databricks – share three important features in common:
- A vectorized SQL query engine written in C++
- A data “lakehouse” architecture that combines large-scale storage with ACID compliance
- Python DataFrame APIs that enable predictive analytics and machine learning
As shown in the timeline below, these features are nearly all developments from within the last five years, demonstrating convergence on a core set of features despite these platforms launching at different times and with different initial feature sets.
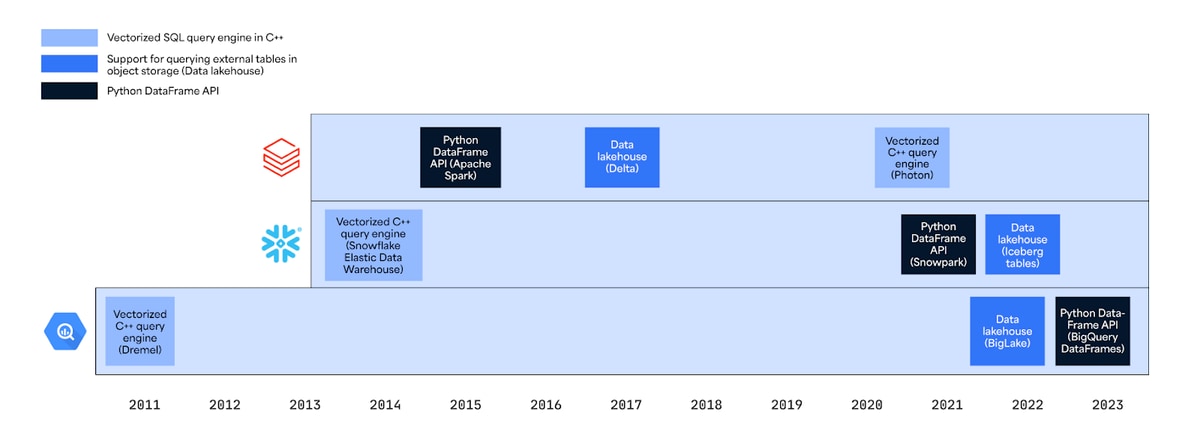
The development of these three features is a direct response to heightened performance, scalability and efficiency needs and support for more advanced workflows, such as those involving predictive modeling and machine learning. Let’s discuss each of these features in detail.
Vectorized query engines written in C++
BigQuery was an early mover among major cloud data platforms, launching in 2010 with a vectorized SQL query engine written in C++ called Dremel. Designed at its outset as a cloud-native data warehouse, Snowflake launched in 2014 with native support for vectorized querying. Although Databricks has featured SQL support since the first version of Databricks Runtime, it was written in Java. It would follow with an offering written in C++ in 2021 with the public preview of Photon.
C++ has benefited from a great deal of prior developmental work on SIMD (single instruction/multiple data) language extensions. SIMD enables multiple operations to be parallelized at the hardware level, making it an extremely powerful tool for vectorized SQL querying.
Vectorized querying improves the performance, efficiency, scalability and memory footprint of analytical queries by operating on batches of data and processing multiple elements of data in parallel. It is inextricably linked with columnar database architecture, as it allows entire columns to be loaded into a CPU register and processed.
There are two ways to think about the importance of vectorization. The first approach is at the level of records and columns. Traditional, tuple-based query processing iterates through sets of unlike items one at a time, making a large number of function calls to process multiple records.

By contrast, vector-based query processing batches like items together, processing many records at a time and making full use of columnar architectures in modern data platforms.
The second perspective is that SIMD operations allow parallelization at a very low level.

Instead of sequentially performing the four operations listed above, they can all be simultaneously handled by in parallel by a single instruction.
Modern implementations of vectorized query engines tend to be based on the architectural standard set by MonetDB/x100, first designed in 2005. As with columnar architectures themselves, the underlying principles have been understood for a long time.
Data lakehouse
Databricks was a trendsetter in the data lakehouse space, first announcing Databricks Delta in 2017 and open-sourcing Delta Lake in 2019. Google made BigLake public in early 2022. Snowflake launched Apache IcebergTM tables in 2022 as well.
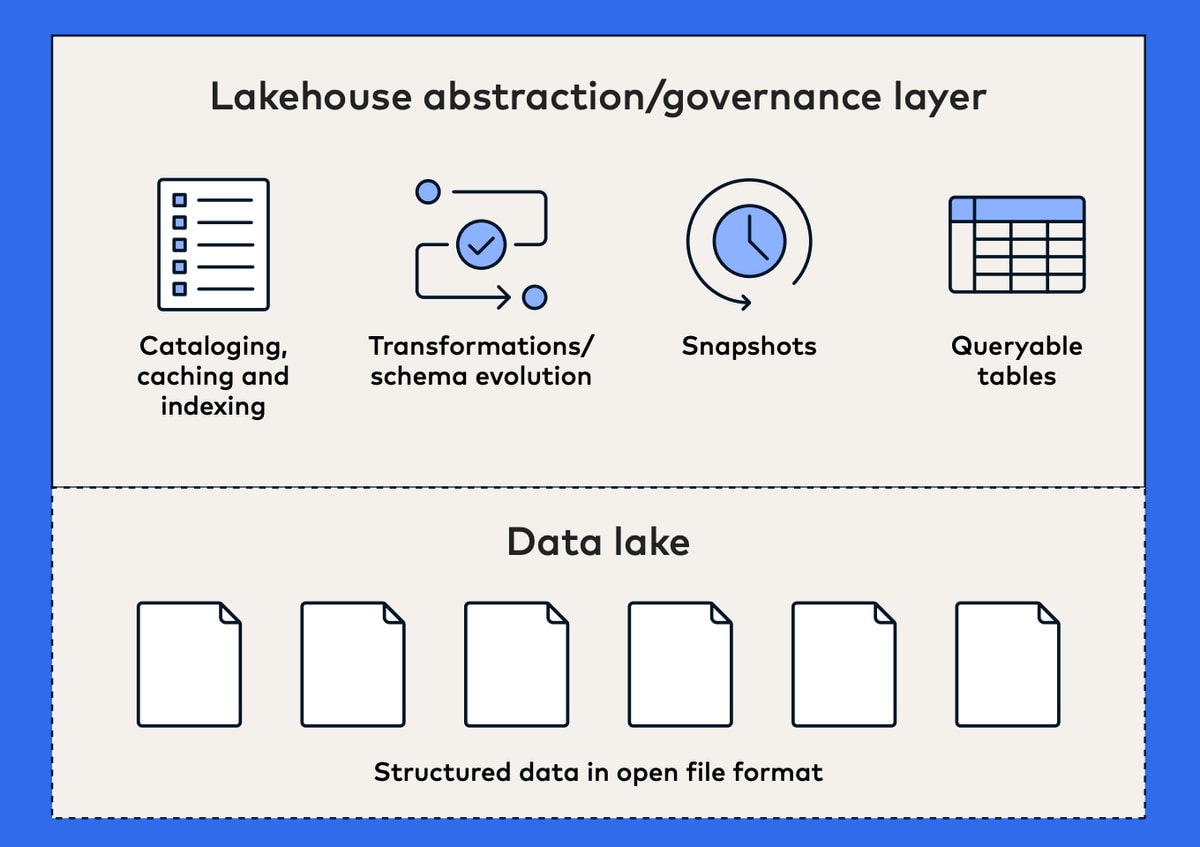
The data lakehouse architecture enables querying of external tables in object storage. It combines the strengths of both relational data warehouses and data lakes. By applying an abstraction layer over the structured data stored in a data lake, the data lakehouse combines the governance, concurrency support, ACID-compliant transactions and other benefits of data warehouses with the scalable, cost-effective storage of data lakes. Lakehouses can usually be installed over existing data lakes, preventing vendor lock-in and obviating the need for organizations to further move their data.
As with data lakes, the lakehouse architecture completely decouples compute and storage, enabling either to be scaled as needed.
Mass storage of data in data lakes will become especially important as machine learning and artificial intelligence, including generative AI, become more central to analytics efforts in every industry.
Python DataFrame API
Databricks has supported a Python DataFrame API since Apache Spark version 1.3 in 2015. Snowflake followed in early 2022 with Python support in Snowpark. As of 2023, BigQuery DataFrames is in public preview.
Python is the leading language for machine learning and DataFrames, originally a columnar data structure popularized by the statistical computation language R, is also commonly used in pandas, the premier DataFrame library for Python.
A Python DataFrame API allows data scientists and machine learning engineers to not only directly query and analyze data stored in a data platform using Python instead of SQL, but also to use Python to build and deploy data models and machine learning workflows on the same infrastructure that hosts the data, leveraging the power of scalable, cloud-based storage and compute.
Commoditization and its consequences
As data platforms become more fundamentally similar to one another, providers must either compete purely on price or differentiate themselves with unique functionality that solves adjacent problems for their customers. In the best-case scenario, differentiation means building or acquiring product lines that encompass more of the data ecosystem, vertically integrating complementary technologies and turning the platform into more of an all-in-one solution. In the worst case, differentiation can lead to feature bloat.
One practical consequence we have observed of this intensified competition is that cloud data platform providers have begun to offer native connectors to major SaaS systems, file stores and transactional databases – a development that in principle negatively affects our bottom line at Fivetran, but in practice is most likely to see niche demand from customers with a relatively narrow set of data sources.
Another straightforward consequence is that, riding the ongoing wave of public excitement over generative AI, data platform providers are increasingly offering products and services such as vector databases, integrations with foundation models and other machine learning operations tools. Examples include the announcement of Vertex AI by Google Cloud in 2021, as well as the acquisition of MosaicML by Databricks and the unveiling of Snowflake Cortex, both in 2023.
Conclusion
Major cloud data platforms are increasingly alike not only in pricing and performance but also in terms of core feature sets and capabilities:
- Vectorized SQL query engines written in C++
- Data “lakehouse” architectures
- Python DataFrame APIs that enable predictive analytics and machine learning
These capabilities respectively improve performance, enable ACID-compliant access to data stored in external data lakes and allow data scientists to more easily prototype and productionize machine learning. They are rapidly becoming standard features of data platforms used for analytics, and you should tailor your purchasing strategy accordingly!
To see an in-depth analysis of performance and pricing, read our Data Warehouse Benchmark.
Apache Iceberg is a trademark of the Apache Software Foundation.
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







