Fivetran supports Amazon S3 as a destination with open table formats


Our mission at Fivetran is to make data access as simple and reliable as electricity. With S3 powered by Fivetran and standardized on open table formats, we’re extending that vision to data lakes. Our Fivetran Managed Data Lake Service for Amazon S3 automatically and securely delivers clean, organized and standardized data from over 700 sources in your Amazon S3 data lake, helping you achieve reliable, governed and high-quality data at scale — just as you would in cloud data warehouses.
Amazon S3 offers industry-leading scalability, availability, security and performance, making it ideal for storing large data sets for analysis and data science applications. With Fivetran’s Managed Data Lake Service, you can fully leverage these Amazon S3 capabilities, ensuring that your data lake remains compliant, secure and valuable for your business needs.
According to 451 Research, “Nearly three-quarters of enterprises are currently using or piloting a data lake environment, or plan to do so within the next 12 months.” Many enterprises cite data lakes as enhancing business agility, product and service development and customer engagement.
The challenges of managing a data lake
Ingesting data into a data lake remains a challenge for many enterprise teams, often requiring custom ELT code and ongoing maintenance. Some of the qualities that make data lakes great — like massive storage — can also present challenges related to compliance and usability, especially for organizations looking to maximize value. 451 Research continues, “Data security is the most cited challenge by enterprises that are already in deployment or proof-of-concept with data lakes (37%), followed by data privacy concerns (33%) and configuring and managing data pipelines (31%).”
Fivetran’s solution focuses on governance, security and automation to effectively manage and address these challenges.
Building a modern data lake
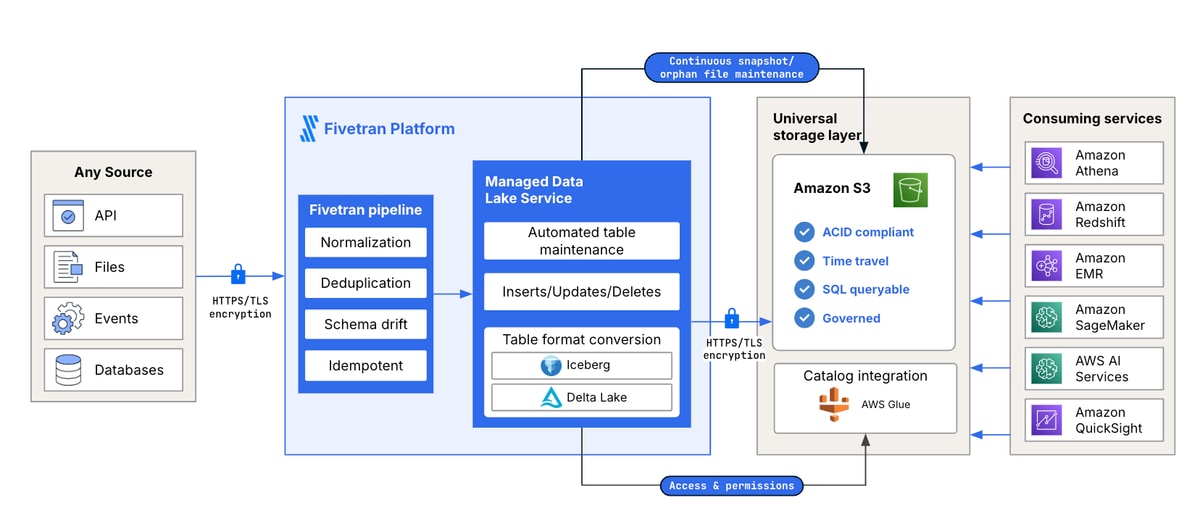
Our Managed Data Lake Service provides a compliant and secure data lake with support for atomic, consistent, isolated and durable (ACID) transactions and granular access control through AWS Glue and Unity Catalog integrations. Fully managed Fivetran pipelines anonymize personally identifiable information (PII) while cleansing, normalizing and automatically loading data into the lake.
Fivetran automates the extraction, cleansing, deduplication and preparation of large datasets, allowing you to maintain reliable, governed and high-quality data in your data lake — just as you would in a cloud data warehouse. Without structure, governance and accuracy of data in the lake, organizations cannot realize the full value of the data stored in data lakes.
”We are delighted that the accessibility of Amazon S3 continues to grow,” said Greg Khairallah, Director of Analytics at Amazon Web Services. “It’s an easy way for our customers to simplify data ingestion while providing customers the scalability of a data lake and the reliable data transformation of a data warehouse.”
Simplifying data management with Fivetran's Managed Data Lake Service
Fivetran’s Managed Data Lake Service for Amazon S3 significantly reduces the manual effort needed to build and maintain pipelines to your S3 destination and eliminates the time-consuming process of cleansing and deduplicating data once it lands. We also automate metadata management for enhanced discoverability and compliance with governance standards, populating metadata into data catalogs such as Polaris Catalog, Unity Catalog and AWS Glue. This creates a governed data foundation for building analytics and AI use cases.
The Fivetran Managed Data Lake Service brings data warehouse-like functionality to data lakes, empowering enterprise organizations to support complex use cases with minimal maintenance.
“The data lake is an easy, affordable, secure and robust way to store all our customers' data,” said Lakshmi Ramesh, Vice President, Data Services at Tinuiti. “The main challenge is in optimizing performance and accessibility, but with Fivetran’s support for Amazon S3 with Iceberg, it will further optimize our Fivetran pipeline. Since the data lake is our single source of truth, it is critical that all the data ingested from different sources be accessible in the data lake.”
With automated data integration, standardization on open table formats, continuous maintenance and robust governance, leading organizations like Tinuiti realize substantial value with Fivetran’s Managed Data Lake Service.
[CTA_MODULE]
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







