How data access shapes AI agent performance
.png)

Ask an AI agent to answer a business question, and you may accidentally learn more about your data infrastructure than about the agent. The model doesn't stumble because it isn't smart enough. It stumbles because it can't find what it needs, can't trust what it finds, or can't understand what the data actually means in your specific business context.
That's the pattern hiding behind billions of dollars in failed AI investments. And if you're a data leader or data engineer, it's your problem to solve.
[CTA_MODULE]
The failure rate nobody wants to talk about
The numbers are brutal. MIT's NANDA initiative published "The GenAI Divide: State of AI in Business 2025," a study based on 150 executive interviews, surveys of 350 employees, and analysis of 300 public AI deployments. The standout number: 95% of enterprise generative AI pilots delivered no measurable P&L impact. Not "underperformed expectations." Zero measurable impact.
Gartner predicts that over 40% of agentic AI projects will be canceled by the end of 2027, citing escalating costs, unclear business value, and inadequate risk controls. These aren't underfunded experiments. According to Gartner, global AI spending is on track to surpass $2 trillion in 2026, representing 37% year-over-year growth. The money is there. The results aren't.
The IBM Institute for Business Value's 2025 CEO Study puts it even more starkly: only 16% of AI initiatives have successfully scaled across the enterprise. That's a lot of proofs-of-concept that never proved much of anything.
So what's going wrong? The MIT researchers point not to model quality, but to what they call a "learning gap" caused by brittle workflows and a lack of contextual learning. In plain English: the AI can't connect to the data it needs, and when it does connect, it doesn't understand what the data means.
That's a data problem, not an AI problem.
Integration is the first bottleneck
An AI agent is only as good as the data it can reach. If your customer data lives in Salesforce, your product usage metrics live in a data warehouse, your support tickets live in Zendesk, and your financial data lives in an ERP system, the agent has the same problem your analysts have had for years. It's working with fragments.
The difference is that a human analyst knows to call the finance team and ask for the missing spreadsheet. An agent doesn't improvise around data gaps. It either hallucinates a confident-sounding answer, or it returns something technically correct but practically useless because it's working with an incomplete picture.
Data integration isn't new. Data teams have been wiring sources together for decades. But the requirements for agentic AI are fundamentally different from the requirements for dashboards and reports.
A BI dashboard can tolerate batch updates, manual reconciliation, and a few known gaps. An analyst sees a weird number, pings the data team on Slack, and gets the real answer by end of day. An autonomous agent can't do that. It needs reliable, programmatic access to consolidated data, and it needs that data to be current. Not "updated nightly." Current.
Think about what an agent actually does when you ask it to analyze customer churn. It needs account data from your CRM, product usage events from your application database, support ticket history from your helpdesk platform, billing data from your finance system, and probably some engagement metrics from your marketing tools. If even one of those sources is missing, stale, or inconsistent with the others, the agent's churn analysis is compromised. Not obviously wrong. Subtly wrong. And subtly wrong is worse, because people act on it.
This is where the plumbing matters. If your data pipelines are fragile, your agents inherit that fragility. If your integration layer drops records, produces duplicates, or lags by hours when the business needs minutes, the agent's output reflects every one of those flaws. Gartner found that poor data quality alone costs organizations an average of $12.9 million annually. Now imagine multiplying that cost by giving an autonomous system the authority to act on bad data without a human in the loop.
The organizations getting real value from agentic AI aren't the ones with the fanciest models. They're the ones with reliable, automated data integration that brings sources together into a single, queryable layer. No manual stitching. No tribal knowledge about which table is the "real" one. No "ask Sarah, she knows where the good data lives." Just clean, consolidated, accessible data that an agent can query without human babysitting.
Clean data or confident hallucinations (pick one)
There's a specific kind of failure that keeps data engineers up at night: the agent that answers confidently and incorrectly. Not a crash. Not an error message. A wrong answer delivered with perfect grammar and total conviction.
This happens when the underlying data is dirty. Duplicate customer records. Inconsistent date formats. Null values where there should be actuals. Revenue figures that don't match across systems because each team calculates them differently. The agent doesn't know any of this. It processes whatever it finds and produces an output.
BARC's Data, BI and Analytics Trend Monitor 2026, which surveyed over 1,500 practitioners, found that data quality management reclaimed the number one position among all respondent priorities. For AI agents, high data quality is more important than ever to avoid hallucinations, bias, and faulty recommendations. This isn't a theoretical concern. It's the single most commonly cited barrier to AI that actually works.
Data quality for agents means something more rigorous than data quality for dashboards. A dashboard with a few stale rows is annoying. An agent that makes a purchasing decision based on stale inventory data is expensive. An agent that routes a customer complaint to the wrong team because of a duplicate record is a trust problem that compounds every time it happens.
The standard dimensions still apply: accuracy, completeness, consistency, and freshness. But the stakes are higher because the consumer of the data isn't a human who can apply judgment and context. It's a system that will act on whatever it receives. Your data quality isn't just a hygiene problem anymore. It's a performance ceiling for every agent you deploy.
Context separates a demo from production
Most agent projects hit the wall that the MIT study describes right here. The agent can reach the data. The data is reasonably clean. But the agent still produces answers that make your domain experts wince. It confuses gross revenue with net revenue. It treats fiscal quarters as calendar quarters. It doesn't know that "active users" means something different to your product team than it does to your marketing team.
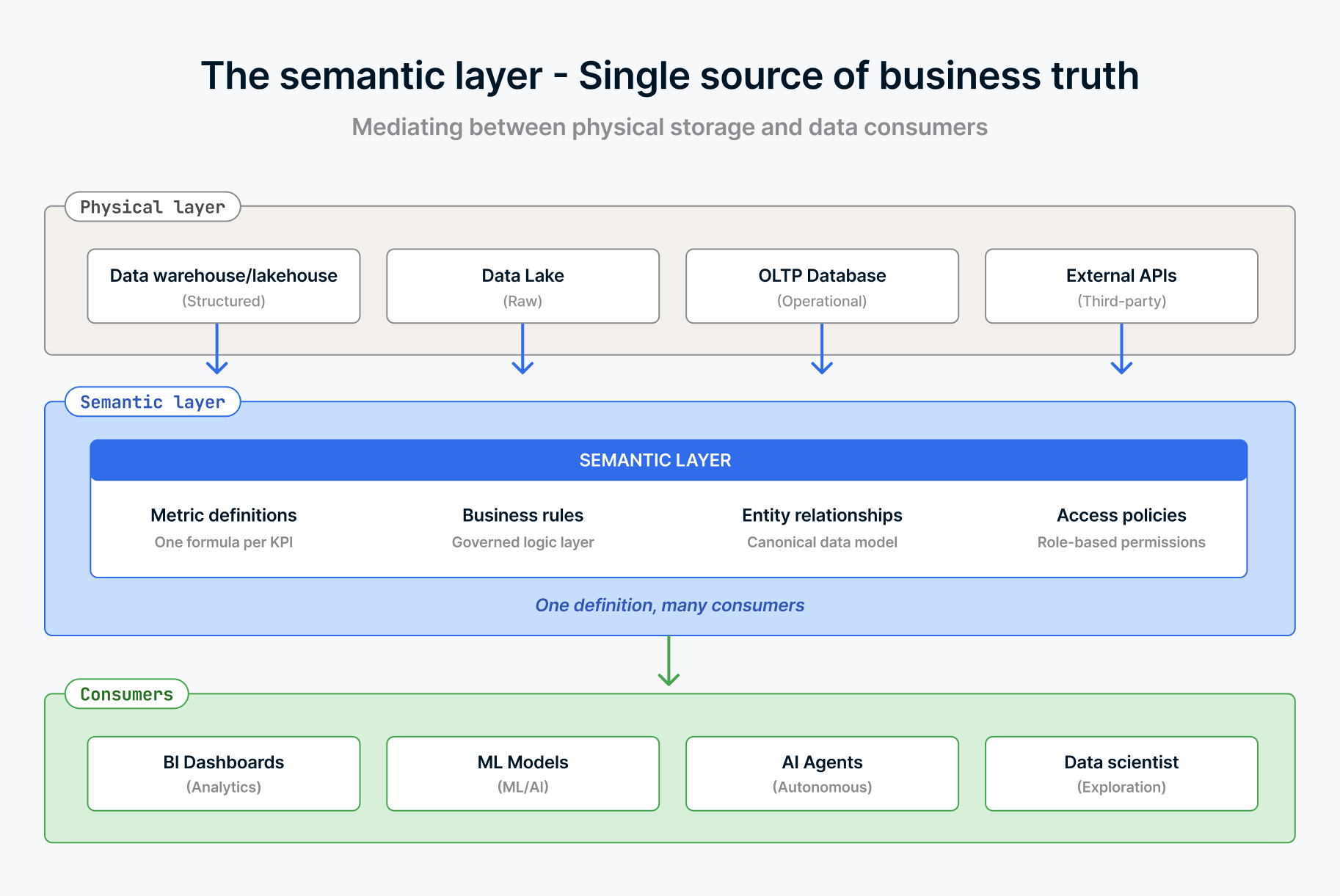
This is the context problem. Raw access to tables and columns isn't enough. The agent needs to understand what the data means in your business.
AtScale published a scenario that illustrates this perfectly. Finance reports revenue as $10.2M in Power BI. Marketing shows revenue as $10.4M in Tableau. An AI copilot surfaces revenue as $9.8M in Slack. Each number is "correct" given its source and calculation logic. But they contradict each other. Finance counts booked revenue after returns. Marketing counts gross transaction value. The AI agent, lacking any of that context, calculates whatever pattern it finds in the raw transaction tables. Sometimes it includes test data. Sometimes it excludes international sales. It depends on how the question is phrased, and in any case, its “thought process” may not even be deterministic.
A human navigates this ambiguity through institutional knowledge and reconciliation meetings. An agent needs that knowledge encoded and accessible. That's what a semantic layer does. It defines how metrics are calculated, maps business terms to specific data transformations, and makes sure that "revenue" means one thing regardless of who (or what) is asking.
Gartner's 2026 data and analytics predictions now treat universal semantic layers as critical infrastructure, placing them alongside data platforms and cybersecurity. That's a significant upgrade from "nice to have."
But semantic layers aren't the only way to deliver context. The right approach depends on the type of data and the type of question.
Agent skills — structured instructions that tell an agent how to interact with specific tools or data sources — serve a similar purpose for task execution. An agent with a well-defined skill for querying your customer data warehouse knows which tables to hit, which joins to make, and which filters to apply. It doesn't guess. It follows a codified understanding of your data model. Skills are particularly valuable for structured, repeatable queries where the business logic is well-defined and the data relationships are stable.
For unstructured data, embeddings and vector stores provide a different kind of context. When an agent needs to retrieve relevant documents, internal policies, prior analyses, or Slack conversations to inform a response, vector search lets it find semantically similar content without relying on exact keyword matches. A support agent that can pull the relevant troubleshooting guide based on the meaning of a customer's question (not just the keywords) performs fundamentally better than one that can't.
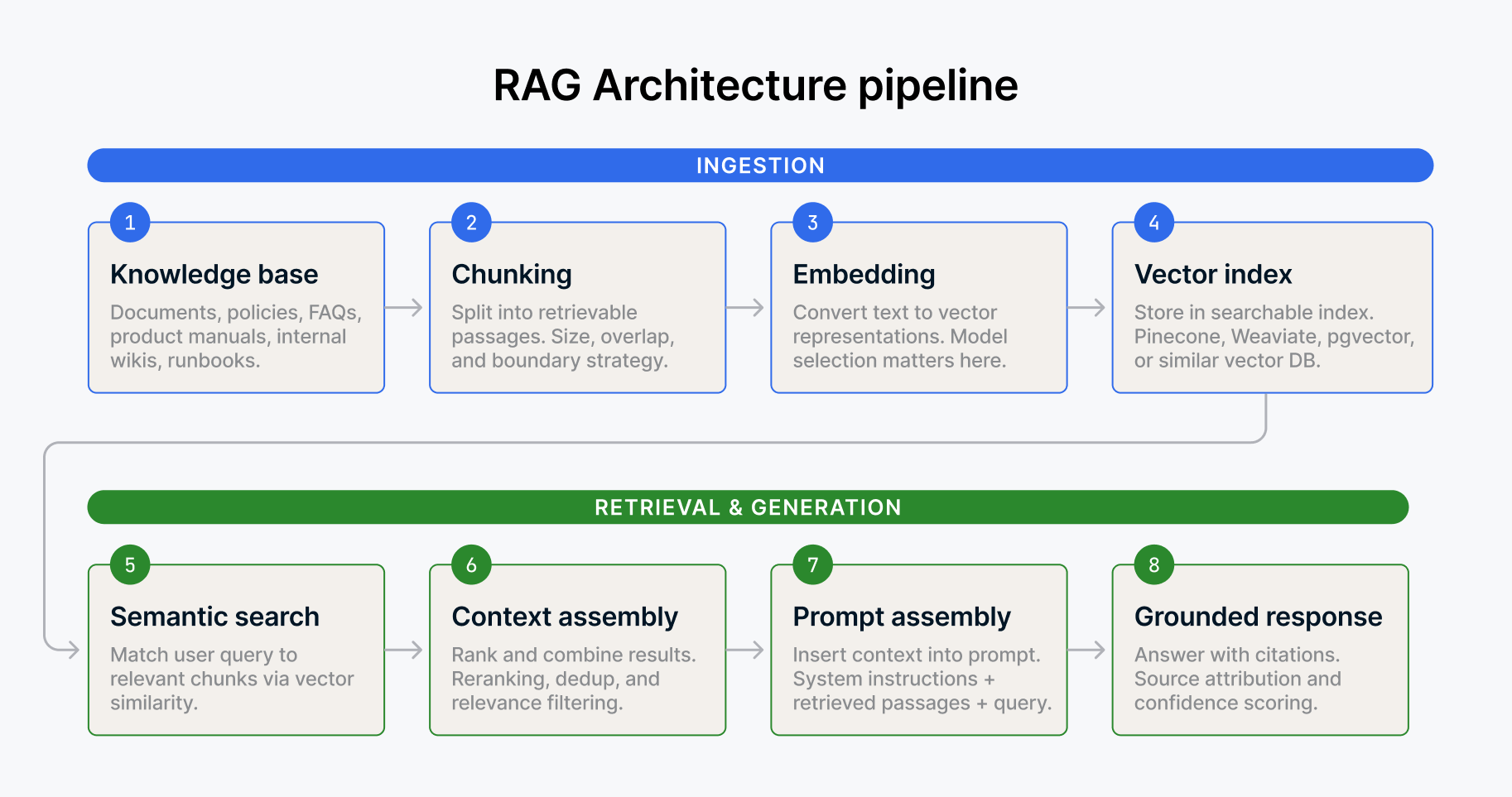
Protocols like MCP (Model Context Protocol) give agents a standardized way to connect to external tools and data sources, reducing the custom integration work that bogs down so many deployments. Instead of building bespoke connectors for every tool an agent needs to interact with, MCP provides a common interface. Think of it as the USB-C of agent connectivity. It doesn't make the agent smarter, but it makes the agent's access to data and tools dramatically more reliable and consistent.
All of these approaches share one thing: they give the agent a structured understanding of your data that goes beyond raw table access. Without context, you get a demo that impresses executives in a conference room. With context, you get a system that produces answers your domain experts actually trust.
ISG's Data and AI Market Lens Study found that more than a third of organizations rated their semantic modeling initiatives as performing below expectations. The technology works. The execution is what's hard. But the organizations that invest in building this contextual layer (however they build it) are the ones bridging the gap between pilot and production.
Governance isn't optional
There's a temptation to treat governance as something you bolt on later, after the agent is working. That's backwards. For an AI agent, governance is a prerequisite, not a follow-up task.
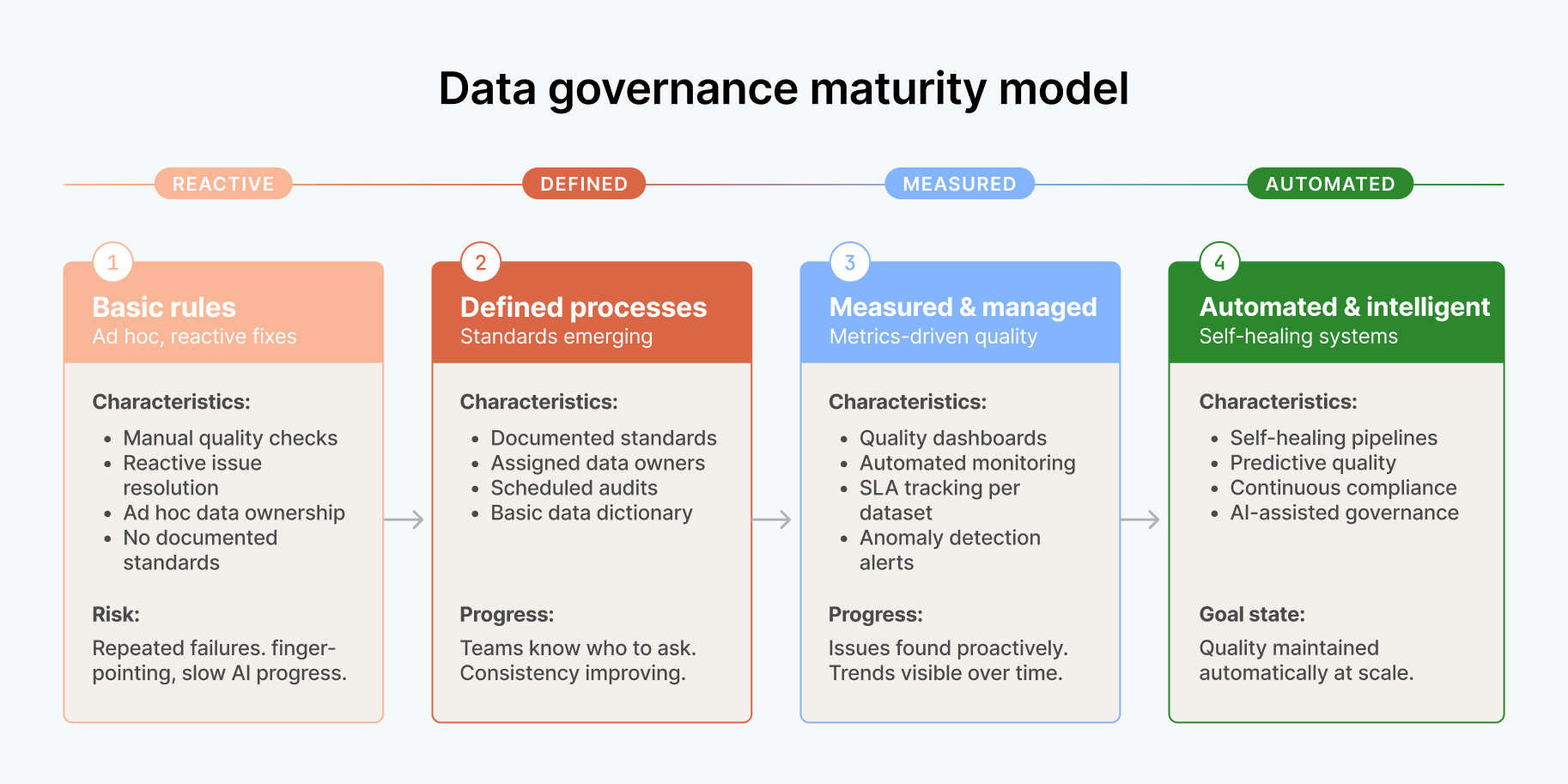
Consider what an agent actually does. It accesses data across systems. It joins datasets that might have different access controls. It produces outputs that could be seen by people who shouldn't have access to the underlying source data. It makes decisions or recommendations that need an audit trail. Without governance baked into the data layer, you're essentially giving an autonomous system a master key to your enterprise data and hoping it uses it responsibly.
Access controls need to travel with the data, not just sit at the application layer. Column-level security, row-level filtering, and role-based access policies need to be enforced regardless of whether a human or an agent is running the query. Data lineage needs to be visible so that when an agent produces a number, you can trace it back to its source and understand how it was derived. And data classification needs to be explicit so the agent knows which datasets it can and can't use for a given task.
PwC's 2025 Responsible AI survey found that nearly 60% of executives said responsible AI practices boost ROI and efficiency, but nearly half admitted that turning those principles into operational processes remains a major challenge. The gap between intent and execution is enormous. Agentic AI widens that gap because agents don't pause to ask, "Am I allowed to use this dataset?" They just use it.
BARC's Trend Monitor reinforces this: correct decisions can only be made on the basis of reliable, consistent data. For agents, "reliable and consistent" includes "governed." An ungoverned data layer isn't just a compliance risk. It's a performance bottleneck, because the alternative to governance is manual review of every agent output. And that defeats the entire purpose of automation.
Freshness is essential, not a luxury
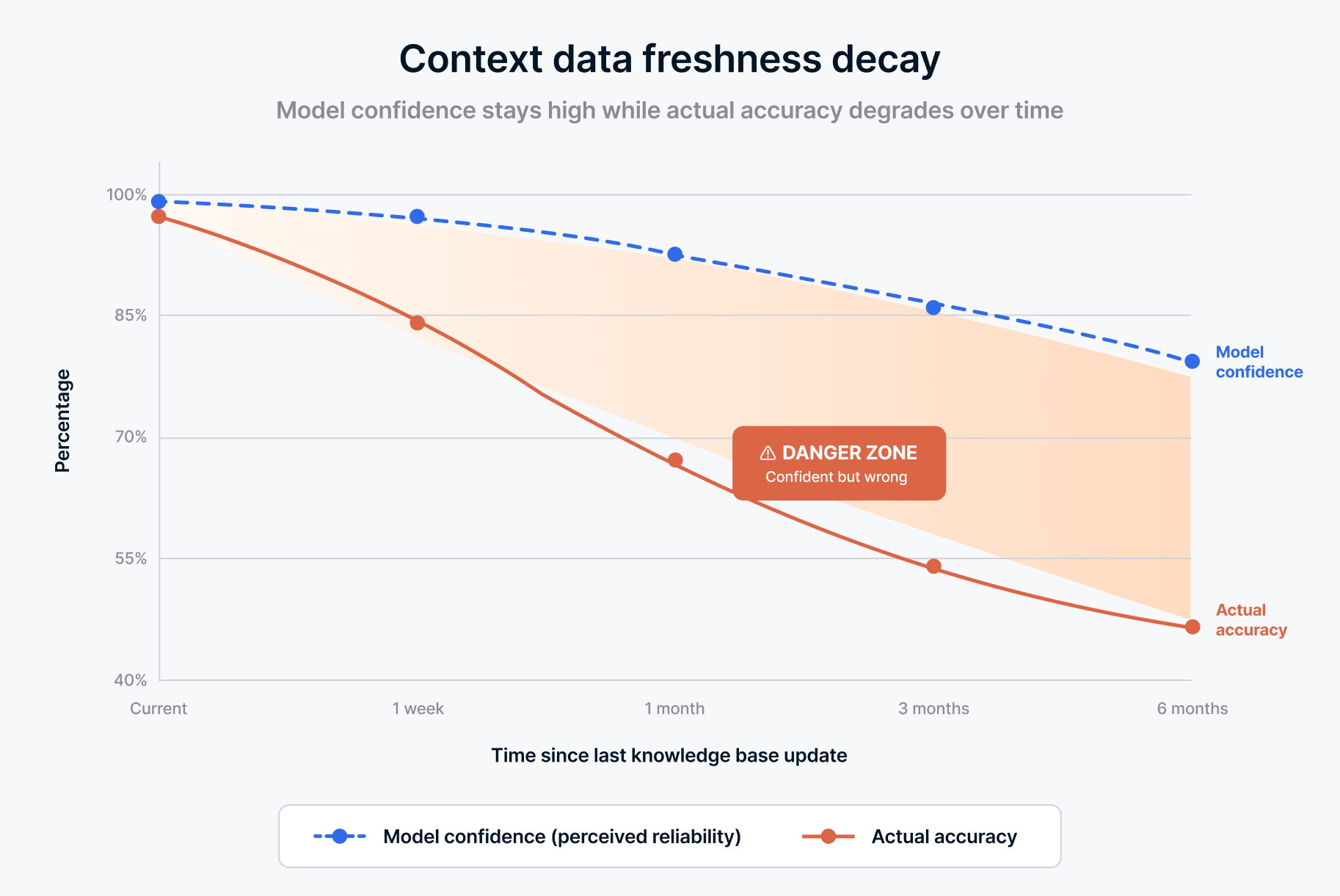
One dimension of data quality deserves its own spotlight for agentic AI: freshness.
A dashboard that refreshes once a day is fine for most business reviews. A weekly pipeline run is adequate for trend reporting. But an agent making recommendations, answering questions, or triggering workflows operates on a different clock. If a customer canceled their subscription 2 hours ago and the agent is still recommending upsell strategies based on yesterday's data, that's not just inaccurate. It's embarrassing. And in regulated industries, it might be a compliance violation.
Freshness requirements vary by use case, but the direction is clear: agents need data that reflects reality at the time of query, not reality as of the last batch run. This doesn't mean everything needs to be real-time. It means you need to understand the freshness requirements of each agent workflow and build pipelines that meet them. An inventory agent needs near-real-time stock levels. A quarterly planning agent can work with daily snapshots. The mistake is applying one refresh cadence to everything and hoping it's good enough.
The shift toward managed data infrastructure helps here. When your integration layer handles freshness as a configurable parameter per source (not a one-size-fits-all batch job), you can match pipeline behavior to agent requirements without rebuilding your architecture every time someone deploys a new use case.
What this means for data teams
If you're a data leader watching your organization spin up agent pilots, you already know where this is headed. The models will get better. The frameworks will mature. The orchestration tooling will improve. But none of that matters if the data foundation isn't there.
The work that makes agents succeed is the same work data teams have been advocating for years: reliable integration across sources, consistent data quality, clear business definitions, and strong governance. The difference is that agents make the cost of not doing this work visible in ways that dashboards never did. A bad dashboard gets ignored. A bad agent acts on bad data and creates consequences that ripple across the business.
This is actually good news for data teams. For years, data engineering has been treated as plumbing (necessary but unglamorous) while the AI and ML teams got the spotlight. Agentic AI flips that dynamic. The quality of the data layer is now the single biggest predictor of whether a multimillion-dollar AI initiative succeeds or becomes another line item on the "lessons learned" slide.
The organizations that treat data infrastructure as the foundation of their AI strategy (not an afterthought to it) will be the ones that get past the pilot phase. That 95% failure rate from the MIT study isn't inevitable. It's what happens when you build agents on top of data layers that weren't ready for autonomous consumption.
Your agents aren't limited by the model. They're limited by the data. Fix the foundation, and the 95% starts to shrink.
Ready to build the data foundation your AI agents need? See how Fivetran's Managed Data Lake Service delivers integrated, governed data to power your agentic AI initiatives.
[CTA_MODULE]
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







