Wie Datenzugriff die Leistung von KI-Agenten prägt
.png)

Fragen Sie einen KI-Agenten , um eine Geschäftsfrage zu beantworten, und Sie erfahren möglicherweise versehentlich mehr über Ihre Dateninfrastruktur als über den Agenten selbst. Das Modell stolpert nicht, weil es nicht intelligent genug ist. Es stolpert, weil es nicht finden kann, was es braucht, dem Gefundenen nicht vertrauen kann oder nicht versteht, was die Daten in Ihrem spezifischen Geschäftskontext tatsächlich bedeuten.
Das ist das Muster, das sich hinter Milliarden von Dollar an gescheiterten KI-Investitionen verbirgt. Und wenn Sie eine Führungskraft im Datenbereich oder ein Dateningenieur sind, ist es Ihr Problem, das Sie lösen müssen.
[CTA_MODULE]
Die Misserfolgsquote, über die niemand sprechen möchte
Die Zahlen sind brutal. Die NANDA-Initiative des MIT veröffentlichte „The GenAI Divide: State of AI in Business 2025“, eine Studie, die auf 150 Interviews mit Führungskräften, Umfragen unter 350 Mitarbeitern und der Analyse von 300 öffentlichen KI-Implementierungen basiert. Die herausragende Zahl: 95 % der generativen KI-Pilotprojekte in Unternehmen erzielten keine messbaren Auswirkungen auf die Gewinn- und Verlustrechnung. Nicht „Erwartungen nicht erfüllt“. Null messbare Auswirkungen.
Gartner prognostiziert, dass über 40 % der agentenbasierten KI-Projekte bis Ende 2027 eingestellt werden, unter Verweis auf steigende Kosten, unklaren Geschäftswert und unzureichende Risikokontrollen. Dies sind keine unterfinanzierten Experimente. Laut Gartner, werden die weltweiten KI-Ausgaben im Jahr 2026 voraussichtlich 2 Billionen US-Dollar übersteigen, was einem jährlichen Wachstum von 37 % entspricht. Das Geld ist da. Die Ergebnisse nicht.
Die CEO-Studie 2025 des IBM Institute for Business Value drückt es noch drastischer aus: nur 16 % der KI-Initiativen wurden erfolgreich unternehmensweit skaliert. Das sind viele Proofs-of-Concept, die nie viel bewiesen haben.
Was läuft also schief? Die MIT-Forscher verweisen nicht auf die Modellqualität, sondern auf eine von ihnen als „Lernlücke“ bezeichnete Problematik, die durch starre Arbeitsabläufe und mangelndes kontextuelles Lernen entsteht. Einfach ausgedrückt: Die KI kann sich nicht mit den benötigten Daten verbinden, und wenn sie es doch tut, versteht sie nicht, was die Daten bedeuten.
Das ist ein Datenproblem, kein KI-Problem.
Integration ist der erste Engpass
Ein KI-Agent ist nur so gut wie die Daten, auf die er zugreifen kann. Wenn Ihre Kundendaten in Salesforce, Ihre Produktnutzungsmetriken in einem Data Warehouse, Ihre Support-Tickets in Zendesk und Ihre Finanzdaten in einem ERP-System liegen, hat der Agent dasselbe Problem, das Ihre Analysten seit Jahren kennen. Er arbeitet mit Fragmenten.
Der Unterschied ist, dass ein menschlicher Analyst weiß, dass er das Finanzteam anrufen und nach der fehlenden Tabelle fragen muss. Ein Agent improvisiert nicht bei Datenlücken. Er/Sie/Es entweder halluziniert eine selbstbewusst klingende Antwort, oder er liefert etwas technisch Korrektes, aber praktisch Nutzloses, weil er mit einem unvollständigen Bild arbeitet.
Datenintegration ist nichts Neues. Datenteams verbinden seit Jahrzehnten Quellen miteinander. Doch die Anforderungen an agentische KI unterscheiden sich grundlegend von den Anforderungen an Dashboards und Berichte.
Ein BI- Dashboard kann Batch-Updates, manuelle Abstimmungen und einige bekannte Lücken tolerieren. Ein Analyst sieht eine merkwürdige Zahl, pingt das Datenteam auf Slack an und erhält die echte Antwort bis zum Ende des Tages. Ein autonomer Agent kann das nicht. Er benötigt zuverlässigen, programmatischen Zugriff auf konsolidierte Daten, und diese Daten müssen aktuell sein. Nicht „nächtlich aktualisiert“. Sondern aktuell.
Überlegen Sie, was ein Agent tatsächlich tut, wenn Sie ihn bitten, die Kundenabwanderung zu analysieren. Er benötigt Kontodaten aus Ihrem CRM, Produktnutzungsereignisse aus Ihrer Anwendungsdatenbank, Support-Ticket-Historie von Ihrer Helpdesk-Plattform, Abrechnungsdaten aus Ihrem Finanzsystem und wahrscheinlich einige Engagement-Metriken aus Ihren Marketing-Tools. Wenn auch nur eine dieser Quellen fehlt, veraltet oder inkonsistent mit den anderen ist, ist die Abwanderungsanalyse des Agenten beeinträchtigt. Nicht offensichtlich falsch. Sondern subtil falsch. Und subtil falsch ist schlimmer, weil Menschen darauf basierend handeln.
Hier kommt es auf die Infrastruktur an. Wenn Ihre Datenpipelines fragil sind, erben Ihre Agenten diese Fragilität. Wenn Ihre Integrationsschicht Datensätze verwirft, Duplikate erzeugt oder um Stunden verzögert ist, wenn das Unternehmen Minuten benötigt, spiegelt die Ausgabe des Agenten jeden dieser Fehler wider. Gartner stellte fest, dass allein schlechte Datenqualität Unternehmen durchschnittlich 12,9 Millionen US-Dollar jährlich kostet. Stellen Sie sich nun vor, diese Kosten zu vervielfachen, indem Sie einem autonomen System die Befugnis geben, auf der Grundlage schlechter Daten ohne menschliches Eingreifen zu handeln.
Die Unternehmen, die echten Mehrwert aus agentischer KI ziehen, sind nicht diejenigen mit den ausgefallensten Modellen. Es sind diejenigen mit zuverlässiger, automatisierter Datenintegration, die Quellen in einer einzigen, abfragbaren Schicht zusammenführt. Kein manuelles Zusammenfügen. Kein informelles Wissen darüber, welche Tabelle die „echte“ ist. Kein „frag Sarah, sie weiß, wo die guten Daten liegen“. Nur saubere, konsolidierte, zugängliche Daten, die ein Agent ohne menschliche Aufsicht abfragen kann.
Saubere Daten oder selbstbewusste Halluzinationen (wählen Sie eins)
Es gibt eine bestimmte Art von Fehler, die Dateningenieuren den Schlaf raubt: der Agent, der selbstbewusst und falsch antwortet. Kein Absturz. Keine Fehlermeldung. Eine falsche Antwort, geliefert mit perfekter Grammatik und voller Überzeugung.
Das passiert, wenn die zugrunde liegenden Daten unsauber sind. Doppelte Kundendatensätze. Inkonsistente Datumsformate. Nullwerte, wo eigentlich Ist-Werte sein sollten. Umsatzdaten, die systemübergreifend nicht übereinstimmen, weil jedes Team sie anders berechnet. Der Agent weiß nichts davon. Er verarbeitet, was immer er findet, und liefert ein Ergebnis.
BARCs Daten-, BI- und Analyse-Trendmonitor 2026, der über 1.500 Praktiker befragte, ergab, dass das Datenqualitätsmanagement unter allen Prioritäten der Befragten wieder die Spitzenposition einnahm. Für KI-Agenten ist eine hohe Datenqualität wichtiger denn je, um Halluzinationen, Verzerrungen und fehlerhafte Empfehlungen zu vermeiden. Das ist keine theoretische Angelegenheit. Es ist die am häufigsten genannte Hürde für eine tatsächlich funktionierende KI.
Datenqualität für Agenten erfordert strengere Maßstäbe als Datenqualität für Dashboards. Ein Dashboard mit ein paar veralteten Zeilen ist ärgerlich. Ein Agent, der eine Kaufentscheidung auf der Grundlage veralteter Bestandsdaten trifft, ist teuer. Ein Agent, der eine Kundenbeschwerde aufgrund eines doppelten Datensatzes an das falsche Team weiterleitet, ist ein Vertrauensproblem, das sich mit jedem Vorkommen verschärft.
Die Standarddimensionen gelten weiterhin: Genauigkeit, Vollständigkeit, Konsistenz und Aktualität. Aber es steht mehr auf dem Spiel, da der Datenkonsument kein Mensch ist, der Urteilsvermögen und Kontext anwenden kann. Es ist ein System, das auf alles reagiert, was es erhält. Ihre Datenqualität ist nicht mehr nur ein Hygieneproblem. Sie ist eine Leistungsgrenze für jeden Agenten, den Sie einsetzen.
Der Kontext unterscheidet eine Demo von der Produktion
Die meisten Agentenprojekte stoßen genau hier an die Grenzen, die die MIT-Studie beschreibt. Der Agent kann auf die Daten zugreifen. Die Daten sind einigermaßen sauber. Aber der Agent liefert immer noch Antworten, die Ihre Fachexperten die Stirn runzeln lassen. Er verwechselt Bruttoumsatz mit Nettoumsatz. Er behandelt Geschäftsjahresquartale als Kalenderquartale. Er weiß nicht, dass "aktive Nutzer" für Ihr Produktteam etwas anderes bedeutet als für Ihr Marketingteam.
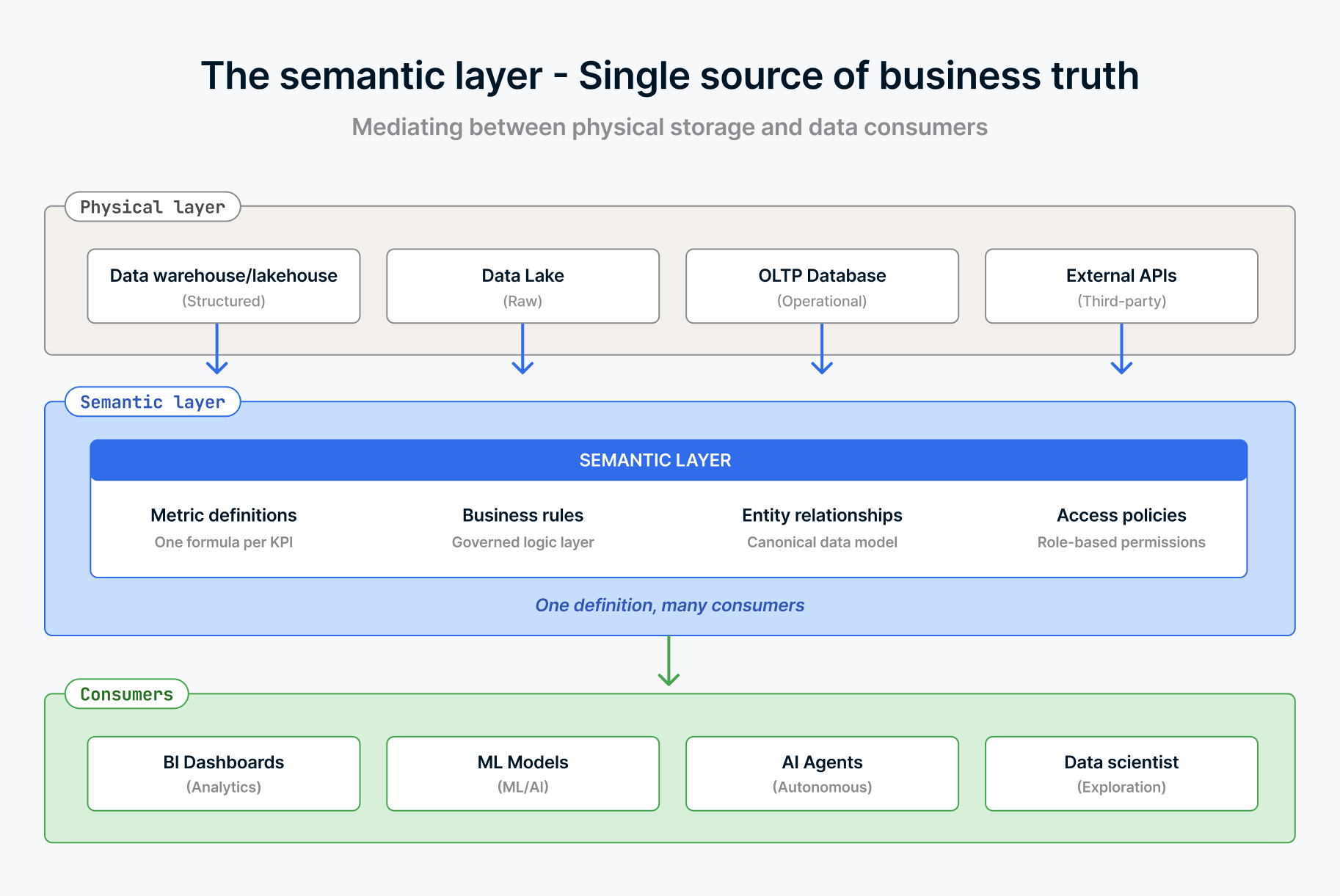
Das ist das Kontextproblem. Der reine Zugriff auf Tabellen und Spalten reicht nicht aus. Der Agent muss verstehen, was die Daten in Ihrem Unternehmen bedeuten.
AtScale veröffentlichte ein Szenario das dies perfekt veranschaulicht. Die Finanzabteilung weist in Power BI einen Umsatz von 10,2 Mio. $ aus. Das Marketing zeigt in Tableau einen Umsatz von 10,4 Mio. $. Ein KI-Copilot zeigt in Slack einen Umsatz von 9,8 Mio. $ an. Jede Zahl ist "korrekt", wenn man ihre Quelle und Berechnungslogik berücksichtigt. Aber sie widersprechen sich gegenseitig. Die Finanzabteilung zählt den gebuchten Umsatz nach Retouren. Das Marketing zählt den Bruttotransaktionswert. Der KI-Agent, dem dieser Kontext fehlt, berechnet jedes Muster, das er in den Rohdaten der Transaktionstabellen findet. Manchmal schließt er Testdaten ein. Manchmal schließt er internationale Verkäufe aus. Es hängt davon ab, wie die Frage formuliert ist, und in jedem Fall ist sein „Denkprozess“ möglicherweise nicht einmal deterministisch.
Ein Mensch navigiert durch diese Mehrdeutigkeit mittels institutionellem Wissen und Abstimmungsmeetings. Ein Agent benötigt dieses Wissen kodiert und zugänglich. Das ist es, was ein semantische Schicht leistet. Sie definiert, wie Metriken berechnet werden, ordnet Geschäftsbedingungen spezifischen Datentransformationen zu und stellt sicher, dass "Umsatz" nur eine Bedeutung hat, unabhängig davon, wer (oder was) fragt.
Gartners Daten- und Analyseprognosen für 2026 behandeln universelle semantische Schichten nun als kritische Infrastruktur, indem sie sie neben Datenplattformen und Cybersicherheit einordnen. Das ist eine deutliche Aufwertung gegenüber einem "nice to have".
Aber semantische Schichten sind nicht der einzige Weg, Kontext zu liefern. Der richtige Ansatz hängt von der Art der Daten und der Art der Frage ab.
Agentenfähigkeiten – strukturierte Anweisungen, die einem Agenten mitteilen, wie er mit bestimmten Tools oder Datenquellen interagieren soll – dienen einem ähnlichen Zweck bei der Aufgabenausführung. Ein Agent mit einer klar definierten Fähigkeit zur Abfrage Ihres Kundendaten-Warehouses weiß, welche Tabellen er ansprechen, welche Joins er erstellen und welche Filter er anwenden muss. Er rät nicht. Er folgt einem kodifizierten Verständnis Ihres Datenmodells. Fähigkeiten sind besonders wertvoll für strukturierte, wiederholbare Abfragen, bei denen die Geschäftslogik klar definiert und die Datenbeziehungen stabil sind.
Für unstrukturierte Daten bieten Embeddings und Vektorspeicher eine andere Art von Kontext. Wenn ein Agent relevante Dokumente, interne Richtlinien, frühere Analysen oder Slack-Konversationen abrufen muss, um eine Antwort zu formulieren, ermöglicht die Vektorsuche das Auffinden semantisch ähnlicher Inhalte, ohne sich auf exakte Keyword-Übereinstimmungen zu verlassen. Ein Support-Agent, der den relevanten Leitfaden zur Fehlerbehebung basierend auf der Bedeutung der Frage eines Kunden (nicht nur der Keywords) findet, arbeitet grundlegend besser als einer, der dies nicht kann.
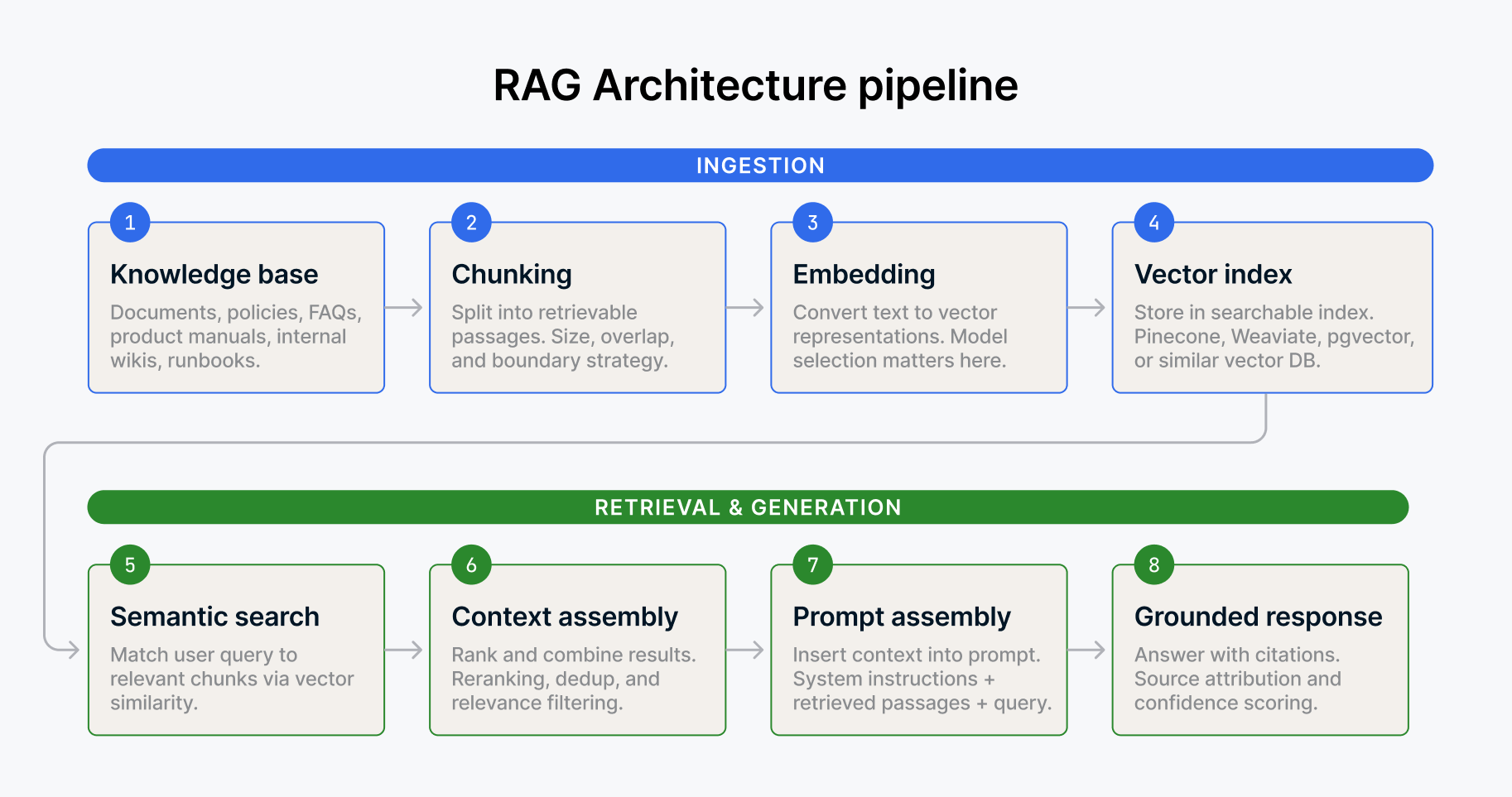
Protokolle wie MCP (Model Context Protocol) bieten Agenten eine standardisierte Möglichkeit, sich mit externen Tools und Datenquellen zu verbinden, wodurch der kundenspezifische Integrationsaufwand reduziert wird, der so viele Implementierungen verlangsamt. Anstatt für jedes Tool, mit dem ein Agent interagieren muss, maßgeschneiderte Konnektoren zu entwickeln, bietet MCP eine gemeinsame Schnittstelle. Stellen Sie es sich wie den USB-C-Anschluss für die Agentenkonnektivität vor. Es macht den Agenten nicht intelligenter, aber es macht den Zugriff des Agenten auf Daten und Tools erheblich zuverlässiger und konsistenter.
All diese Ansätze haben eines gemeinsam: Sie vermitteln dem Agenten ein strukturiertes Verständnis Ihrer Daten, das über den reinen Tabellenzugriff hinausgeht. Ohne Kontext erhalten Sie eine Demo, die Führungskräfte in einem Konferenzraum beeindruckt. Mit Kontext erhalten Sie ein System, das Antworten liefert, denen Ihre Fachexperten tatsächlich vertrauen.
ISG-Studie „Data and AI Market Lens“ ergab, dass mehr als ein Drittel der Unternehmen ihre Initiativen zur semantischen Modellierung als unter den Erwartungen liegend bewerteten. Die Technologie funktioniert. Die Umsetzung ist das Schwierige. Aber die Unternehmen, die in den Aufbau dieser kontextuellen Ebene investieren (wie auch immer sie diese aufbauen), sind diejenigen, die die Lücke zwischen Pilotprojekt und Produktion schließen.
Governance ist nicht optional
Es besteht die Versuchung, Governance als etwas zu behandeln, das man später, nachdem der Agent funktioniert, hinzufügt. Das ist der falsche Ansatz. Für einen KI-Agenten ist Governance eine Voraussetzung, keine nachgelagerte Aufgabe.
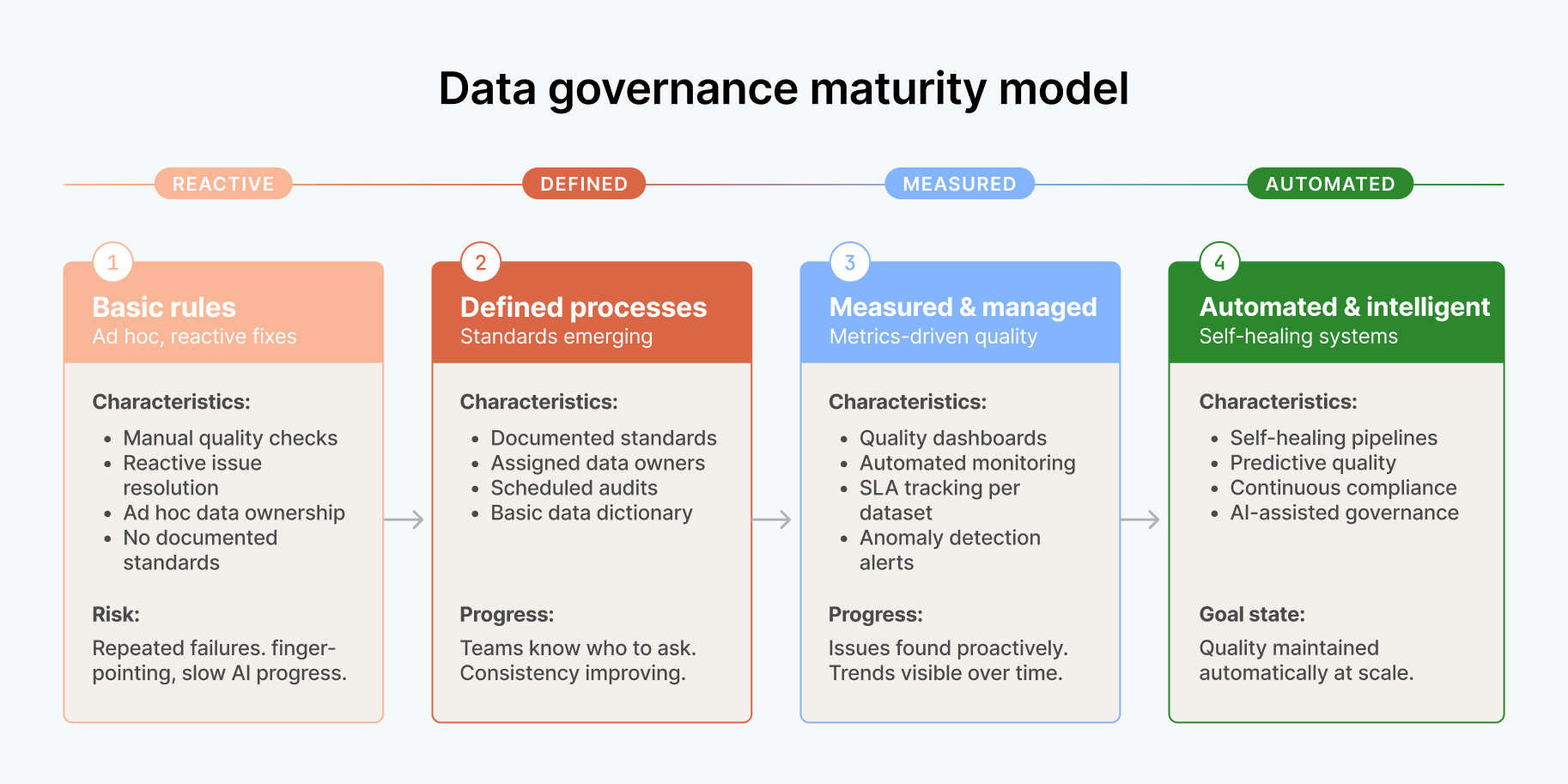
Überlegen Sie, was ein Agent tatsächlich tut. Er greift auf Daten über verschiedene Systeme hinweg zu. Er verknüpft Datensätze, die unterschiedliche Zugriffsrechte haben könnten. Er erzeugt Ausgaben, die von Personen eingesehen werden könnten, die keinen Zugriff auf die zugrunde liegenden Quelldaten haben sollten. Er trifft Entscheidungen oder gibt Empfehlungen, die einen Audit-Trail erfordern. Ohne in die Datenschicht integrierte Governance geben Sie einem autonomen System im Wesentlichen einen Generalschlüssel zu Ihren Unternehmensdaten und hoffen, dass es diesen verantwortungsvoll nutzt.
Zugriffsrechte müssen mit den Daten mitreisen und dürfen nicht nur auf der Anwendungsebene verbleiben. Spaltenbasierte Sicherheit, zeilenbasiertes Filtern und rollenbasierte Zugriffsrichtlinien müssen durchgesetzt werden, unabhängig davon, ob ein Mensch oder ein Agent die Abfrage ausführt. Die Datenherkunft muss sichtbar sein, damit Sie, wenn ein Agent eine Zahl erzeugt, diese bis zu ihrer Quelle zurückverfolgen und verstehen können, wie sie abgeleitet wurde. Und die Datenklassifizierung muss explizit sein, damit der Agent weiß, welche Datensätze er für eine bestimmte Aufgabe verwenden darf und welche nicht.
PwC-Umfrage zu verantwortungsvoller KI 2025 ergab, dass fast 60 % der Führungskräfte angaben, dass verantwortungsvolle KI-Praktiken den ROI und die Effizienz steigern, aber fast die Hälfte räumte ein, dass die Umsetzung dieser Prinzipien in operative Prozesse eine große Herausforderung bleibt. Die Kluft zwischen Absicht und Ausführung ist enorm. Agenten-KI vergrößert diese Kluft, weil Agenten nicht innehalten, um zu fragen: „Darf ich diesen Datensatz verwenden?“ Sie nutzen ihn einfach.
Der BARC Trend Monitor bestätigt dies: Richtige Entscheidungen können nur auf der Grundlage zuverlässiger, konsistenter Daten getroffen werden. Für Agenten bedeutet „zuverlässig und konsistent“ auch „reguliert“. Eine ungeregelte Datenschicht ist nicht nur ein Compliance-Risiko. Sie ist ein Leistungsengpass, denn die Alternative zu Governance ist die manuelle Überprüfung jeder Agentenausgabe. Und das untergräbt den gesamten Zweck der Automatisierung.
Aktualität ist unerlässlich, kein Luxus
Eine Dimension der Datenqualität verdient für die Agenten-KI besondere Beachtung: die Aktualität.
Ein Dashboard, das einmal täglich aktualisiert wird, ist für die meisten Geschäftsberichte ausreichend. Ein wöchentlicher Pipeline-Lauf ist für die Trendberichterstattung angemessen. Aber ein Agent, der Empfehlungen gibt, Fragen beantwortet oder Workflows auslöst, arbeitet nach einer anderen Uhr. Wenn ein Kunde sein Abonnement vor 2 Stunden gekündigt hat und der Agent immer noch Upselling-Strategien auf der Grundlage von Daten von gestern empfiehlt, ist das nicht nur ungenau. Es ist peinlich. Und in regulierten Branchen könnte es ein Compliance-Verstoß sein.
Die Anforderungen an die Aktualität variieren je nach Anwendungsfall, aber die Richtung ist klar: Agenten benötigen Daten, die die Realität zum Zeitpunkt der Abfrage widerspiegeln, nicht die Realität des letzten Batch-Laufs. Das bedeutet nicht, dass alles in Echtzeit sein muss. Es bedeutet, dass Sie die Aktualitätsanforderungen jedes Agenten-Workflows verstehen und Pipelines aufbauen müssen, die diese erfüllen. Ein Bestandsagent benötigt nahezu Echtzeit-Bestandsdaten. Ein Agent für die Quartalsplanung kann mit täglichen Snapshots arbeiten. Der Fehler besteht darin, eine einzige Aktualisierungsfrequenz auf alles anzuwenden und zu hoffen, dass es ausreicht.
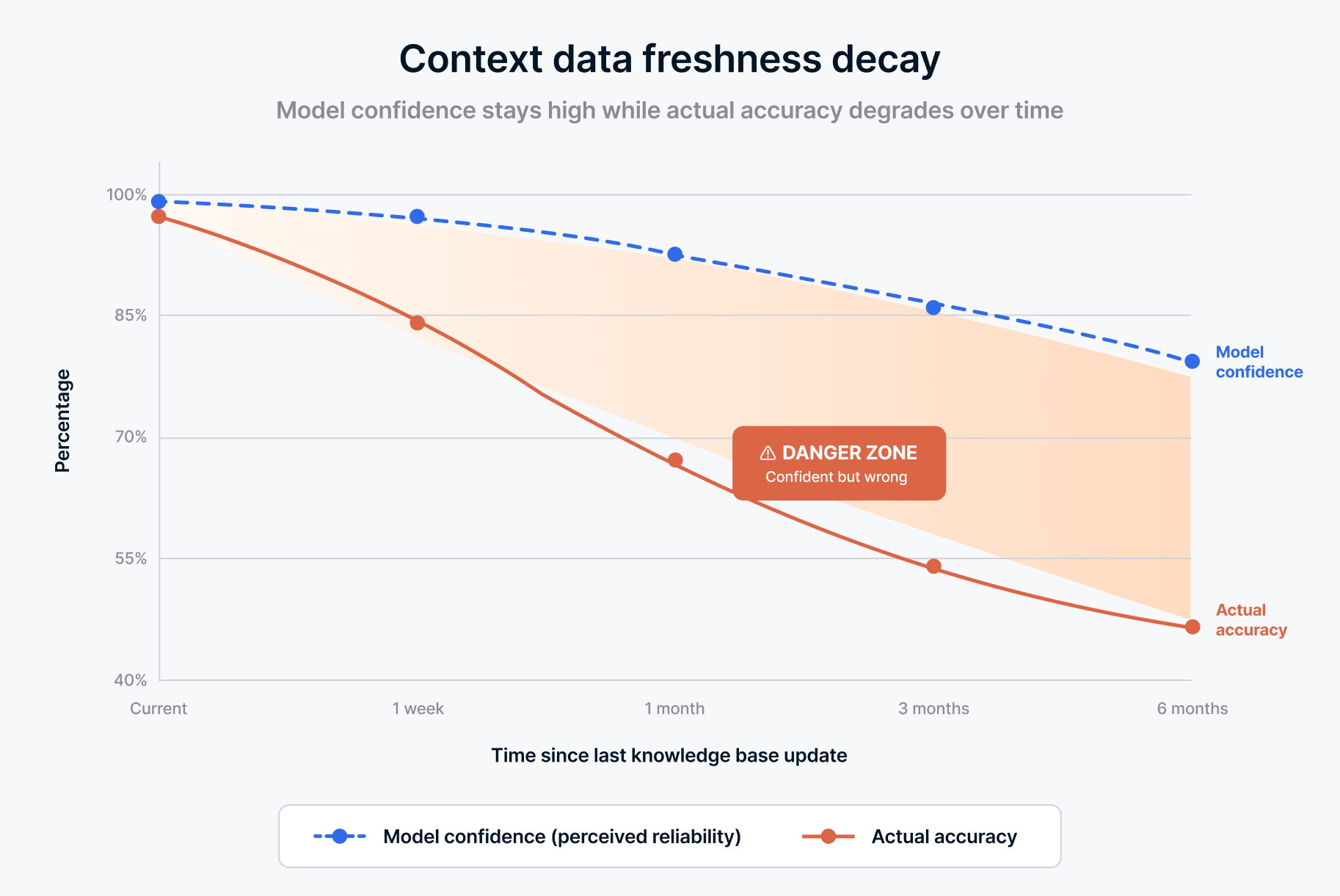
Der Wandel hin zu einer verwalteten Dateninfrastruktur hilft hier. Wenn Ihre Integrationsschicht die Aktualität als konfigurierbaren Parameter pro Quelle (und nicht als universellen Batch-Job) handhabt, können Sie das Pipeline-Verhalten an die Agentenanforderungen anpassen, ohne Ihre Architektur jedes Mal neu aufbauen zu müssen, wenn jemand einen neuen Anwendungsfall implementiert.
Was das für Datenteams bedeutet
Wenn Sie als Datenverantwortlicher beobachten, wie Ihr Unternehmen Agenten-Pilotprojekte startet, wissen Sie bereits, wohin die Reise geht. Die Modelle werden besser werden. Die Frameworks werden reifen. Die Orchestrierungstools werden sich verbessern. Aber all das spielt keine Rolle, wenn die Datengrundlage nicht vorhanden ist.
Die Arbeit, die Agenten zum Erfolg führt, ist dieselbe, die Datenteams seit Jahren fordern: zuverlässige Integration über verschiedene Quellen hinweg, konsistente Datenqualität, klare Geschäftsdefinitionen und eine starke Governance. Der Unterschied besteht darin, dass Agenten die Kosten dafür sichtbar machen, nicht diese Arbeit zu tun, auf eine Weise, wie es Dashboards nie taten. Ein schlechtes Dashboard wird ignoriert. Ein schlechter Agent agiert auf Basis schlechter Daten und erzeugt Konsequenzen, die sich im gesamten Unternehmen auswirken.
Das sind eigentlich gute Nachrichten für Datenteams. Jahrelang wurde Data Engineering als notwendige, aber unglamouröse Infrastruktur betrachtet, während die KI- und ML-Teams im Rampenlicht standen. Agentische KI kehrt diese Dynamik um. Die Qualität der Datenschicht ist nun der größte einzelne Prädiktor dafür, ob eine millionenschwere KI-Initiative erfolgreich ist oder zu einem weiteren Punkt auf der „Lessons Learned“-Folie wird.
Die Organisationen, die Dateninfrastruktur als Grundlage ihrer KI-Strategie (und nicht als nachträglichen Einfall) betrachten, werden diejenigen sein, die über die Pilotphase hinauskommen. Diese 95%ige Misserfolgsquote aus der MIT-Studie ist nicht unvermeidlich. Sie ist das Ergebnis, wenn man Agenten auf Datenschichten aufbaut, die nicht für den autonomen Verbrauch bereit waren.
Ihre Agenten sind nicht durch das Modell begrenzt. Sie sind durch die Daten begrenzt. Beheben Sie die Grundlage, und die 95 % beginnen zu schrumpfen.
Bereit, die Datengrundlage zu schaffen, die Ihre KI-Agenten benötigen? Erfahren Sie, wie der Managed Data Lake Service von Fivetran integrierte, verwaltete Daten liefert, um Ihre agentischen KI-Initiativen voranzutreiben.
[CTA_MODULE]
.svg)
Verwandte Beiträge
Kostenlos starten
Schließen auch Sie sich den Tausenden von Unternehmen an, die ihre Daten mithilfe von Fivetran zentralisieren und transformieren.









