Comment l'accès aux data influence les performances des agents IA
.png)

Demandez à un agent IA de répondre à une question commerciale, et vous en apprendrez peut-être accidentellement davantage sur votre infrastructure data que sur l'agent lui-même. Le modèle ne bute pas parce qu'il n'est pas assez intelligent. Il échoue parce qu’il ne trouve pas ce dont il a besoin, ne peut pas se fier à ce qu’il trouve ou ne comprend pas ce que les data signifient réellement dans le contexte spécifique de votre entreprise.
C'est le modèle qui se cache derrière des milliards de dollars d'investissements infructueux dans l'IA. Et si vous êtes responsable data ou ingénieur data, c'est à vous de résoudre ce problème.
[CTA_MODULE]
Le taux d'échec dont personne ne veut parler
Les chiffres sont sans appel. L'initiative NANDA du MIT a publié « The GenAI Divide: State of AI in Business 2025 », une étude basée sur 150 entretiens avec des cadres, des enquêtes auprès de 350 employés et l'analyse de 300 déploiements publics d'IA. Le chiffre le plus marquant : 95 % des projets pilotes d'IA générative en entreprise n'ont eu aucun impact mesurable sur le compte de résultat. Il ne s'agit pas d'une « performance inférieure aux attentes ». Aucun impact mesurable.
Gartner prévoit que plus de 40 % des projets d'IA agentique seront annulés d'ici fin 2027, invoquant des coûts croissants, une valeur commerciale incertaine et des contrôles des risques inadéquats. Il ne s'agit pas d'expériences sous-financées. Selon Gartner, les dépenses mondiales en IA devraient dépasser les 2 000 milliards de dollars en 2026, soit une croissance de 37 % d'une année sur l'autre. L'argent est là. Les résultats, eux, ne suivent pas.
L'étude « 2025 CEO Study » de l'IBM Institute for Business Value le formule de manière encore plus crue : seules 16 % des initiatives en matière d'IA ont réussi à se déployer à l'échelle de l'entreprise. Cela représente un grand nombre de démonstrations de faisabilité qui n'ont finalement pas prouvé grand-chose.
Alors, qu'est-ce qui ne va pas ? Les chercheurs du MIT ne pointent pas du doigt la qualité des modèles, mais ce qu'ils appellent un « déficit d'apprentissage » causé par des workflows fragiles et un manque d'apprentissage contextuel. En clair : l'IA ne parvient pas à se connecter aux data dont elle a besoin, et lorsqu'elle y parvient, elle ne comprend pas ce que ces data signifient.
Il s'agit d'un problème lié aux data, et non d'un problème lié à l'IA.
L'intégration est le premier point de blocage
La qualité d'un agent IA dépend de la qualité des data auxquelles il a accès. Si vos data client se trouvent dans Salesforce, vos indicateurs d'utilisation des produits dans un data warehouse, vos tickets de support dans Zendesk et vos data financières dans un système ERP, l'agent est confronté au même problème que celui que vos analystes rencontrent depuis des années. Il travaille avec des fragments.
La différence, c'est qu'un analyste humain sait qu'il doit appeler l'équipe financière et demander la feuille de calcul manquante. Un agent ne sait pas improviser face à des lacunes dans les data. Soit il hallucine une réponse qui semble convaincante, soit il renvoie une réponse techniquement correcte mais inutile en pratique, car il travaille avec une vision incomplète de la situation.
L'intégration des data n'est pas une nouveauté. Les équipes data relient les sources entre elles depuis des décennies. Mais les exigences relatives à l'IA agentique sont fondamentalement différentes de celles des tableaux de bord et des rapports.
Un tableau de bord BI peut tolérer des mises à jour par lots, un rapprochement manuel et quelques lacunes connues. Un analyste remarque un chiffre étrange, contacte l'équipe data sur Slack et obtient la vraie réponse avant la fin de la journée. Un agent autonome ne peut pas faire cela. Il a besoin d'un accès fiable et programmatique à des data consolidées, et ces data doivent être à jour. Pas « mises à jour chaque nuit ». À jour.
Réfléchissez à ce que fait réellement un agent lorsque vous lui demandez d'analyser le taux d’attrition des clients. Il a besoin des data de comptes issues de votre CRM, des événements d'utilisation des produits issus de la database de votre application, de l'historique des tickets de support de votre plateforme d’assistance, des data de facturation de votre système financier, et probablement de certains indicateurs d'engagement issus de vos outils marketing. Si l'une de ces sources manque, est obsolète ou incohérente avec les autres, l'analyse de la perte de clientèle de l'agent est compromise. Pas manifestement erronée. Subtilement erronée. Et une erreur subtile est pire, car les gens agissent en fonction de celle-ci.
C'est là que la plomberie joue un rôle crucial. Si vos pipelines data sont fragiles, vos agents héritent de cette fragilité. Si votre couche d'intégration perd des enregistrements, produit des doublons ou accuse un retard de plusieurs heures alors que l'entreprise a besoin de quelques minutes, le résultat de l'agent reflète chacune de ces failles. Gartner a constaté que la mauvaise qualité des data coûte à elle seule aux organisations en moyenne 12,9 millions de dollars par an. Imaginez maintenant la multiplication de ce coût si l’on donne à un système autonome le pouvoir d'agir en fonction de data erronées sans intervention humaine.
Les organisations qui tirent une réelle valeur de l'IA agentique ne sont pas celles qui disposent des modèles les plus sophistiqués. Ce sont celles qui disposent d'une intégration de data fiable et automatisée, regroupant les sources en une seule couche interrogeable. Pas d'assemblage manuel. Pas de savoir tribal pour déterminer quel tableau est le « bon ». Pas de « demande à Sarah, elle sait où se trouvent les bonnes data ». Juste des data propres, consolidées et accessibles qu'un agent peut interroger sans supervision humaine.
Des data propres ou des hallucinations convaincantes (faites votre choix)
Il existe un type particulier de défaillance qui empêche les ingénieurs data de dormir la nuit : l'agent qui répond avec assurance, mais de manière erronée. Ce n'est pas un plantage. Ce n'est pas un message d'erreur. C’est une réponse erronée formulée avec une grammaire parfaite et une conviction totale.
Cela se produit lorsque les data sous-jacentes ne sont pas propres. Des enregistrements clients en double. Des formats de date incohérents. Des valeurs nulles là où il devrait y avoir des data réelles. Des chiffres d'affaires qui ne concordent pas d'un système à l'autre, car chaque équipe les calcule différemment. L'agent ne sait rien de tout cela. Il traite tout ce qu'il trouve et produit un résultat.
Le rapport « Data, BI and Analytics Trend Monitor 2026 » de BARC, qui a interrogé plus de 1 500 professionnels, a révélé que la gestion de la qualité des data avait retrouvé la première place parmi les priorités de tous les répondants. Pour les agents IA, une qualité de data élevée est plus importante que jamais pour éviter les hallucinations, les biais et les recommandations erronées. Il ne s'agit pas d'une préoccupation théorique. C'est l'obstacle le plus fréquemment cité à la mise en place d'une IA qui fonctionne réellement.
La qualité des data pour les agents est plus rigoureuse que la qualité des data pour les tableaux de bord. Un tableau de bord comportant quelques lignes obsolètes est gênant. Un agent qui prend une décision d'achat en fonction de data de stocks obsolètes coûte cher. Un agent qui transfère la réclamation d'un client à la mauvaise équipe en raison d'un enregistrement en double pose un problème de confiance qui s'aggrave à chaque fois que cela se produit.
Les critères habituels s'appliquent toujours : exactitude, exhaustivité, cohérence et actualité. Mais les enjeux sont plus importants, car l'utilisateur des data n'est pas un être humain capable d'exercer son jugement et de tenir compte du contexte. C'est un système qui agira en fonction de tout ce qu'il reçoit. La qualité de vos data n'est plus seulement un problème d'hygiène. C'est un frein à la performance de chaque agent que vous déployez.
Le contexte fait la différence entre une démo et la production
La plupart des projets d'agents se heurtent à l'obstacle décrit ici même par l'étude du MIT. L'agent peut accéder aux data. Les data sont raisonnablement propres. Mais l'agent produit toujours des réponses qui font grimacer vos experts en la matière. Il confond le chiffre d'affaires brut et le chiffre d'affaires net. Il traite les trimestres fiscaux comme des trimestres calendaires. Il ne sait pas que le terme « utilisateurs actifs » n'a pas la même signification pour votre équipe produit que pour votre équipe marketing.
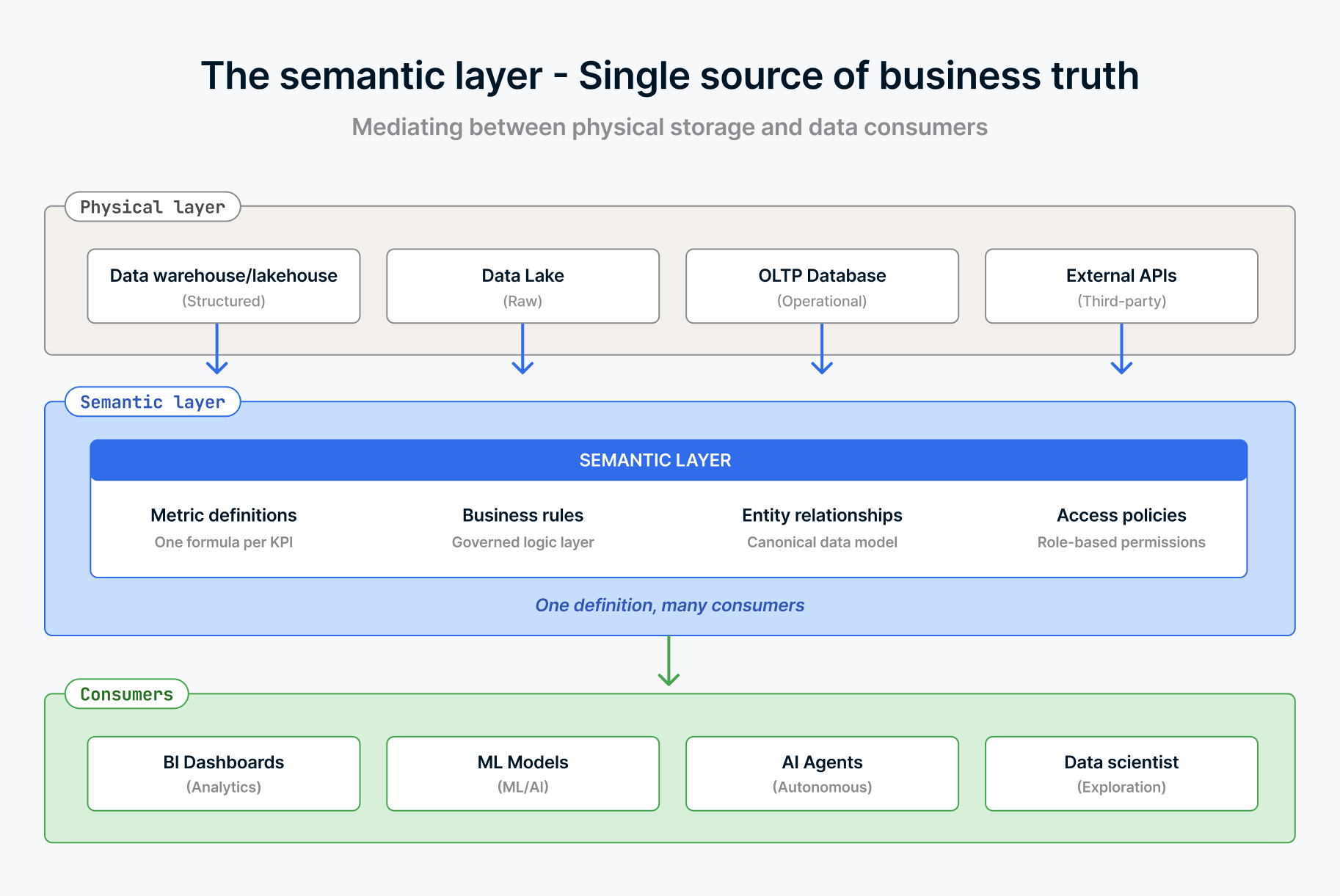
C'est le problème de contexte. L'accès brut aux tables et aux colonnes ne suffit pas. L'agent doit comprendre ce que les data signifient pour votre entreprise.
AtScale a publié un scénario qui illustre parfaitement cela. Le service financier déclare un chiffre d'affaires de 10,2 millions de dollars dans Power BI. Le service marketing affiche un chiffre d'affaires de 10,4 millions de dollars dans Tableau. Un copilote IA affiche un chiffre d'affaires de 9,8 millions de dollars dans Slack. Chaque chiffre est « correct » compte tenu de sa source et de sa logique de calcul. Mais ils se contredisent. Le service financier comptabilise les recettes après les retours. Le service marketing comptabilise la valeur brute des transactions. L’agent IA, dépourvu de tout ce contexte, calcule les tendances qu’il détecte dans les tableaux de transactions brutes. Parfois, il inclut des data de test. Parfois, il exclut les ventes internationales. Tout dépend de la formulation de la question, et dans tous les cas, son « raisonnement » n'est peut-être même pas déterministe.
Un humain gère cette ambiguïté grâce à la connaissance institutionnelle et aux réunions de rapprochement. Un agent a besoin que ces connaissances soient codées et accessibles. C'est le rôle d'une couche sémantique. Elle définit la manière dont les indicateurs sont calculés, associe les termes métier à des transformations de data spécifiques et garantit que le terme « chiffre d’affaires » a une seule et même signification, quel que soit le demandeur (ou l’objet de la demande).
Les prévisions de Gartner pour 2026 en matière de data et d'analyse considèrent désormais les couches sémantiques universelles comme une infrastructure critique, les plaçant au même rang que les plateformes data et la cybersécurité. C'est une avancée significative par rapport au statut de simple « plus ».
Mais les couches sémantiques ne sont pas le seul moyen de fournir du contexte. La bonne approche dépend du type de data et du type de question.
Les compétences des agents — des instructions structurées qui indiquent à un agent comment interagir avec des outils ou des sources de data spécifiques — remplissent un rôle similaire pour l'exécution des tâches. Un agent doté d’une compétence bien définie pour interroger votre warehouse de data client sait quelles tables consulter, quelles jointures effectuer et quels filtres appliquer. Il ne le devine pas. Il suit une compréhension codifiée de votre modèle data. Les compétences sont particulièrement utiles pour les requêtes structurées et reproductibles où la logique métier est bien définie et où les relations entre les data sont stables.
Pour les data non structurées, les embeddings et les magasins vectoriels fournissent un autre type de contexte. Lorsqu'un agent doit récupérer des documents pertinents, des politiques internes, des analyses antérieures ou des conversations Slack pour étayer une réponse, la recherche vectorielle lui permet de trouver du contenu sémantiquement similaire sans s'appuyer sur des correspondances exactes de mots-clés. Un agent d'assistance capable d'extraire le guide de dépannage pertinent en fonction de la signification de la question d'un client (et pas seulement des mots-clés) est fondamentalement plus performant qu'un agent qui en est incapable.
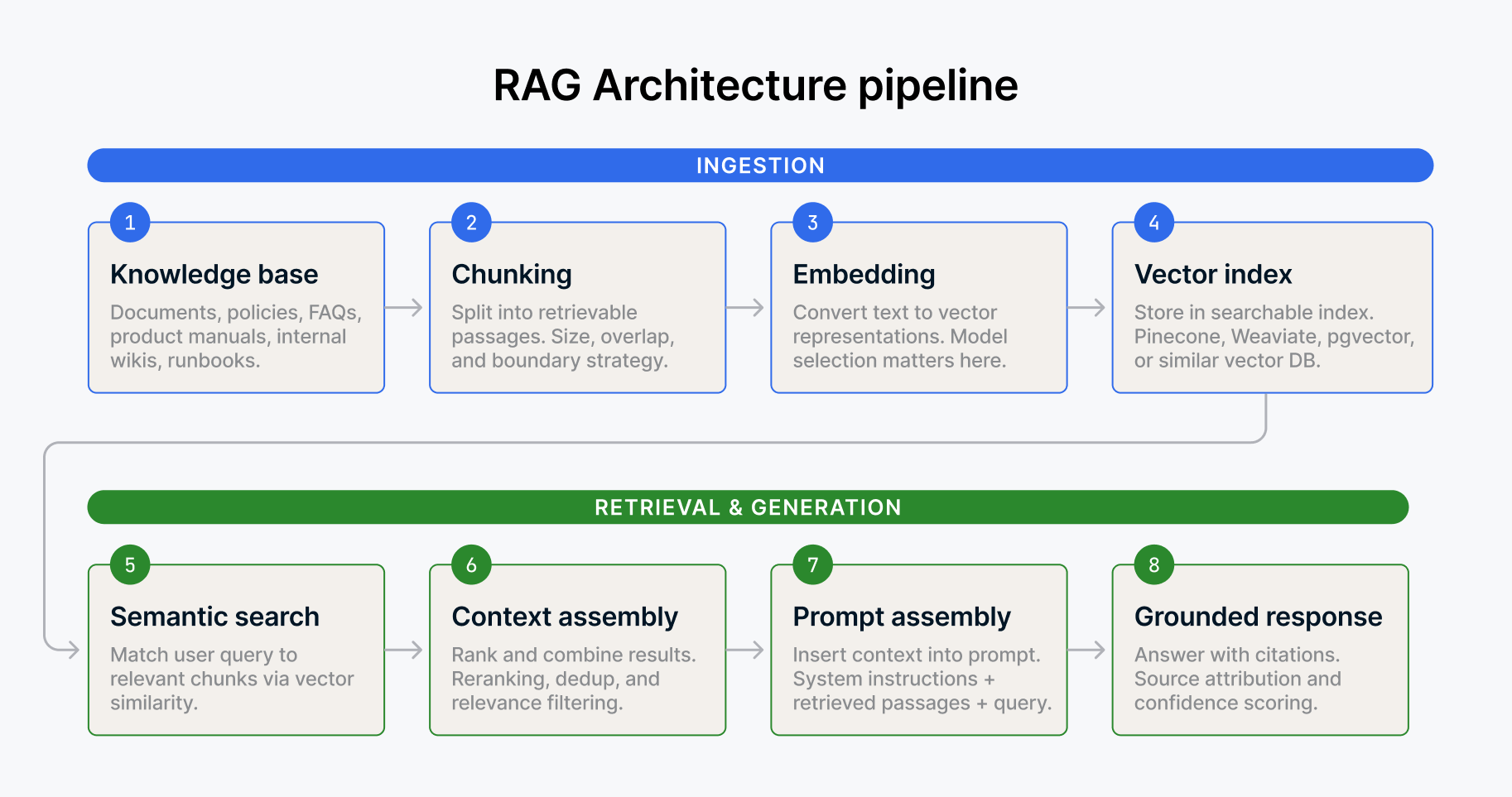
Des protocoles tels que le MCP (Model Context Protocol) offrent aux agents un moyen standardisé de se connecter à des outils et des sources de data externes, réduisant ainsi le travail d'intégration sur mesure qui ralentit tant de déploiements. Au lieu de créer des connecteurs sur mesure pour chaque outil avec lequel un agent doit interagir, le MCP fournit une interface commune. Considérez-le comme l'USB-C de la connectivité des agents. Cela ne rend pas l'agent plus intelligent, mais rend son accès aux data et aux outils nettement plus fiable et cohérent.
Toutes ces approches ont un point commun : elles offrent à l'agent une compréhension structurée de vos data qui va au-delà du simple accès aux tables brutes. Sans contexte, vous obtenez une démonstration qui impressionne les dirigeants dans une salle de réunion. Avec le contexte, vous obtenez un système qui produit des réponses auxquelles vos experts font réellement confiance.
L'étude « Data and AI Market Lens » d'ISG a révélé que plus d'un tiers des organisations estimaient que leurs initiatives de modélisation sémantique affichaient des performances inférieures aux attentes. La technologie fonctionne. C'est la mise en œuvre qui est difficile. Mais ce sont les organisations qui investissent dans la mise en place de cette couche contextuelle (quelle que soit la manière dont elles la développent) qui comblent le fossé entre la phase pilote et la mise en production.
La gouvernance n'est pas facultative
Il est tentant de considérer la gouvernance comme un élément que l'on ajoute a posteriori, une fois que l'agent est opérationnel. C'est l’inverse qu’il faut faire. Pour un agent IA, la gouvernance est une condition préalable, pas une tâche secondaire.
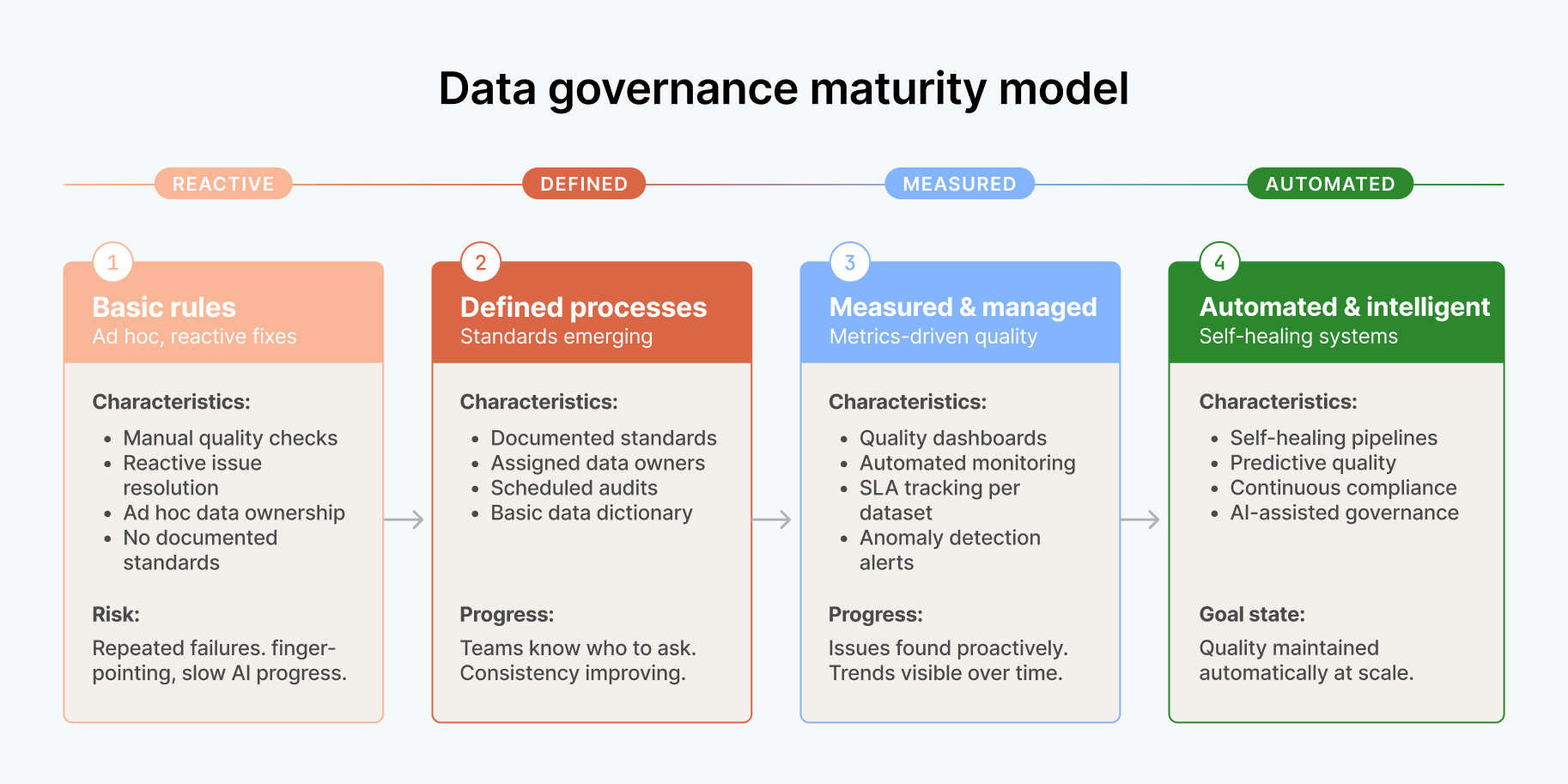
Réfléchissez à ce que fait réellement un agent. Il accède à des data provenant de différents systèmes. Il fusionne des ensembles de data pouvant être soumis à des contrôles d'accès différents. Il produit des résultats qui pourraient être consultés par des personnes qui ne devraient pas avoir accès aux data sources sous-jacentes. Il prend des décisions ou formule des recommandations qui nécessitent une piste d'audit. Sans gouvernance intégrée à la couche de data, vous donnez en substance à un système autonome un passe-partout pour accéder aux data de l’entreprise, en espérant qu'il les utilise de manière responsable.
Les contrôles d'accès doivent accompagner les data dans leur déplacement, et ne pas se limiter à la couche applicative. La sécurité au niveau des colonnes, le filtrage au niveau des lignes et les politiques d'accès basées sur les rôles doivent être appliqués, que la requête soit exécutée par un humain ou par un agent. La traçabilité data doit être visible afin que, lorsqu'un agent produit un chiffre, vous puissiez remonter jusqu'à sa source et comprendre comment il a été obtenu. Et la classification des data doit être explicite afin que l'agent sache quels ensembles de data il peut et ne peut pas utiliser pour une tâche donnée.
L'enquête 2025 « Responsible AI » de PwC a révélé que près de 60 % des dirigeants ont déclaré que les pratiques d'IA responsable augmentaient le ROI et l'efficacité, mais près de la moitié ont admis que la transformation de ces principes en processus opérationnels restait un défi majeur. Le fossé entre l'intention et l'exécution est énorme. L'IA agentique creuse cet écart, car les agents ne s'arrêtent pas pour se demander : « Ai-je le droit d'utiliser cet ensemble de data ? » Ils l'utilisent, tout simplement.
Le Trend Monitor de BARC le confirme : des décisions correctes ne peuvent être prises que sur la base de data fiables et cohérentes. Pour les agents, « fiables et cohérentes » inclut « gérées ». Une couche de data non gérées ne représente pas seulement un risque de non-conformité. C'est un point de blocage en termes de performances, car l'alternative à la gouvernance consiste à examiner manuellement chaque résultat produit par un agent. Et cela va à l'encontre de l'objectif même de l'automatisation.
L’actualité des data est essentielle, ce n'est pas un luxe
Un aspect de la qualité des data mérite une attention particulière dans le cadre de l'IA agentique : l'actualité.
Un tableau de bord actualisé une fois par jour convient pour la plupart des analyses commerciales. Un pipeline exécuté hebdomadairement est suffisant pour les rapports sur les tendances. Mais un agent qui formule des recommandations, répond à des questions ou déclenche des workflows fonctionne selon un rythme différent. Si un client a résilié son abonnement il y a deux heures et que l'agent continue de recommander des stratégies de vente incitative basées sur les data d'hier, ce n'est pas seulement inexact. C'est embarrassant. Et dans les secteurs réglementés, cela pourrait constituer une violation de la conformité.
Les exigences en matière d'actualité des data varient selon les cas d'utilisation, mais la direction à suivre est claire : les agents ont besoin de data qui reflètent la réalité au moment de la requête, et non la réalité telle qu'elle était lors de la dernière exécution par lots. Cela ne signifie pas que tout doit être en temps réel. Cela signifie que vous devez comprendre les exigences en termes d’actualité de chaque workflow d'agent et mettre en place des pipelines qui y répondent. Un agent d’inventaire a besoin de niveaux de stock en temps quasi réel. Un agent de planification trimestrielle peut travailler avec des instantanés quotidiens. L'erreur consiste à appliquer une seule fréquence d’actualisation à tout et à espérer que cela suffise.
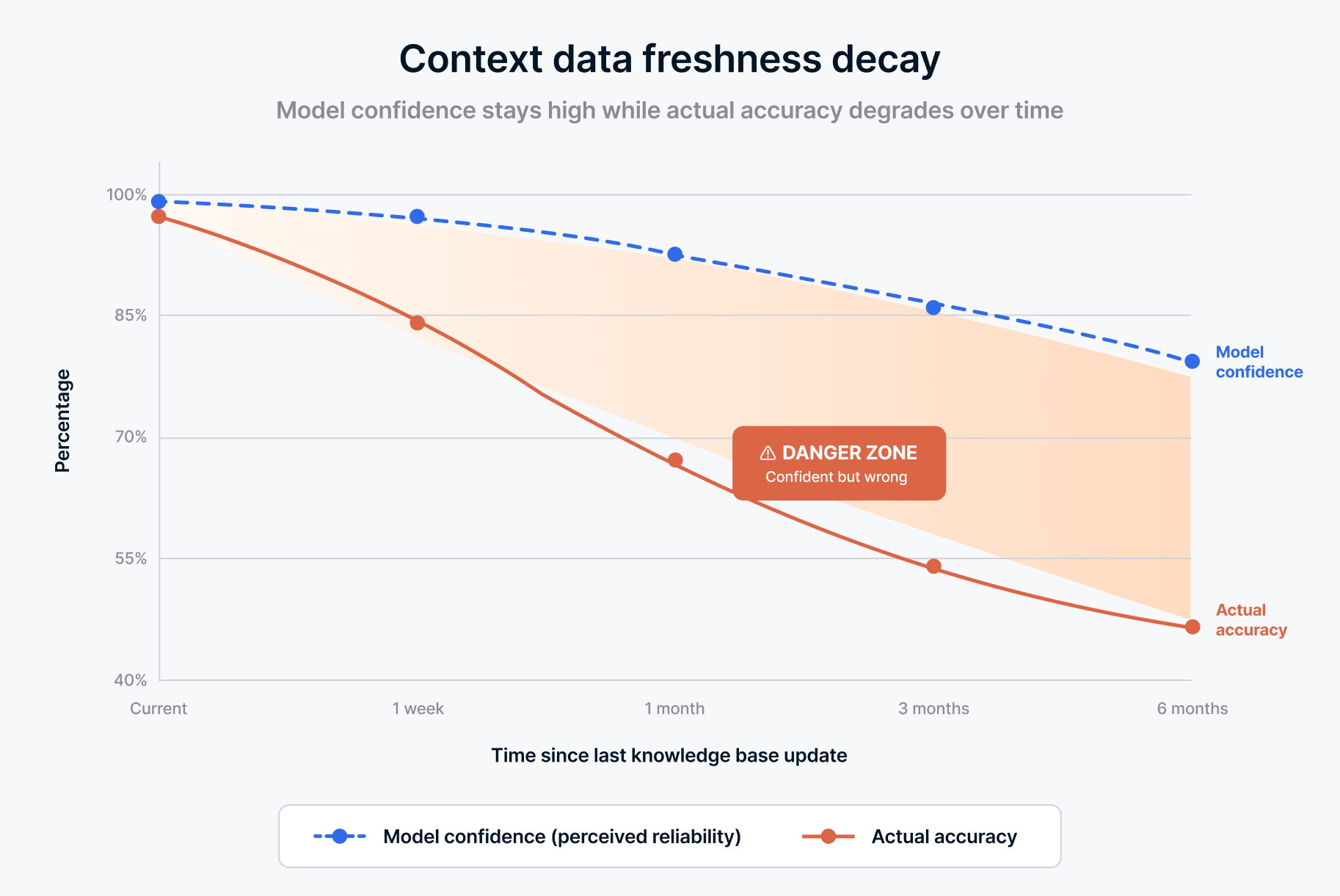
L'évolution vers une infrastructure data gérée est ici utile. Lorsque votre couche d'intégration gère l'actualité comme un paramètre configurable par source (et non comme une tâche batch universelle), vous pouvez adapter le comportement du pipeline aux exigences de l'agent sans avoir à recréer votre architecture à chaque fois qu'un nouveau cas d'utilisation est déployé.
Ce que cela signifie pour les équipes data
Si vous êtes un responsable data et que vous voyez votre organisation lancer des projets pilotes d'IA agentique, vous savez déjà où cela mène. Les modèles vont s'améliorer. Les frameworks gagneront en maturité. Les outils d'orchestration s'amélioreront. Mais tout cela n'aura aucune importance si le socle de data n'est pas en place.
Le travail qui garantit le succès des agents est le même que celui que les équipes data prônent depuis des années : une intégration fiable entre les sources, une qualité de data constante, des définitions métier claires et une gouvernance solide. La différence est que les agents rendent visible le coût de ne pas effectuer ce travail d'une manière que les tableaux de bord n'ont jamais pu faire. Un mauvais tableau de bord est ignoré. Un mauvais agent agit en fonction de data erronées et entraîne des conséquences qui se répercutent sur l'ensemble de l'entreprise.
C'est en réalité une bonne nouvelle pour les équipes data. Pendant des années, l'ingénierie data a été traitée comme de la plomberie (nécessaire mais peu glamour) tandis que les équipes d'IA et de ML étaient sous les feux de la rampe. L'IA agentique renverse cette dynamique. La qualité de la couche de data est désormais le principal facteur permettant de prédire si une initiative d'IA de plusieurs millions de dollars sera couronnée de succès ou deviendra un élément de plus sur la diapositive des « leçons apprises ».
Les organisations qui considèrent l'infrastructure data comme le fondement de leur stratégie d'IA (et non comme un élément secondaire) seront celles qui dépasseront la phase pilote. Ce taux d'échec de 95 % révélé par l'étude du MIT n'est pas inévitable. C'est ce qui se produit lorsque l'on crée des agents sur des couches de data qui n'étaient pas prêtes pour une utilisation autonome.
Vos agents ne sont pas limités par le modèle. Ils sont limités par les data. Renforcez le socle, et ce taux de 95 % commencera à diminuer.
Prêt à créer le socle de data dont vos agents IA ont besoin ? Découvrez comment le Service de gestion de datalake de Fivetran fournit des data intégrées et gérées pour optimiser vos initiatives d'IA agentique.
[CTA_MODULE]
.svg)
Articles associés
Commencer gratuitement
Rejoignez les milliers d’entreprises qui utilisent Fivetran pour centraliser et transformer leur data.









