Setting up your first data pipeline
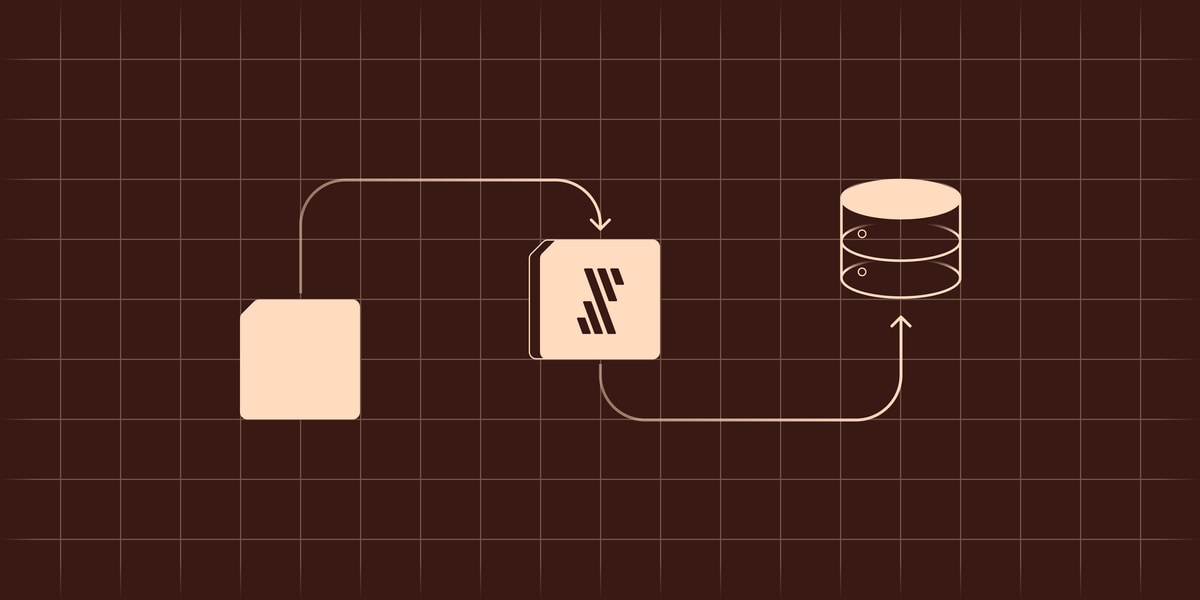

Data pipelines are processes and tools that bring raw data from sources, such as applications, databases and files to destinations, such as data warehouses and data lakes. They are the main processes and tools involved in data integration and data movement, which are fundamental to supporting all analytical and operational uses of data.
Why (and when) do you need a data pipeline?
Data is an essential resource for all organizations. With full visibility into internal operations, customer interactions and product usage and performance, you can derive insights to support decision making at all levels of your organization. You need a data pipeline when in-app reporting tools, spreadsheets and ad hoc reporting of all kinds are no longer capable of answering critical business questions, specifically those that require combining data from different data sources.
Why ELT instead of ETL?
Historically, data pipelines used a process of Extract, Transform, Load (ETL) to load data into a data warehouse. This was necessary when severe technological constraints prevailed. Before the modern cloud, compute, storage and network bandwidth were very scarce resources. However, ETL is a brittle, configuration-heavy process. By transforming data before loading it, analysts are forced to predict the data models they will use beforehand. This means that data engineers and analysts must often design and build complicated processes and workflows upfront in order to use data, and then redesign and rebuild them whenever reporting needs change. ETL is also vulnerable to stoppages when upstream schemas change, necessitating redesigns of the pipeline.
With the growth of the cloud, compute, storage and internet bandwidth are now considerably more accessible. With the removal of old technological constraints, data engineering talent becomes the bottleneck for data integration. In the present day, data pipelines should use an Extract, Load, Transform (ELT) process. This new sequence means analysts can ingest data in its original form, then transform it using cloud-based technologies to extract insights without limits. This new approach to data integration expedites the process of data ingestion and radically lowers the barrier to entry for comprehensive analytics.
More importantly, by decoupling transformations from the extraction and loading stages, ELT can produce standardized outputs that analysts can massage into finished data models within the destination, usually a data warehouse. With that change, a fully-managed, automated solution can produce these standardized outputs, rather than a costly, bespoke, homespun system.
Choosing the right data warehouse
Before you choose a data integration tool, you should consider your destination. Your data warehouse will be the repository of record for your organization’s structured data. Different data warehouses offer different features and tradeoffs. Here are nine criteria you should focus on:
- Centralized vs. decentralized data storage – Does the data warehouse store all of its data on one machine, or is it distributed across multiple machines, trading redundancy for performance?
- Elasticity – Can the data warehouse scale compute and storage resources up and down quickly? Are compute and storage independent from each other or coupled together?
- Concurrency – How well does the data warehouse accommodate multiple simultaneous queries?
- Load and query performance – How quickly can you complete typical loads and queries?
- Data governance and metadata management – How does the data warehouse handle permissions and regulatory compliance?
- SQL dialect – Which dialect of SQL does the data warehouse use? Does it support the kinds of queries you want to make? Will your analysts have to adjust the syntax they currently use?
- Backup and recovery support – If your data warehouse somehow gets corrupted or breaks, can you easily revert to a previous state?
- Resilience and availability – What about preventing database failures in the first place?
- Security – Does the data warehouse follow current security best practices?
As a repository for your data, your choice of data warehouse is likely the most financially impactful part of your data stack. Upgrades and changes to your data warehouse involve data migrations and are very costly.
Choosing the right data integration tool
There are many data integration tools in the market, and their technical approaches and feature sets vary significantly. Here are the foremost factors to consider when choosing a data integration tool:
- Data connector quality – Data connectors are the basic elements of a data pipeline, referring to every discrete mechanism that moves data from a source to a destination. Take these factors into account when evaluating connector quality:
Open-source vs. proprietary – There are open-source connectors for a wider range of data sources, but proprietary connectors tend to be of higher quality and integrate more seamlessly with other elements of a data stack.
Standardized schemas and normalization – Data from API feeds is not usually normalized. Normalization fosters data integrity, while standardization enables outsourcing and automation by allowing a provider to support the same solution for a wide range of customers.
Incremental vs. full updates – Incremental updates using logs or other forms of change detection allow for more frequent updates that do not interfere with business operations. - Support for sources and destinations – Does the tool support your sources and destinations? Does the provider offer a way for customers to suggest new sources and destinations? Do they routinely add new ones?
- Configuration vs. zero-touch – Zero-touch, fully managed tools are extremely accessible, with connectors that are standardized, stress-tested and maintenance-free. By contrast, configurable tools require expensive allocations of engineering time.
- Automation – Integration tools should remove as much manual intervention and effort as possible. Consider whether a tool offers features like automated schema migration, automatic adjustment to API changes and continuous sync scheduling. Machines are generally cheaper than humans, and the purpose of automation is to exploit this advantage.
- Transforming within the data warehouse – With an ELT architecture, analysts can perform SQL-based transformations in an elastic, cloud-based warehouse. SQL-based transformations also offer the possibility of jumpstarting analytics using off-the-shelf SQL-based data models.
- Recovery from failure – You don’t want to ever permanently lose data. Find out whether your prospective tools are idempotent and perform net-additive integration.
- Security and compliance – These are key areas, both in terms of data protection and public perception. Specifically, learn how prospective tools deal with:
- Regulatory compliance
- Limited data retention
- Role-based access
- Column blocking and hashing
Fivetran provides a fully automated ELT data pipeline built to help companies automate extracting and loading data into their data warehouses in a cloud-agnostic manner. The key to getting started with ELT is to find a tool with maximum off-the-shelf functionality and minimal custom configuration and setup.
Whatever data integration tool you choose, find one that is usable out-of-the-box. From the perspective of the end user, the ideal data movement workflow should consist of little more than:
- Selecting connectors for data sources from a menu
- Supplying credentials
- Specifying a schedule
- Pressing a button to begin execution
Choosing the right business intelligence tool
Business intelligence tools enable you to easily build reports and dashboards, but different tools have different strengths and weaknesses. Here are the key factors to consider:
- Seamless integration with cloud data warehouses – Is it easy to connect this BI tool to your cloud data warehouse of choice?
- Ease of use and drag-and-drop interfaces – Ease of use is especially important to popularize data-driven decisions across your organization.
- Automated reporting and notifications – Writing reports by hand can become tedious for data scientists and analysts. Does the BI tool allow you to schedule reports to publish automatically? What about alerting users when the data changes?
- Ability to conduct ad hoc calculations and reports by ingesting and exporting data files – Your analysts and data scientists might sometimes want to explore data without the overhead of having to go through a data warehouse first.
- Speed, performance and responsiveness – Basic quality-of-life considerations are important, like dashboards and visualizations loading in a timely manner.
- Modeling layer with version control and development mode – Does the BI tool allow your analysts to work collaboratively by sharing data models and code?
- Extensive library of visualizations – Pie charts, column charts, trendlines and other basic visualizations can only take you so far. Does the BI tool feature more specialized visualizations like heat maps or radar charts? Does it allow you to build your own custom visualizations?

While the above factors are important initial considerations, they’re just the tip of the data integration iceberg. To learn more about getting started with data integration, check out our ultimate guide to data integration.
[CTA_MODULE]
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







