Automating credit card fraud detection with Google BigQuery ML and Fivetran



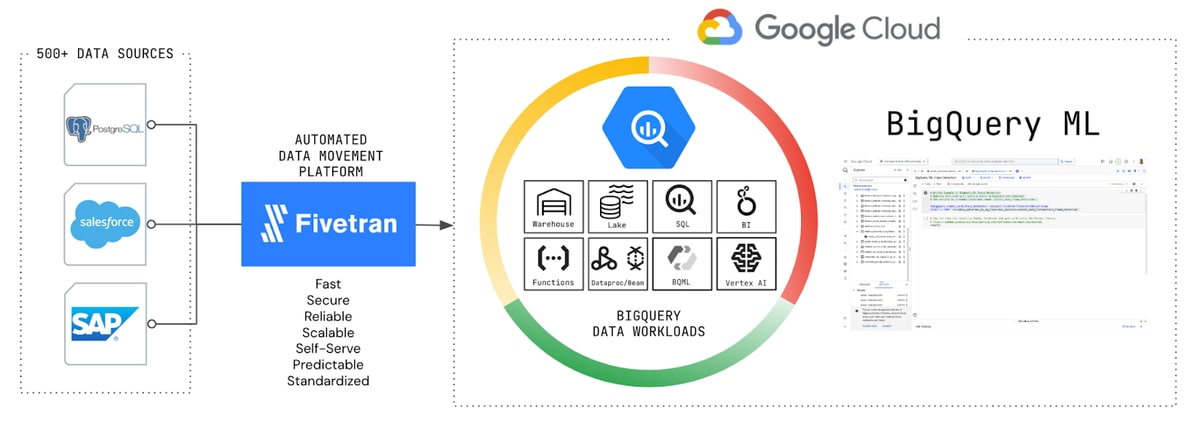
In this second part of our blog series, we'll demonstrate how to set up an automated fraud detection system using Google's BigQuery ML and Fivetran. This blog post demonstrates setting up an automated fraud detection system using BigQuery ML and Fivetran. We'll move a credit card transactions dataset from a source database to BigQuery using Fivetran, then run BigQuery ML classification experiments to predict fraudulent transactions. This solution enables centralized data, modernized infrastructure and scalable ML applications for combating credit card fraud, all without requiring setup or maintenance.
Set up BigQuery as a Fivetran destination
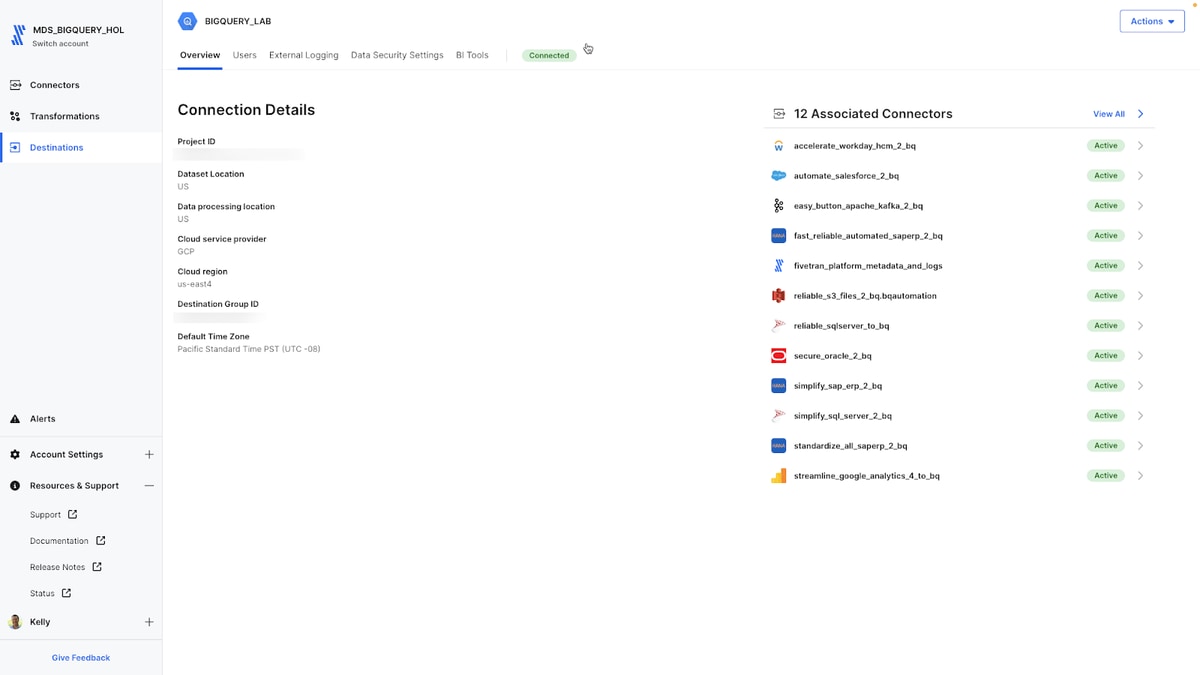
Fivetran accounts support multiple Google Cloud destinations. Setting up a BigQuery destination is quick and easy – just provide your BigQuery Project ID and grant the BigQuery User role to the Fivetran service account in the project. You can also choose your preferred Google Cloud processing region.
Add a Fivetran to BigQuery connector
I already have multiple data sources flowing into BigQuery, including SAP, SQL Server and Oracle operational databases, Salesforce, GA4, Kafka, S3 and Workday. Fivetran has over 500 source connectors out of the box across multiple categories, including databases, applications, file systems and event systems, and that number is growing by the day.
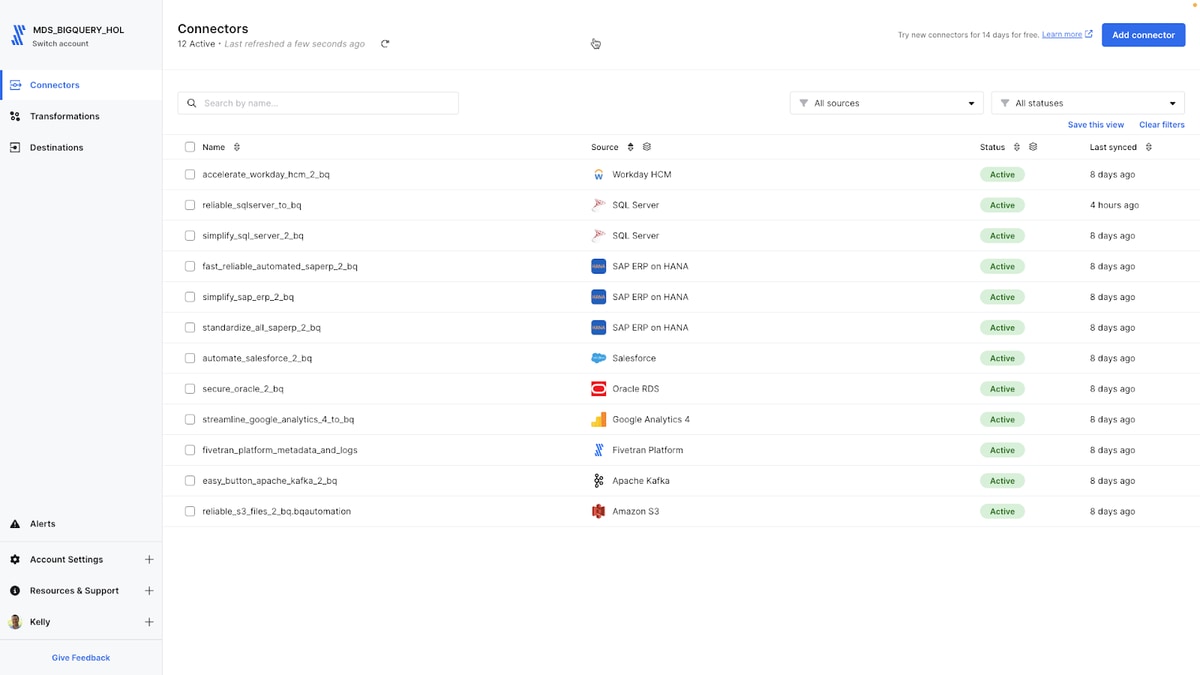
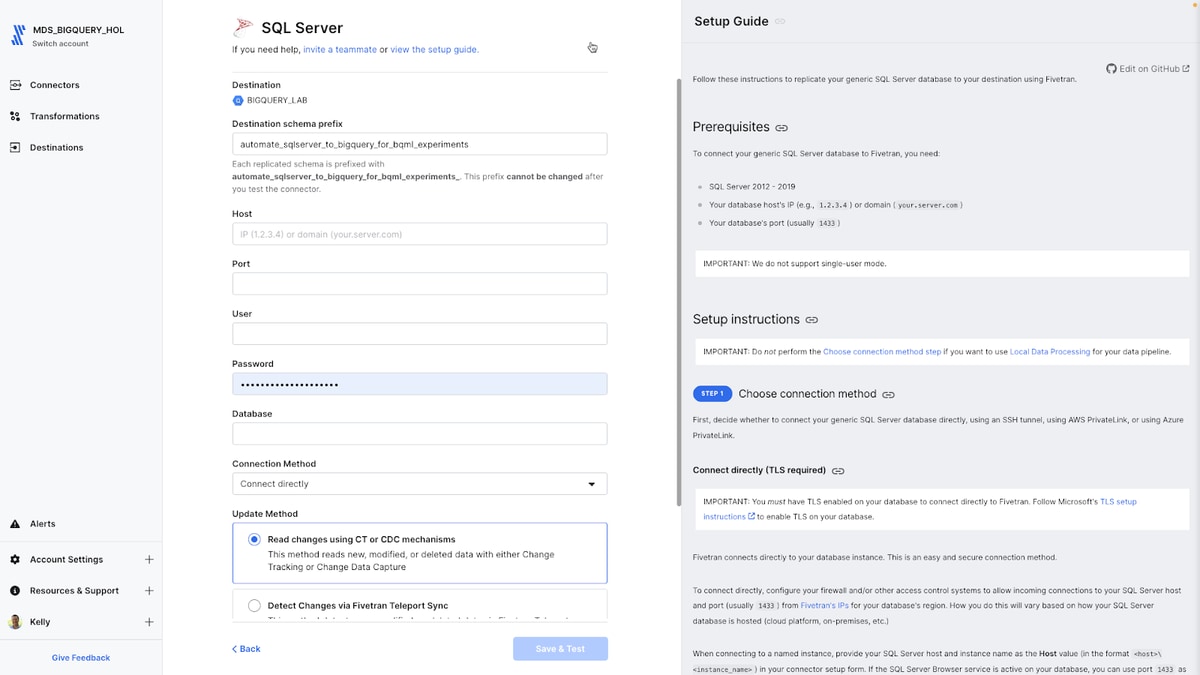
I want to move a credit card transactions dataset from a Microsoft SQL Server database to BigQuery for use with BigQuery ML. I'll add a SQL Server connector using Fivetran, which offers various options for connecting and moving relational databases to Google Cloud, including SaaS standard connectors, HVA hybrid connectors and LDP. For this dataset, I'll use a Fivetran SaaS standard database connector with log-free change detection.

Fivetran provides detailed and step by step documentation for quickly moving SQL Server data into BigQuery. The SQL Server Setup Guide outlines the steps and each source and destination page includes details on version support, configuration, features, limitations, sync overview, schema information and type transformations. I've linked the SQL Server source detail page for your reference.

The SQL Server setup page in Fivetran has a setup guide to help you quickly connect to SQL Server. You choose the destination schema name (e.g., "automate_sqlserver_to_BigQuery_for_bqml_experiments") and provide authentication details for the SQL Server database. Fivetran handles the initial sync and incremental updates using either CT/CDC or Fivetran Teleport (log-free change detection).
Fivetran encrypts all data in motion using Transport Layer Security (TLS) for direct connections to SQL Server, ensuring encryption and authentication. Any data temporarily stored in the Fivetran service is encrypted with AES256.
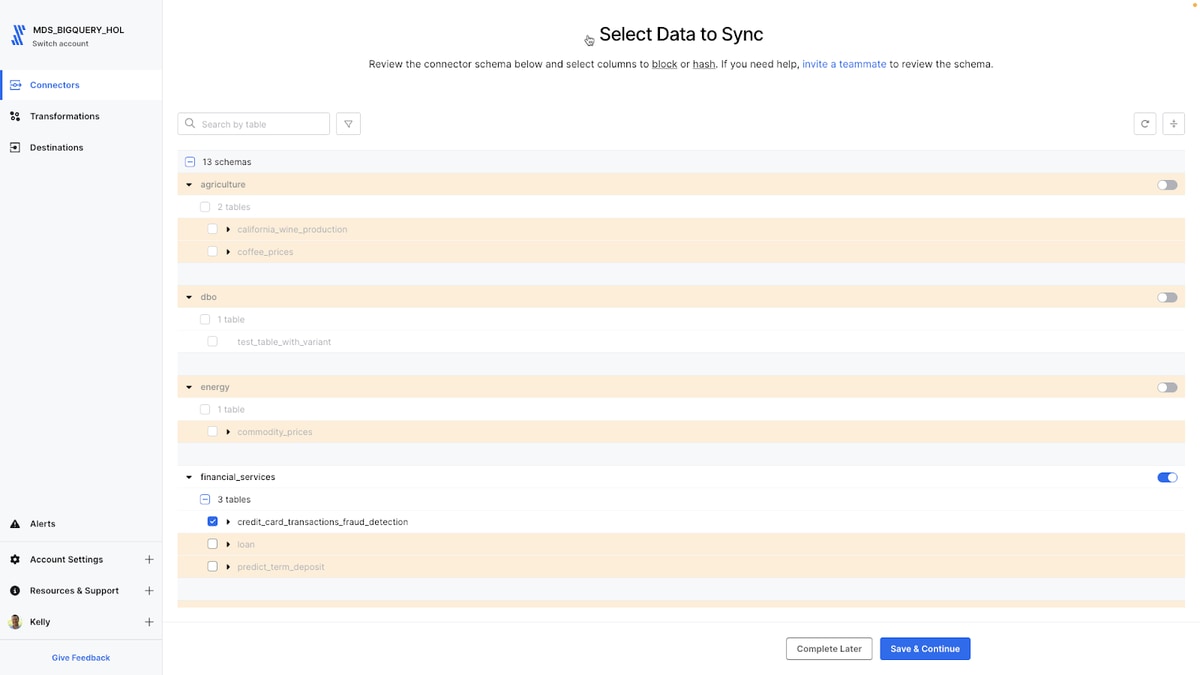
Selecting the credit card transactions dataset to use with BigQuery ML
After successfully connecting to SQL Server, Fivetran fetches the available source schemas, tables and columns. Instead of syncing all 13 schemas, I'll select only the "financial_services" schema and the "credit_card_transactions_fraud_detection" table for my fraud detection use case, blocking the other schemas and tables from moving to BigQuery. Fivetran also offers column-level hashing for data privacy and anonymization of PII data while still allowing the hashed columns to be used in downstream ML workflows.
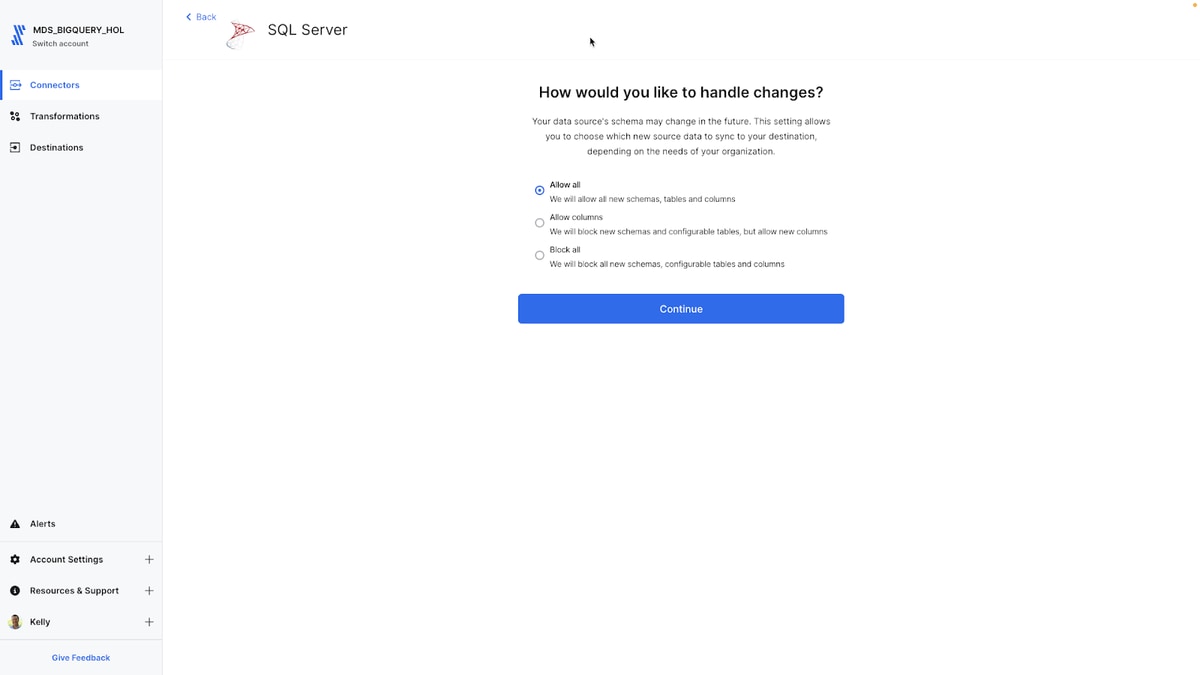
Incremental changes and schema drift
Fivetran then needs to know how I want to handle incremental changes since the schema may change in the future. I’m going to “Allow all”, but I have a range of options here. Any and all DML and DDL changes are automatically captured by Fivetran and delivered to BigQuery - no coding is required and I can determine the polling frequency to the SQL Server source for the change detection and subsequent movement to BigQuery.
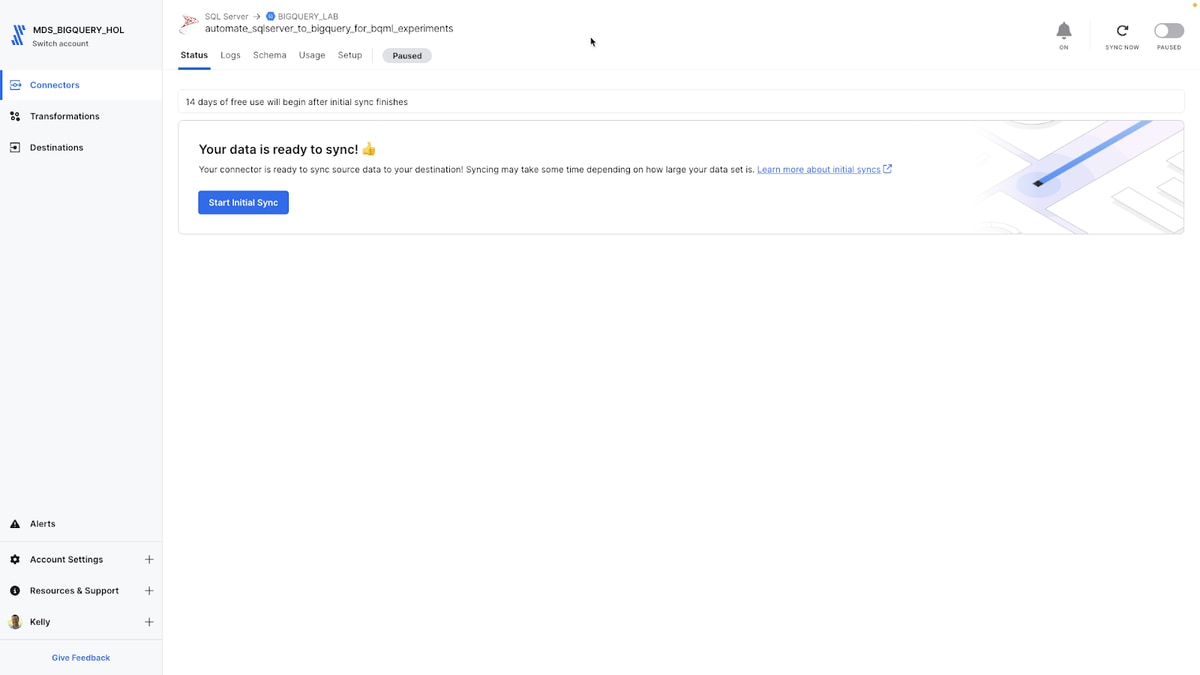
Starting the initial sync from SQL Server to BigQuery
After saving and testing the selections, I'm ready to sync the credit card transactions dataset from SQL Server to BigQuery. Fivetran moves the data to BigQuery, completes error checking and doesn't store any data in its service. It only retains a cursor to the sync point for the next incremental sync.
This was a small dataset, just a single table and you can see that the initial sync was completed very quickly.
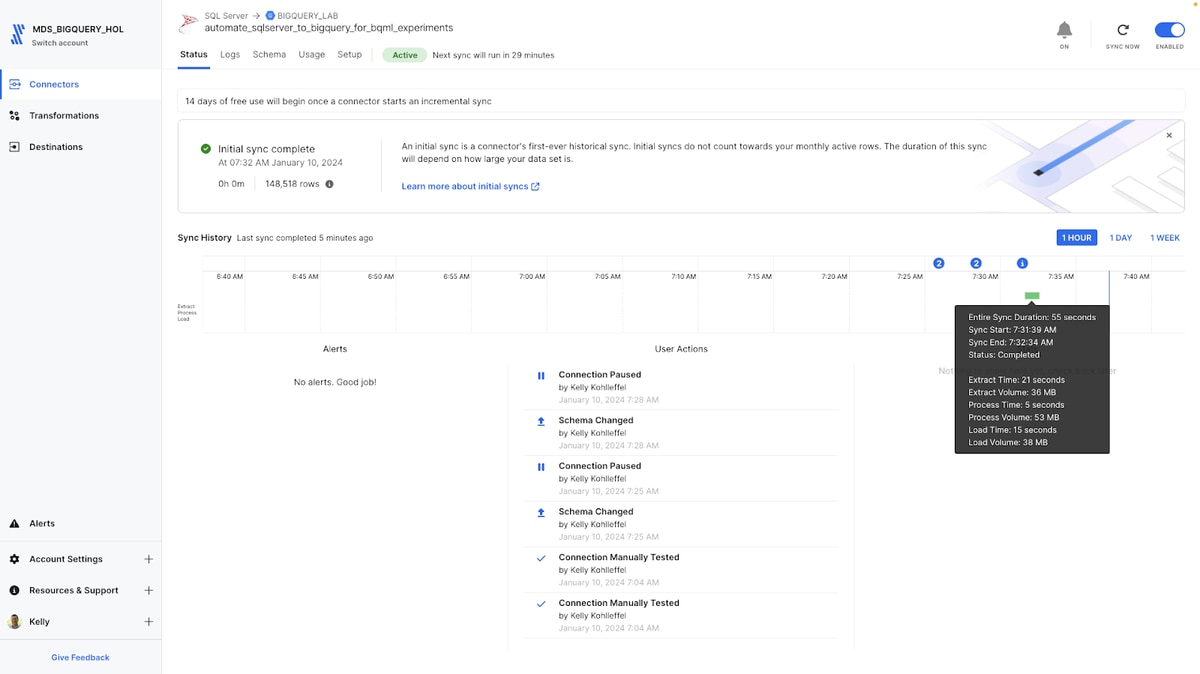
Fivetran automatically sets up incremental CDC syncs for the connector, defaulting to every six hours. However, you can adjust the polling time from one minute to 24 hours, depending on your use case and the data freshness requirements for the downstream BigQuery ML fraud detection application.
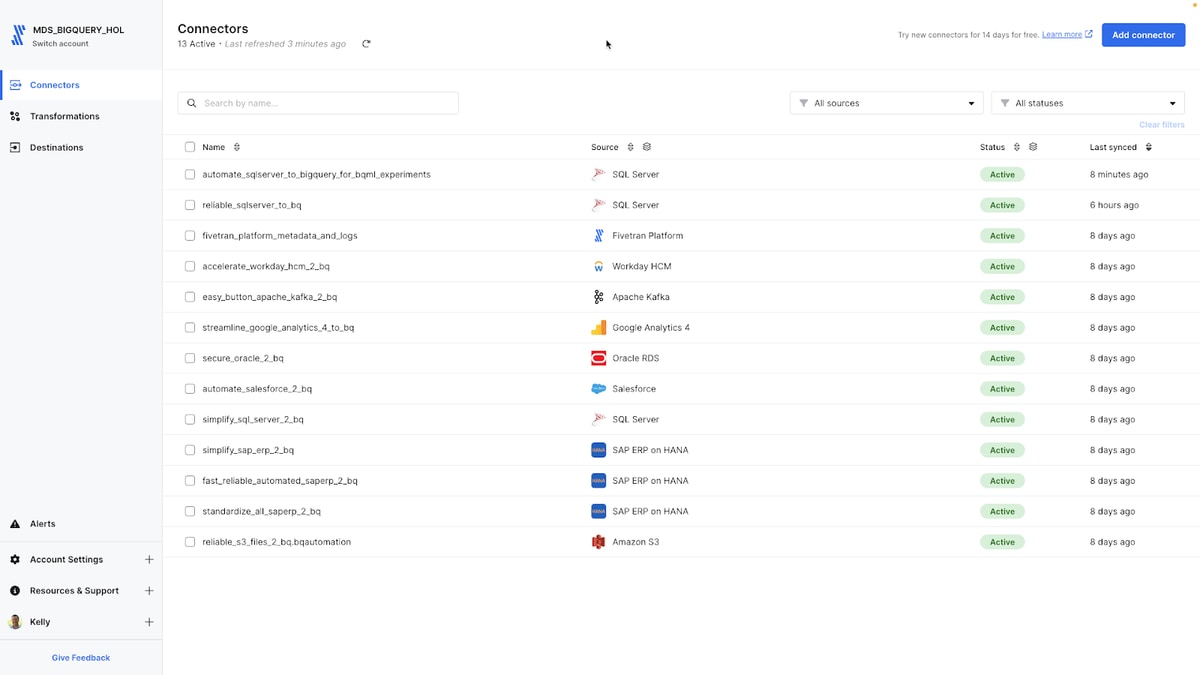
My SQL Server connector (automate_sqlserver_to_BigQuery_for_bqml_experiments) is now in the list with all other connectors, and I have access to all of those data sources now in BigQuery.
Here’s the new credit card transactions dataset in BigQuery
I exported the credit card transactions dataset to my BigQuery project, which already contains various datasets like SAP, Salesforce and Google Analytics 4. Fivetran accurately replicates the source data in BigQuery, making it organized and ready for BigQuery ML experiments. A quick query on the new dataset shows what BigQuery ML will use for the fraud detection use case.

Building a fraud detection application in BigQuery ML
BigQuery ML lets you create and run machine learning (ML) models by using GoogleSQL queries. It also lets you access LLMs and Cloud AI APIs to perform artificial intelligence (AI) tasks like text generation or machine translation.
About the data
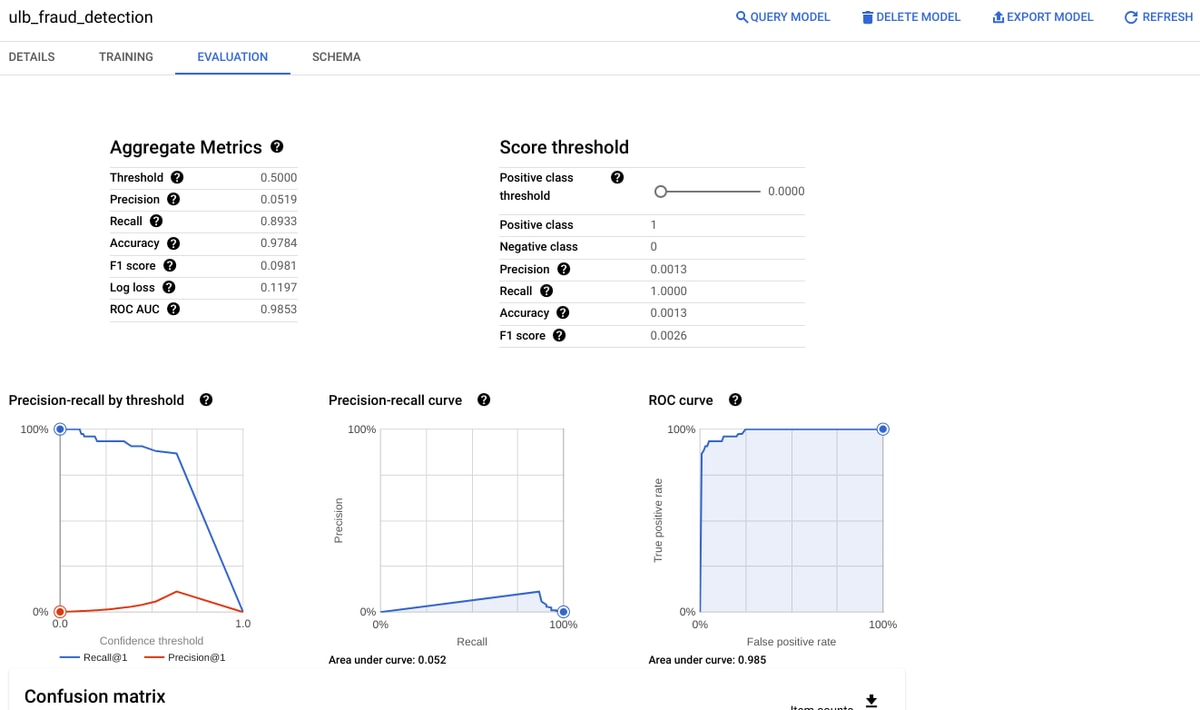
The dataset contains 284,807 European credit card transactions from September 2013, including 492 frauds (0.172%). It has 30 features: V1-V28 (PCA-transformed), 'Time' (seconds since first transaction), 'Amount' (transaction amount) and 'Class' (1 for fraud, 0 otherwise). The dataset was collected and analyzed by Worldline and the ULB Machine Learning Group ( http://mlg.ulb.ac.be) of ULB (Université Libre de Bruxelles for fraud detection research.
Creating the mdoel using BigQuery ML
In the Query window, type out the below query for model creation. Understand the key options with this statement. Explained in this link.
- INPUT_LABEL_COLS indicate the prediction label
- AUTO_CLASS_WEIGHTS are used for imbalanced datasets
- MODEL_TYPE would indicate the algorithm used; in this case, logistic regression
- DATA_SPLIT_METHOD indicates the split between the training and testing data
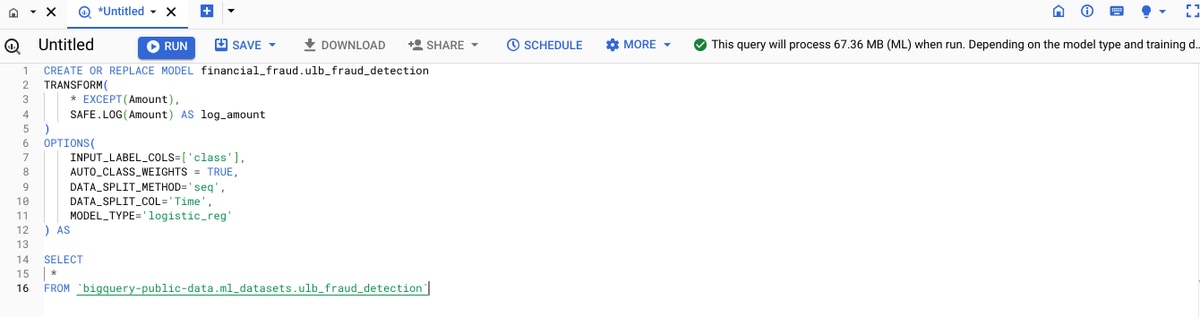
The model syntax is as follows:
CREATE OR REPLACE MODEL financial_fraud.ulb_fraud_detection
TRANSFORM(
* EXCEPT(Amount),
SAFE.LOG(Amount) AS log_amount
)
OPTIONS(
INPUT_LABEL_COLS=['class'],
AUTO_CLASS_WEIGHTS = TRUE,
DATA_SPLIT_METHOD='seq',
DATA_SPLIT_COL='Time',
MODEL_TYPE='logistic_reg'
) AS
SELECT
*
FROM `BigQuery-public-data.ml_datasets.ulb_fraud_detection`
Once you run the above query, the model is created as shown below:
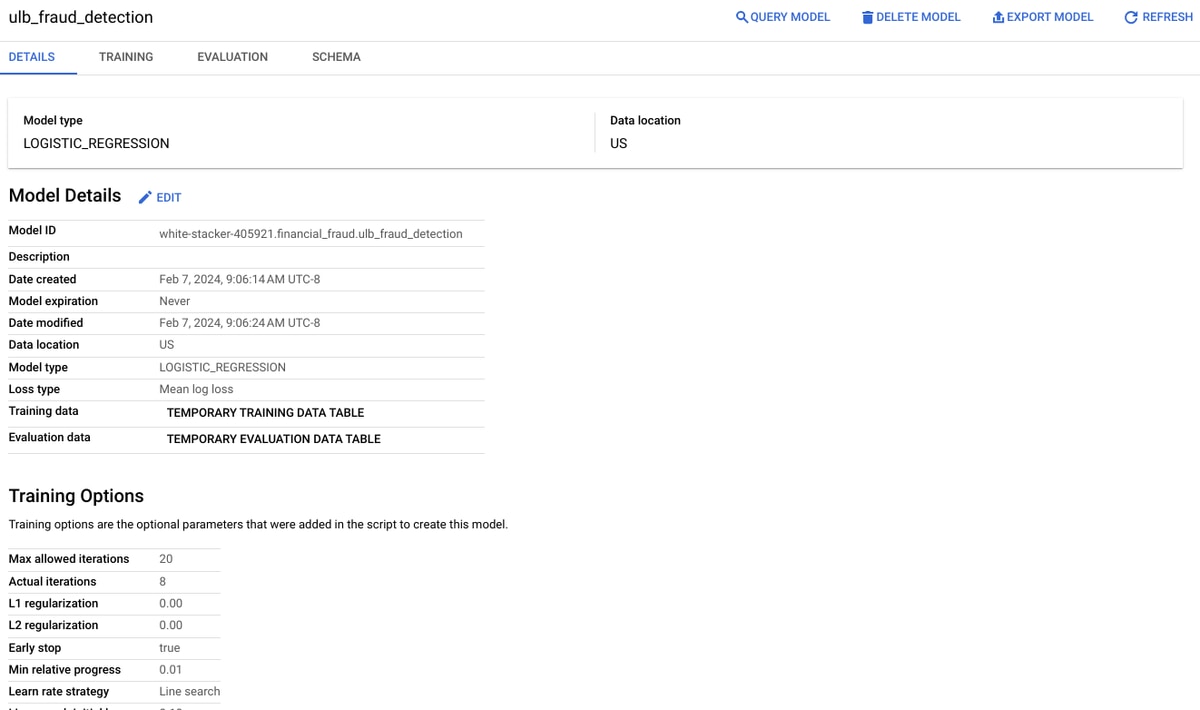
From the UI, we can evaluate the above model:
Using the model to predict fraud
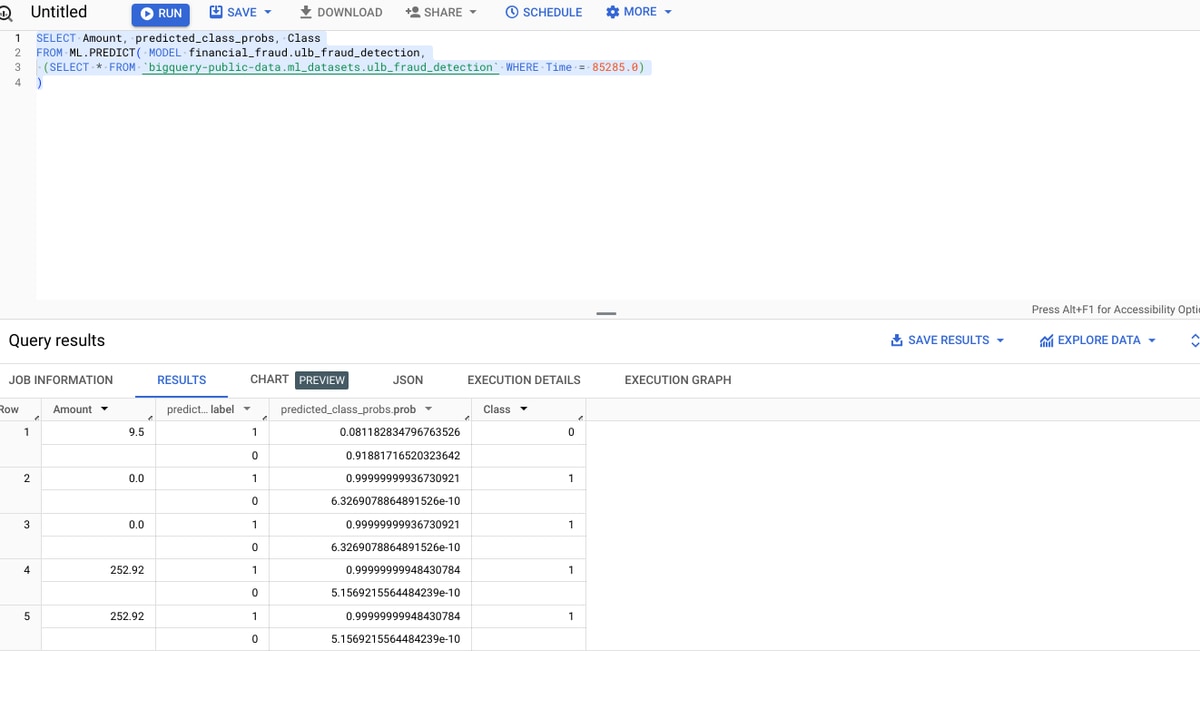
Running the below query can help predict fraudulent transactions. The transaction at this time threshold is known to be fraudulent. We are trying to evaluate that the prediction works.
SELECT Amount, predicted_class_probs, Class
FROM ML.PREDICT( MODEL financial_fraud.ulb_fraud_detection,
(SELECT * FROM `BigQuery-public-data.ml_datasets.ulb_fraud_detection` WHERE Time = 85285.0)
)
In this instance, we are displaying the amount with the associated probability of the label. The class column here indicates what the actual results were.
Get Started Now
Building a fraud detection ML app is easy with BigQuery, BigQuery ML and Fivetran. Fivetran standardizes and automates data movement to BigQuery, while BigQuery and BigQuery ML enable creating and running machine learning models using SQL queries. You can try Fivetran for free for 14-day free trial, and if you don't have BigQuery set up, Fivetran offers a managed BigQuery data warehouse service during the trial. Simply select “I don’t have my own warehouse” during the Fivetran trial setup. Fivetran is available on Google Cloud Marketplace.
About the authors
Kelly Kohlleffel leads the Fivetran Global Partner Sales Engineering organization, working with a broad ecosystem of technology partners and consulting services partners on modern data product and solution approaches. He also hosts the Fivetran Data Drip podcast where some of the brightest minds across the data community talk about their data journey, vision and challenges. Before Fivetran, he spent time at Hashmap and NTT DATA (data solution and service consulting), Hortonworks (in Hadoop-land) and Oracle. You can connect with Kelly on LinkedIn or follow him on Twitter.
Ankit Virmani is a data and ML specialist who focuses on developing and designing scalable, reliable and ethical AI/ML platforms for Google Cloud customers. He has over a decade of progressive work experience in the data and machine learning domain and is passionate about evangelizing the use of ethical and responsible AI.
[CTA_MODULE]
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







