Why Fivetran supports data lakes

Historically at Fivetran, we were somewhat skeptical of the data lake as a primary destination. In comparison to data warehouses, we considered data lakes to have had a number of serious disadvantages:
- At the small volumes of data used by many organizations, data warehouses were nearly as cost-effective as data lakes and nearly as capable of handling semi-structured data.
- Data lakes were not easy to govern or search through, and ran a real danger of turning into murky, unnavigable data “swamps”
- This murkiness could compound when using data lakes as a staging area for a data warehouse, introducing more complexity to an organization’s data architecture, an uncertain provenance for data assets and multiple sources of truth
Accordingly, we have long promoted the data warehouse as the essential destination for the modern data stack.
The case for the data lake
Three trends have since informed our changed position on data lakes.
First, our customers’ data needs have increased considerably in scale and volume, making the cost advantages in compute and storage offered by data lakes more meaningful. A growing number of customers have expressed interest in the easy scalability and cost savings offered by data lakes. For organizations that must accommodate large volumes of semi-structured (i.e. JSON) and unstructured data (i.e. media files), the data lake can serve as a better platform for a “single source of truth” than a data warehouse. Large-scale storage of semi-structured and unstructured data is essential for higher value data science pursuits, such as artificial intelligence and machine learning. After all, a larger volume of higher quality data, rather than the sophistication of an algorithm, is the single most important ingredient to building a well-functioning predictive model.
Second, data lakes are increasingly capable in terms of cataloging, governance and the handling of tabular, structured data — as well as security and regulatory compliance. High-performance table formats such as Apache Iceberg, an open table format for S3, offer benefits normally associated with data warehouses such as ACID compliance and row-and-column level querying and editing.
The third trend, a corollary to the second, is that the functions and capabilities of data warehouses and data lakes are increasingly consolidated under a common cloud data platform or data lakehouse. This simplifies an organization’s data architecture by obviating the need to maintain a separate data lake and data warehouse, using the data lake to stage all data while moving curated, filtered and transformed data from the data lake into the data warehouse.
The bottom line is that the data lake and its unique capabilities are here to stay and will remain an essential piece of many data architectures, even if it’s ultimately known by another name.
Why automated data movement unlocks the potential of the data lake
The challenges involved in moving data from sources such as applications, files, event streams and operational databases to data lakes are the same as those involved in moving data to data warehouses.
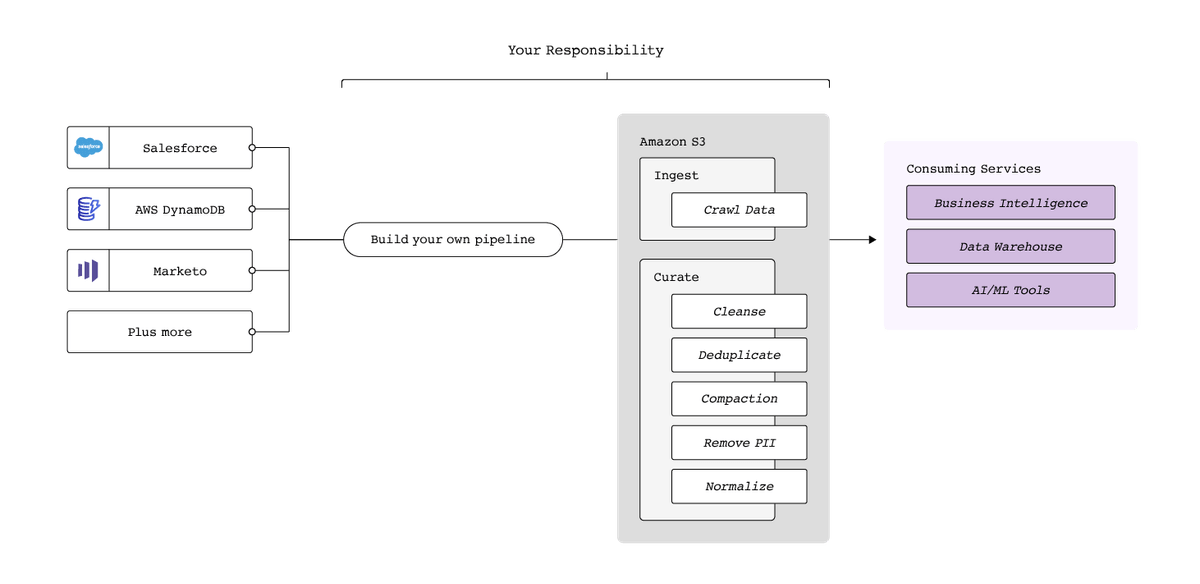
Without automated data movement, data teams must build and maintain pipelines from sources to a data lake. Unlike the ETL workflows involved in some instances of data movement into data warehouses, moving data to a data lake is essentially pure ELT; data is moved raw straight from the source with minimal alteration and formatted in a way that’s queried at the destination, i.e. as Parquet, Avro, or other file types.
While ELT simplifies the data pipeline, the transformation stage is still highly labor intensive. Once the data is in the data lake, the data must be cleansed and deduplicated. Since data lakes generally don’t support schema-on-write, the data must be crawled, with the metadata populated in a data catalog. Then, the data is cleaned, deduplicated and compacted to consolidate the numerous small files that result from frequent, incremental syncs into larger files that are more easily read from the data lake.
For the sake of regulatory compliance and security, the data is then stripped of PII. Finally, the data is normalized, aggregated and transformed into analytics-ready models.
As with using data warehouses as a destination, this workflow stands to benefit from extensive automation. Fivetran natively offers the capabilities described in the workflow above, allowing users to quickly spin up connectors from sources to data lakes using a menu in a GUI, enabling column blocking and hashing of sensitive data before it even enters the pipeline, automatically cleaning, deduplicating and normalizing the data into a table format and populating the metadata into a catalog. From there, the data is queried or transformed as needed.
Automating the basic data engineering legwork of moving data from source to data lake will free data engineering and data science resources for the much higher-value data science work that depends on large-scale data storage, allowing the data lake to solidly mature into its role as the backbone of an organization’s analytics and data science efforts.
To experience for yourself how automated data integration can enable analytics and data science, schedule a demo or consider a trial.
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







