How to govern your S3 data lake


The modern data lake is the product of three market trends:
1. The continued popularity of data lakes as a repository of record and the central element of a data stack, owing to the following advantages of the data lake:
- Durability, availability, scalability
- Cost optimization
- Ease of data ingestion
- Ease of cold storage and archiving
2. The convergent evolution between data lakes and data warehouses, specifically managing or modifying data as you might in a relational system.
3. The emergence of central cataloging and data governance capabilities in data lakes.
Traditionally, data lakes ran the risk of becoming data dumping grounds with no metadata. Data teams could very well end up with no idea what the data lake actually contained, making it impossible to adequately address the following data governance concerns:
- How do you make sure whatever you extracted from your source actually made it to the destination? How do you account for dirty or incomplete writes?
- If a customer has privacy concerns, how do you identify and remove or obscure the customer’s records?
How Fivetran + AWS Lake Formation + Apache Iceberg governs data
ACID compliance ensures that data extracted from a source makes it to the destination and that the destination isn’t polluted by dirty or incomplete writes. AWS Lake Formation enables data governance by incorporating ACID compliance using Apache Iceberg, an open table format, and metadata management with the help of AWS Glue.
Apache Iceberg enables data to be edited (inserted, updated, deleted), discovered and natively accessible through AWS query tools like Athena. Iceberg also enables column- and row-level access. AWS Glue offers cataloging, enabling metadata to be attributed to all incoming data and object-level security controls.
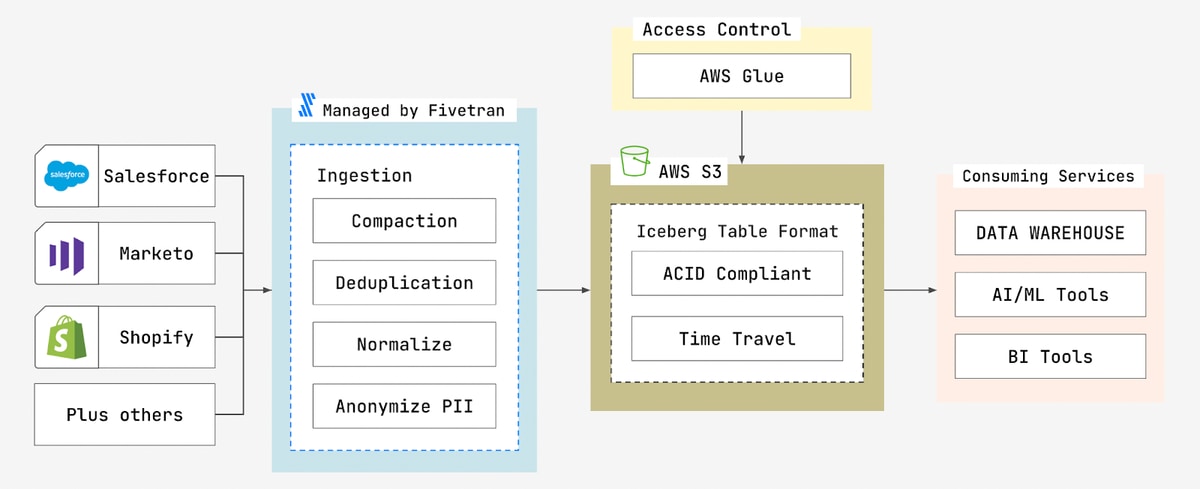
As Fivetran ingests data from a source, a data team can exercise an initial layer of security and anonymization using the blocking and hashing features of Fivetran. The data is cleaned, deduplicated and normalized, then written to the Iceberg table format. Metadata is immediately populated in AWS Glue, allowing a data team to verify the successful completion of a sync.
With the metadata cataloged in AWS Glue, you know exactly what you have in your data repository. AWS also supports versioning and partitioning – you can see different versions of the repository at different times.
How this ensures security and enables the “right to be forgotten”
One of the key elements of GDPR is the “right to be forgotten,” that is, for records attributable to individual records to be deleted or otherwise obscured.
In a traditional data lake, you are forced to copy and extract all of the data, comb for the individual records in question, delete the offending records and then recopy all of the data to the data repository. This is hugely laborious, requiring the use of custom scripting and significant engineering time.
The modern data lake in the guise of S3 with Lake Formation combines tabular data using Iceberg and data cataloging using AWS Glue. These features make managing individual records for the purposes of privacy and regulatory compliance considerably easier. ACID compliance gives you the ability to remove or obscure records in a transactional and consistent manner, little different from what would be done in a traditional data warehouse.
[CTA_MODULE]
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







