Unlock AI-powered search with Fivetran and Milvus


Data is the backbone of AI, and seamless connectivity is key to unlocking its full potential. Unstructured data now accounts for about 80% of all data and holds immense value for AI applications such as enterprise search and chatbots powered by retrieval-augmented generation (RAG). As data volumes grow, scalable vector databases like Milvus become essential for efficiently storing and searching across an organization’s information.
Data for search is stored in various places, such as cloud storage, business applications and relational databases. The typical approach is to join these sources into a single repository, convert unstructured data like text to vector embeddings and store them in a vector database with metadata. This approach enables AI applications to access a wide variety of datasets and adapt to changes in data sources.
Fivetran’s Milvus destination simplifies this process and eliminates the need to build, maintain and monitor complex data pipelines. With just a few clicks, data engineers can create fast, efficient, and scalable AI search solutions, freeing them to focus on creating business value rather than managing infrastructure complexities.
[CTA_MODULE]
How Milvus and Fivetran build a foundation for AI
Milvus is a high-performance, open-source vector database built for scale. A single cluster of Milvus deployed on Kubernetes can handle billions of vectors. Zilliz Cloud is a fully managed version of Milvus, adding enterprise-readiness such as RBAC and SOC2 and even better performance thanks to the proprietary Cardinal vector search engine. Milvus and Zilliz Cloud are widely used in modern AI applications such as semantic search, RAG and multi-modal search.
One of the challenges in building AI-powered search solutions is ingesting data from various sources to Milvus to make it semantically searchable in real-time. Fivetran's Milvus Destination simplifies data ingestion from any source into Milvus, allowing businesses to gain insights without the hassle of managing data movement. By utilizing Milvus's advanced vector search capabilities and this streamlined data flow, developers can quickly build AI applications that fully leverage their organization’s diverse data sources.
With the Fivetran Milvus destination, you can:
- Ingest data from over 600 sources via Fivetran connectors into Milvus/Zilliz.
- Streamline the extraction, loading and vectorization of unstructured data with OpenAI embedding models.
- Enable metadata filtering into vector search by propagating structured data columns.
- Build near real-time search with incremental sync.
Fivetran’s Partner SDK: Building custom connectors and destinations
Fivetran’s Partner SDK empowers tech vendors to create source or destination connectors for their services and integrate seamlessly with Fivetran’s automated data movement platform. Key benefits of the SDK include:
- Language agnostic: The gRPC-based SDK allows source and destination connectors to be written in any supported programming language, offering flexibility for developers to reuse or write new code in their language of choice.
- Reduced complexity: With templates and a local test environment, third-party vendors can easily test and deploy connectors.
- New opportunities for data platforms: The SDK opens new channels for product activation, allowing data warehouses, data lakes and storage platforms to easily access Fivetran’s 600+ connectors.
Zilliz, the company behind Milvus, built an integration with Fivetran by closely mapping its vector database operations to Fivetran’s relational update model. They also streamlined third-party solutions, like the OpenAI embedding service, to generate vectors during ingestion.
AI-powered search in action
Unstructured data, though often the most valuable, is also the most challenging to manage. With Fivetran and Milvus, businesses can quickly and easily build AI-powered search tools to extract insights from their richest datasets.
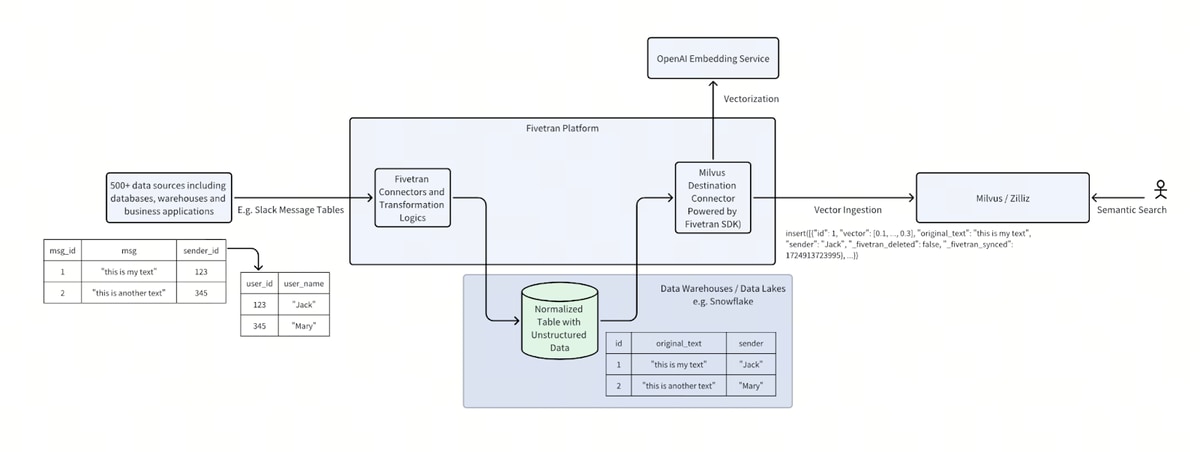
Fivetran’s fully managed connectors move data automatically, reliably and securely from major business apps with built-in schema migration support. For example, imagine a company that wants to build an internal search tool for Slack messages. Using Fivetran’s Slack connector, the data is first replicated and stored in a normalized format in a data warehouse or data lakehouse such as Snowflake. This data can then be denormalized, concatenated, chunked and transformed, after which it can be connected to Milvus using Fivetran’s Snowflake source connector. By simply storing the text chunks in a column named `original_text`, the Milvus destination automatically calls OpenAI embedding service to generate vectors from the text. The vectors are stored in Milvus alongside all other labels as scalar fields and used together for efficient semantic search based on vector similarity with metadata filtering.
Conclusion
The newly introduced Fivetran’s Milvus destination further extends the data landscape in AI to make every data source semantically searchable. By ingesting the source data from a diverse set of databases/warehouses and business apps to Milvus vector database, this integration makes the development of AI workflows easier. You can start using Fivetran’s Milvus destination by following the setup instructions.
To learn more about this integration and see how to build a real-time search in action, please join our product launch webinar on September 26, 2024. We will walk through the features of this integration and demonstrate how to use this connector to build RAG chatbot for GitHub issues!
[CTA_MODULE]
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







