How Agents Schema brings trusted business context to AI


Most modern data stacks were built to move data into a warehouse, transform it for analytics, connect BI tools, and optimize for reporting. That model worked when humans were the primary consumers of data, but AI introduced a different set of demands.
Agents need fresh data from the systems where business activity happens, and they need to use that data across many environments, including analytics engines, ML runtimes, vector systems, and application workflows.
That creates a new architectural requirement: context cannot live in one tool or one workload. It needs to be portable, governed, and reusable across the entire data and AI ecosystem.
[CTA_MODULE]
Open standards make context reusable
In tightly coupled architectures, teams often create separate copies of data for analytics, machine learning, AI, and applications. Every copy introduces another opportunity for stale data, inconsistent business logic, and governance challenges. Worse, if business meaning is trapped inside a single query engine, BI tool, or AI runtime, every downstream system has to recreate it, multiplying inconsistencies over time.
Open Data Infrastructure eliminates that duplication by landing data once in an open data lake foundation that serves as a shared source of truth for every workload. Open standards make both the data and its business context portable, allowing multiple tools to access the same trusted information without rewriting or reinterpreting it.
- Open table formats such as Apache Iceberg™ and Delta Lake make data readable to multiple engines.
- Standard SQL and code-based transformations make business logic easier to test, govern, and reuse.
- Shared metadata and semantic standards help downstream systems understand not just where data lives, but what it means.
The goal is durable context, from which analysts, dashboards, applications, and AI agents can all work from the same trusted data and definitions.
Semantics turn data into business context
Agents need to understand business meaning. A field named ‘revenue’ does not tell an agent whether it includes refunds, taxes, or discounts. And a ‘customer’ table does not explain which accounts are active, at risk, or which relationships should be treated as strategic. Humans fill in these gaps from experience, but agents need that context explicitly laid out for them.
That’s why a portable semantic layer is an essential component in an Open Data Infrastructure. Metrics, entities, and business definitions are defined once, governed centrally, and reused across analytics, operations, and AI systems. The definition of ‘revenue’ and ‘customer’ are available through a shared layer that every consumer can query. When a definition changes, it changes at the source and propagates everywhere it’s used. That way, when an agent acts on ‘customer status’, it’s using the same approved business logic as the teams responsible for the source data.
How Fivetran + dbt Labs power a context-rich Open Data Infrastructure
Building an Open Data Infrastructure that gives AI the context it needs is possible today with open standards and interoperable platforms like Fivetran and dbt.
Fivetran provides the data foundation for AI by automating reliable data movement from systems of record into open, customer-controlled destinations. With more than 750 pre-built connectors, automated schema evolution, proactive API monitoring, and self-healing pipelines, Fivetran helps ensure that analytics and AI systems are working with complete, current data rather than brittle snapshots.
Fivetran's Managed Data Lake Service lands data directly into customer-owned S3 or ADLS in Apache Iceberg and Delta Lake formats, with automated table maintenance and catalog registration across Apache Polaris™, Unity Catalog, AWS Glue, BigQuery Metastore, and OneLake Catalog. With the Managed Data Lake Service, the lake becomes the universal source of truth and the warehouse becomes one of many compute options.
dbt brings the semantic and transformation layer that makes that data meaningful. Transformation logic can be version-controlled, tested, documented, and reused. Business definitions and metrics can be defined once and exposed consistently across downstream tools, applications, and AI workflows.
Introducing Agents Schema: a standard context layer for AI agents
This is why Fivetran + dbt Labs has introduced Agents Schema, an open standard for making business context readable by AI agents. Teams designate one schema in their warehouse or lake as the shared context layer agents can query before they act. Instead of forcing agents to guess which table to use, how a metric is defined, where lineage comes from, or which business rules apply, Agents Schema puts that context in a standard, discoverable place.
Metric definitions, semantic models, dbt lineage, and custom business documentation all live in plain SQL tables inside the Agents Schema. The metadata is sourced from the systems and applications that already own it, then published into the shared schema through open-source GitHub Actions.
The result is a practical foundation for agentic context. Before an agent answers a question, writes SQL, or triggers a workflow, it can inspect the same governed definitions, lineage, and documentation that humans rely on, via the context layer already living alongside the data.
Example: An agent is asked, “What is our MRR this month?”
Instead of guessing which table to use, whether to calculate gross or net revenue, or how “this month” is defined, it first queries the Agents schema to find the definition of MRR, the dbt model and lineage behind it, relevant documentation, and the owner of the business logic. Then it can write SQL against the right business tables using the same definitions analysts use. If the metric definition should change, the metadata is republished into the Agents Schema, so agents continue working from current, governed context instead of stale assumptions.
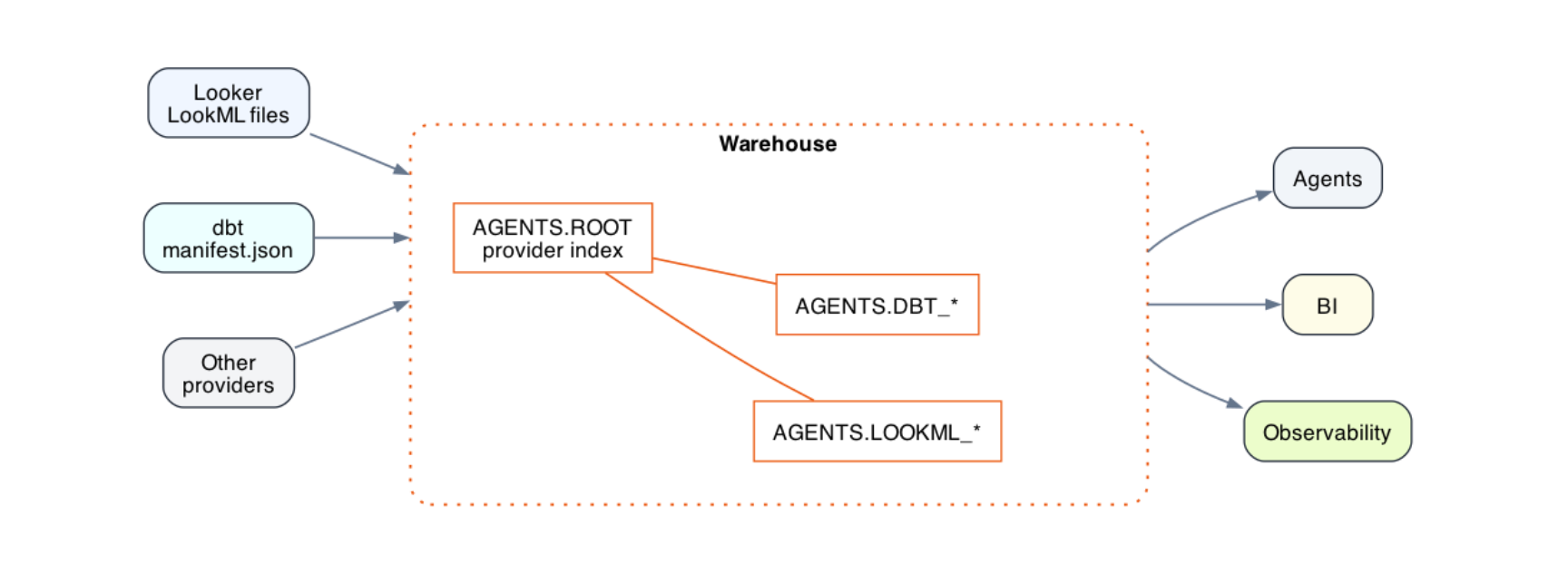
Together, Fivetran and dbt help organizations extend openness beyond storage into shared context: reliable ingestion, open data foundations, portable business logic, reusable semantics, and governed AI consumption.
[CTA_MODULE]
Apache Iceberg and Apache Polaris are trademarks of the Apache Software Foundation.
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







