How to assemble your Open Data Infrastructure


Nobody knows what AI will need from your data stack next year, especially not Uncle Bob, who tried to sell you Bitcoin.
Models are converging. Agents are expanding. Tools are adapting. Last quarter's picture-perfect "AI stack" is described by AI gurus as antiquated and incomplete.
It is hard to know what to do to can get your data ready today for the AI of tomorrow.
In a constantly changing environment, you must design for motion. In game theory terms, you're operating under uncertainty. The rational move isn't to predict every future workload. The rational move is to preserve valuable options while protecting system integrity. Flexibility without integrity becomes chaos. Integrity without flexibility becomes lock-in. And unless you are the one holding the keys, you won't benefit from lock-in.

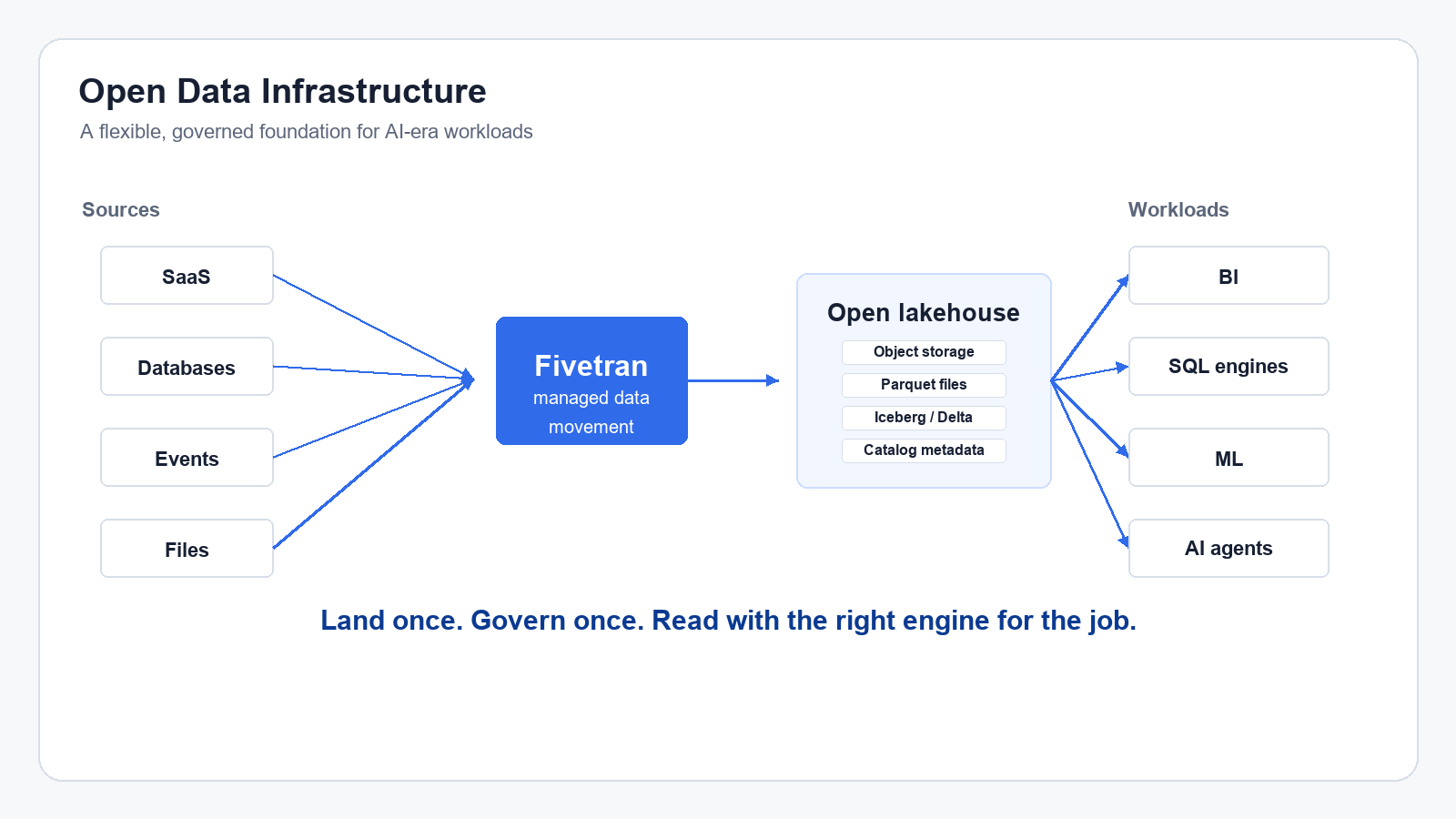
That is the real argument for Open Data Infrastructure. ODI isn't a slogan for buying a different stack. It's a design philosophy for assembling infrastructure that keeps data portable, governed, and usable across tools, compute engines, clouds, and AI systems. dbt Labs has described the same idea as infrastructure that is pluggable, standards-based, and not tied to one compute engine.
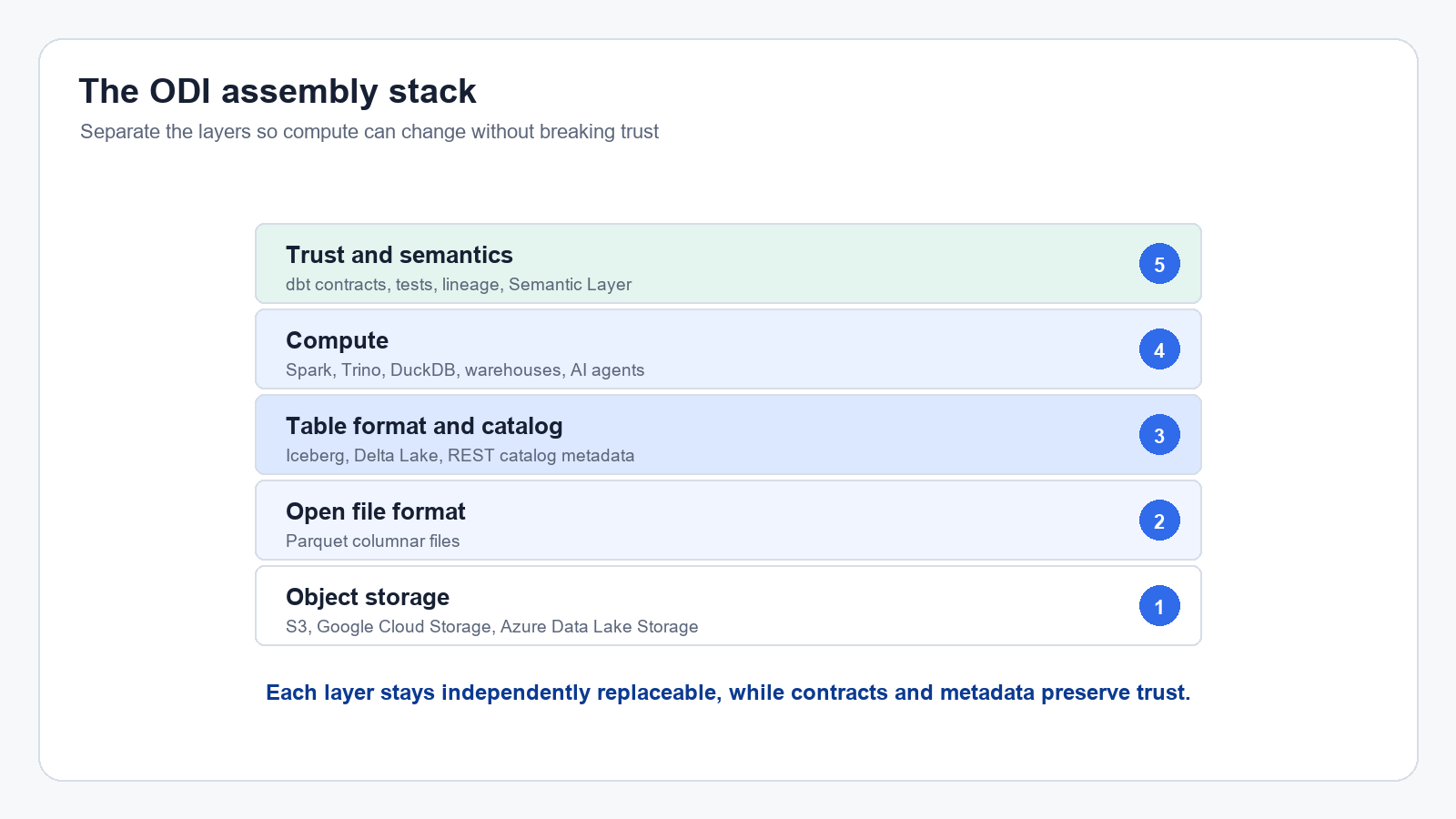
At its heart, the ODI unbundles five layers that were traditionally combined under a single platform:
- Storage
- File formats
- Table formats and catalogs
- Compute
- Trust and semantics
The centerpiece of these layers is the data lakehouse, which combines the strengths of data lakes and data warehouses.
AI doesn't care how beautiful your procurement diagram looks. It cares whether it can reach the right data, with the right context, under the right controls (and your CFO cares that it does all this at the right price).
[CTA_MODULE]
The classic tradeoff is broken
For years, data teams have lived between two imperfect choices.
The first choice is the raw data lake. Put files in cheap object storage. Keep everything. Scale forever. This gives you enormous flexibility, but it doesn't automatically give you table semantics, transactions, schema evolution, rollback, lineage, or consistent governance. A bucket full of files is not a database. Sometimes it's barely a junk drawer with IAM policies (ask me how I know).
The second choice is the proprietary cloud data warehouse. Warehouses solved real problems, and they still do. They gave teams performance, SQL, governance, ACID transactions (atomicity, consistency, isolation, and durability), and a managed experience that didn't require everyone to become a distributed systems engineer over the weekend.
But the tradeoff shows up later. If your storage format, metadata layer, governance model, and compute engine are all bound to one vendor's control plane, then every new workload has to negotiate with that vendor boundary. Want a different engine for machine learning? Copy the data. Want a local engine for development? Copy the data. Want an agent to query governed data directly? Route it through whatever access path the platform allows.
The lakehouse emerged because neither choice was good enough. We wanted lake scale with warehouse reliability.
That sounds simple. It isn't.
The first separation was storage
The lakehouse story starts with a deceptively boring idea. Storage should be separate from compute.
Amazon S3 launched in 2006. That date matters because cloud object storage didn't arrive fully formed as a data lakehouse platform. Object storage made a durable, scalable storage layer practical. It let teams store large volumes of data outside the database engine that queried it.
That was the first big move. Your data no longer had to live inside the same system that processed it.
This is the foundation of flexibility. If storage belongs to one compute engine, then your architecture is already making choices for you. If storage sits in object storage you control, such as S3, Azure Data Lake Storage, or Google Cloud Storage, then compute becomes a choice you can revisit. Fivetran Managed Data Lake Service supports those three storage providers, which matters when you're building something real rather than admiring a diagram.
But object storage alone doesn't solve integrity.
A data lake made of raw files can scale beautifully and still fail the trust test. Which files make up the table? Which version of the data did this model train on? What happens if two engines write at the same time? Can I roll back a bad load? Can I prove two teams are reading the same thing?
Files don't answer those questions by themselves.
Open file formats separate data from compute
After storage comes the file format.
If your data is stored in a format only one engine can read well, then you've separated storage from compute on paper but not in practice. The data still belongs to the path that can interpret it. That is a softer form of lock-in, but it is still lock-in.
This is why open file formats matter. Apache Parquet is an open source, column-oriented file format designed for efficient storage and retrieval. That sounds dry because it is dry. It's also one of the most important ideas in modern analytical infrastructure.
Columnar formats let engines read only the columns they need, compress data efficiently, and operate on large analytical datasets without pretending CSV is a strategy (looking at you, "final_final_v7.csv"). Parquet is supported across a wide ecosystem of tools. Spark can read it. DuckDB can read it. Trino can read it. Warehouses and lakehouse engines can read it.
The principle is simple. Store data in a format that doesn't make the compute choice permanent.
Open file formats move you from "this engine owns my data" to "many engines can understand my data." That is progress. It still isn't enough.
Table formats give files integrity and liberate metadata
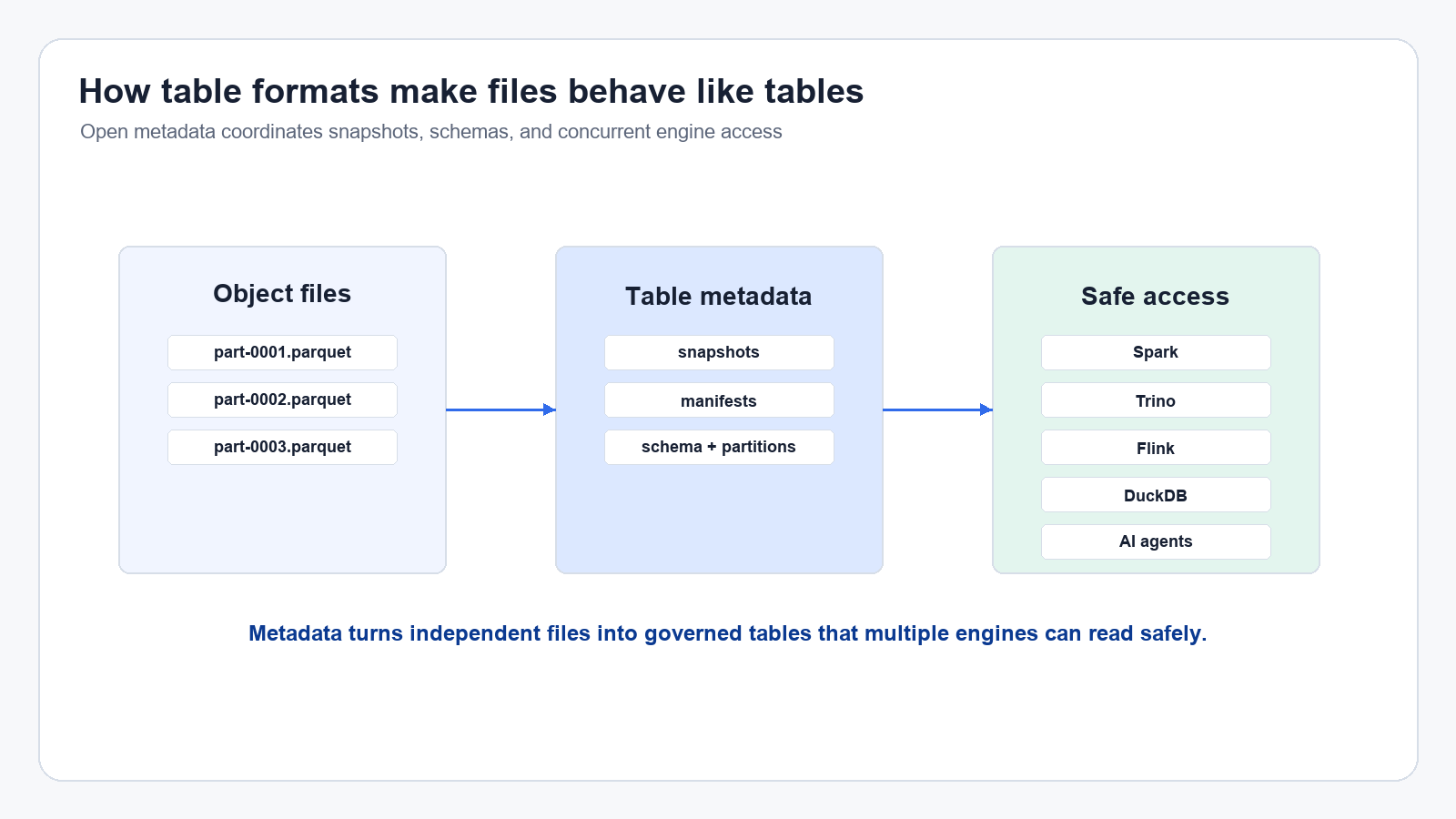
The next layer is where the lakehouse actually becomes useful. Table metadata.
This is the layer raw data lakes were missing. A table format tells compute engines how to treat a collection of files as a table. It tracks snapshots. It manages schema changes. It supports concurrent reads and writes. It gives you transaction guarantees. It lets you ask, "What did this table look like yesterday at 9:00 a.m.?" and get a real answer.
Apache Iceberg is the canonical example here. The Apache Iceberg project describes it as an open table format for analytic datasets that brings the reliability and simplicity of SQL tables to big data, while making it possible for engines like Spark, Trino, Flink, Presto, Hive, and Impala to work with the same tables safely.
That last word matters.
Multiple engines reading and writing the same data sounds amazing right up until two of them corrupt the table. Open isn't enough. Shared isn't enough. A table format has to coordinate access, track metadata, and make sure the thing you call a table is not just a folder with ambition.
This is where the integrity side of ODI shows up. Iceberg, Delta Lake, and similar table formats don't just make lake data easier to query. They preserve correctness while keeping compute flexible. The table layer becomes the contract between storage and compute.
But metadata can't be trapped inside one engine either.
If only one platform can interpret the catalog, policy model, or table state, then you've moved the lock-in up a layer. The better pattern is to keep the catalog and metadata layer accessible through open standards and compatible services, including REST catalogs and catalog integrations. That is how multiple engines can discover, query, and modify the same governed tables without rebuilding the world for each tool.
Compute should match the workload (and your budget)
Once storage, data, and table metadata are open enough, compute becomes what it should have been all along. A workload decision.
You don't need one engine to do everything. You need the right engine for the job.
A data engineer might use Spark for large batch processing. An analytics engineer might use Trino for production models. A data scientist might use Python and a distributed runtime for training. A developer might use DuckDB locally to inspect a subset. A business intelligence workload might need high-concurrency SQL. An AI agent might need governed access to fresh, semantically rich data without waiting for a human to export a CSV like it's 2009.
The point isn't that one of these engines wins forever. The point is that your architecture shouldn't make that decision irreversible (or extremely painful to reverse).
This is the strategic value of ODI. It converts your data infrastructure from a permanent commitment into a set of options. You can standardize where it makes sense, but you're not forced to route every workload through the same engine just because that engine happens to own the data. In a stable environment, that might be fine. In an AI environment, it is a tax on adaptation.
And AI is adaptation all the way down.
Trust is the constraint
Flexibility can become an excuse for mess.
That is the trap. Teams hear "open" and think it means every tool can write whatever it wants wherever it wants. That is not Open Data Infrastructure. That is infrastructure karaoke.
ODI works only when trust is designed into the layers. You need freshness. You need schema handling. You need observability. You need access controls. You need business definitions that don't change depending on which dashboard, notebook, model, or agent asks the question.
This is where Fivetran and dbt fit together. Yay!
Fivetran's role is to make data movement reliable and low-maintenance. In an ODI architecture, that means landing data once into the lake in open table formats and keeping it fresh as source systems change. Fivetran Managed Data Lake Service doesn't just drop files into storage and walk away. It helps manage the lakehouse mechanics around open table formats, catalogs, schema evolution, and table maintenance.
No product makes architecture magic. The Managed Data Lake Service docs are explicit about limitations, including no Iceberg position deletes, no Delta Change Data Feed support for Fivetran-created Delta tables, and no transformations inside the service. Good. Serious infrastructure has boundaries. Knowing those boundaries is part of designing well.
dbt's role is the trust layer above the raw movement. It turns data into governed models, tests assumptions, documents lineage, and gives teams a place to define business logic as code. dbt model contracts are especially relevant because they let teams define the expected shape of a model, then fail the build if the model doesn't match that contract. That is the kind of boring guarantee that becomes existential when agents start consuming data automatically.
The dbt Semantic Layer pushes the same idea into metrics. Define critical business metrics in the modeling layer, then let downstream tools query consistent definitions. That matters for dashboards. It matters more for AI. If one agent defines revenue differently from another agent, you haven't automated decision-making. You've automated disagreement.
The June 1, 2026, Fivetran and dbt Labs merger announcement made the point directly. Agents behave differently from human analysts. They operate continuously, in parallel, and at machine speed. That raises the bar for reliability, freshness, governance, and access.
AI makes weak data foundations fail faster.
Start with the audit, not the migration
The first step is not "move everything to a lakehouse." Please don't do that. Big bang migrations are where roadmaps go to become cautionary tales.
Start by auditing the layers you already have.
For each layer, ask two questions.
- Where are we sacrificing flexibility?
- Where are we sacrificing integrity?
Raw data lakes usually fail the second question. They are flexible, cheap, and scalable, but without open table formats and catalogs, they often lack the guarantees that make data safe for serious analytics and AI. Proprietary warehouses usually fail the first question. They can deliver excellent integrity and performance, but the data, metadata, and compute path may be too tightly coupled for the next wave of workloads.
Lakehouses are not automatically better. A poorly assembled lakehouse can be worse than either alternative. You can build a lakehouse-shaped mess. But the architecture gives you the right target. Open storage, open file formats, open table metadata, flexible compute, and governed semantics.
That target is worth building toward.
Assemble for the future you can't see
The best AI architecture is not the one that predicts the winning model, framework, agent protocol, or query engine.
It is the one that keeps you from betting the business on a single guess.
Open Data Infrastructure gives you a practical way to assemble that architecture. Land the data once. Store it in open formats. Add table metadata that brings integrity to the lake. Keep compute swappable. Use managed services where they remove operational burden without taking away control. Put contracts, tests, lineage, and semantics around the data so that flexibility doesn't turn into entropy.
This is not anti-warehouse. It is not anti-platform. It is anti-dead-end.
AI is going to keep changing. Some workloads will need warehouses. Some will need lakehouse engines. Some will need local processing. Some will need streaming. Some will need vector search, feature engineering, model training, or agentic access paths we haven't standardized yet.
The data foundation has to stay trustworthy through all of that.
AI doesn't need your data stack to predict the future. It needs your data stack to survive it.
[CTA_MODULE]
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







