

The following blog post is the seventh chapter in a primer series by Michael Kaminsky on databases. You can read Chapter Six if you missed the first lesson on distributed databases, or watch the complete series on YouTube.
There are no free lunches when you’re working with distributed databases. Distributed computing is very powerful, and distributed databases help us solve vexing problems. However, introducing multiple nodes into a data architecture and connecting multiple computers via a network adds complexity and new problems.
Murphy’s law of distributed computing tells us that if it’s possible to experience a network outage, we will experience a network outage. So our distributed databases must be able to handle these outages gracefully, or else our distributed database will stop working at the least opportune time.
Follow the Leader
The first concept we want to introduce is the idea of a “leader” node. In the last lesson, we showed how a “big compute” distributed database might work, but we didn’t mention that an additional computer is required here. We often refer to this additional computer as the “leader node.” The other nodes are often referred to as “follower” or “compute” nodes.
The job of the leader node is to coordinate the work of the follower nodes. If you send a command or a query to the leader node, it decides how to distribute that query among the different follower nodes. Then the results from each of the follower nodes are returned to the leader node, and the leader node assembles the final results and returns them to the user.
The idea of a leader node is really important, and today we’re going to talk about the different types of “decisions” the leader node might need to make in different circumstances, and where and how things might go wrong in the interactions between leader node and compute nodes.
Lost Nodes
The first issue I want to talk about is the situation where the leader node loses contact with one of the follower nodes. We can imagine lots of reasons this might happen. Maybe the power went off in the data center, or the internet service provider in the region went down. It could be a temporary blip due to network traffic congestion, or it could be because the computer itself had a fatal error and completely shut down.
The leader node must answer a number of questions:
- Should we wait to see if the node comes back online?
- How long should we wait before we give it up as lost for good?
- Do we have backup for the data that was on that follower node?
- Where is that backup data, and how do we coordinate making sure that it’s accessible?
- What data was on that node, anyway?
- If it was only a subset of the data, does the leader node even know what data is now missing?
- Etc.
Questions like these are crucial when designing and working with distributed databases. We must think through what’s going to happen when different parts of the system break down in advance. Don’t forget Murphy’s law of distributed computing: If a node can go down, it will go down!
Updating Data
Another interesting problem for the leader node to solve is how to deal with data changes in a distributed setting. In distributed databases, we rarely have full copies of the data on all of the different nodes. Instead, we have partial and overlapping copies of the data on the different nodes.
How do we make sure that the change gets made correctly on all of them? Do we require each node to tell the leader node that the operation completed successfully? What happens if we lose contact with a node before hearing back that the change was made successfully?
In general, how do we manage transactions and locking in this new world where multiple copies of the data might live on different nodes that have different amounts of latency when communicating with the leader node?
This gets a lot more complicated in a distributed database than a single-node system, because we have to apply the locks in more places and manage the state of the data in more places, while remembering that we could have a network outage at any time.
In the next lesson, when we talk about consensus, we’ll discuss in more detail how distributed databases make these decisions under the hood.
Hot Segment
Another problem we face when working with distributed databases is the problem of an imbalanced distribution of data across the different nodes. A simple example is when data on one node is being accessed much more frequently than data on another.
This could happen if, for example, your data are distributed across the different nodes by the data of creation. If more recent data are accessed more frequently (something that is generally true in databases) then one node will end up having to work a lot harder than the other nodes.
In this case, we don’t actually use our distributed database to its full capacity because we have a lot of nodes that aren’t doing any work at all. We’d rather have the computational load evenly balanced across our nodes. So, if we have an imbalance of data and access across the nodes, how can we actually move the data between nodes?
Unfortunately, moving data between nodes is really slow.
In a single-node world, we often talk about the difference between accessing data from the hard disk versus accessing data from RAM. Typically, accessing data from RAM is fast while accessing data from the hard disk is slow. With multiple nodes over a network, we have the option of accessing data over the network. This is, unfortunately, even slower than accessing data off of a local disk.
So, whenever we talk about moving data between nodes, for whatever reason, we have to keep in mind that this is the slowest way to access data and we can quickly lose any gains in efficiency that we got from using a distributed database if we need to send too much data over the network.
Data Shuffling
Let’s take a look at how this can be a problem in a big-compute setting. In the last lesson, we looked at an analytical query where we counted the number of users in each state, and observed that it was very efficient. Each node could count its data separately, and then we could add up the results from each node at the end to get our answer. By calculating in parallel on the different nodes, we were able to speed up our query.
Unfortunately, here we have an example query that doesn’t work so efficiently:
SELECT COUNT(DISTINCT user_id) FROM table
In this example, we want to get a count of the distinct users in our database. Because not every node has a complete copy of the data, we can’t just count the distinct users on each node and then add them up! If we take the count of distinct users on node 1, and add that to the count of unique users on nodes 2 and 3, we may very well double-count (or triple-count) any users that are included on more than one node. We will need a different approach.
In this example, the query is first going to go to the leader node, and the leader node will have to decide the best way to get the answer back to the user. Since we can’t just send the “count distinct” query to each node individually, we will have to send a different query to each of the nodes:
SELECT DISTINCT user_id FROM table
The leader node is going to ask each of the nodes not for the count of distinct users, but actually for a list of all of the distinct users on that node. So each node will find the distinct users it has, and send all of those back to the leader node.
Then, once we have the list of distinct users from each of the follower nodes, we can compile that list on the leader node and get our final count of distinct users.
We can see that all together here:
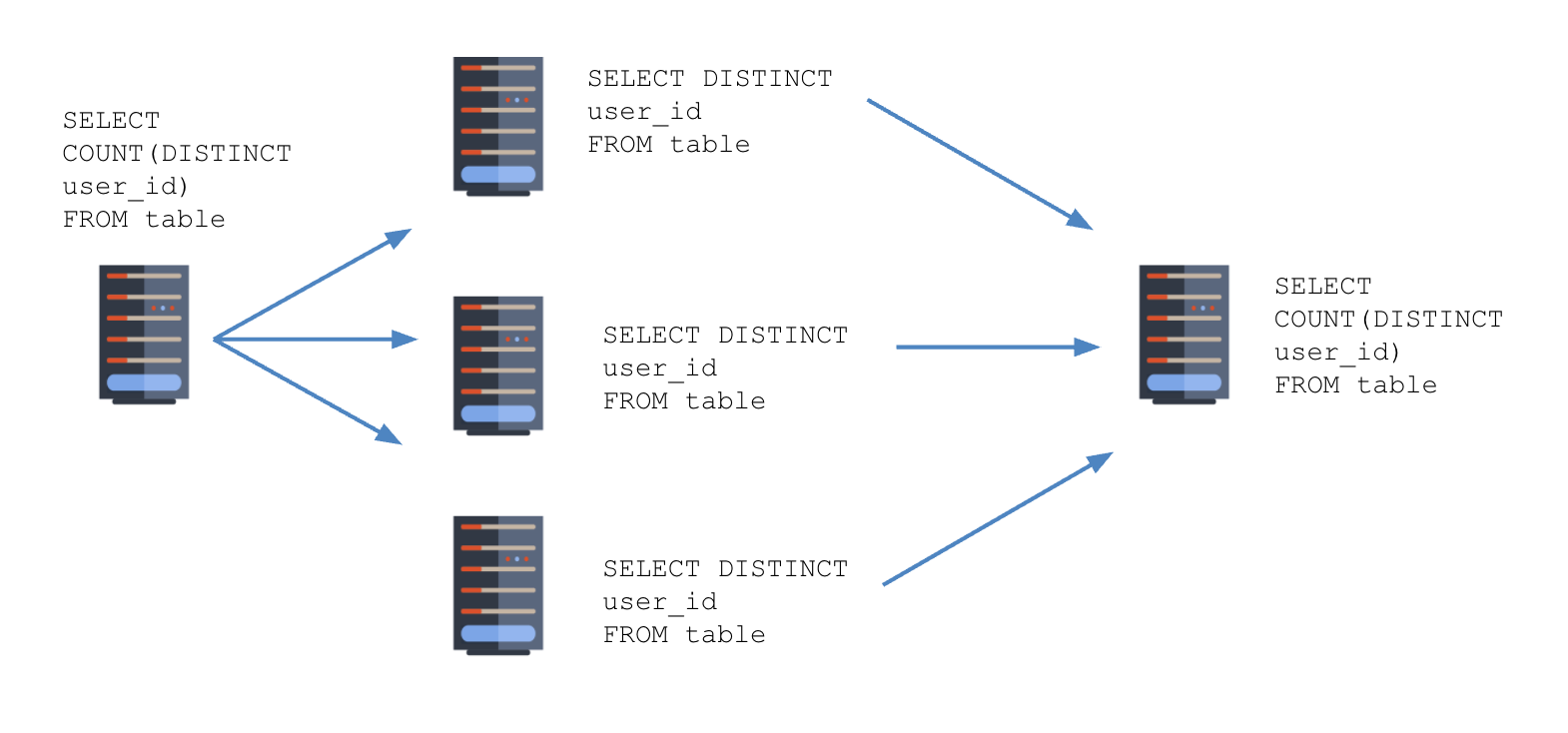
The leader node will examine the original query, have all of the follower nodes send the required data back to the leader node, and then the leader node can perform the final computation.
Unfortunately, this is very slow because we have to send the list of users from each follower node over the network to the leader node! Any time a database has to move data between nodes in order to respond to a query, we’ll have very slow response times.
This is of course slower than what the response time would be if we were doing this all on a single-node database. Instead of saving time by distributing the job and performing our operations in parallel, here we end up losing time because we have to send so much data over the network.
CAP Theorem
The CAP theorem is talked about frequently in the context of databases, though there is some controversy over how applicable it is and whether it’s actually the best framework for talking about trade-offs in distributed databases.
I personally think it’s a useful model for getting oriented to distributed databases. If you understand the CAP theorem then you understand a lot about distributed databases and the relevant trade-offs when it comes to working with distributed databases.
CAP stands for “consistent,” “available” and “partition-tolerant”:
- Consistent means that every read from the database receives the most recently written data, or an error (that is, the database doesn’t return “stale” data).
- Available means that every request receives a response.
- Partition-tolerant means that the database is resilient to network errors.
The CAP theorem is a trilemma. You can choose at most two of the three. A database can be consistent and available but not partition-tolerant, available and partition-tolerant but not consistent, or consistent and partition-tolerant but not available
With distributed databases, we have even less of a choice. Because of Murphy’s law of distributed databases, we must assume that there will be network outages and choose partition tolerance.
So for distributed databases, the choice is really just between “consistent” and “available.” Should we make sure that the database is guaranteed to return consistent, non-stale data, or do we want our database to return something at all times, even if it might be stale?
Let’s imagine this situation where we have our distributed database. Two of our nodes have stale data, and one node has the fresh and correct data. Our leader node knows which nodes have which data because it’s been keeping track of which data updates have completed successfully on each node.
Unfortunately, when our user wants to see the balance from the account, the node that has the correct, fresh data on it is inaccessible. So, does the database return the stale data from one of the other nodes, or does it error out and wait for the node that has the correct data to come back on line?
The choice may depend on you how you plan to use the data. If we’re actually keeping track of account balances in a bank, then we probably prefer that our data is consistent instead of available. However if we’re just keeping track of the number of visits to our webpage, it might be okay that the data is a bit stale and we’d prefer to have our database return the stale data than nothing at all.
Alternatives to CAP
Some people have criticised the CAP theorem for being overly simplistic, especially in the context of distributed databases, where we know that network partitions are a fact of life. In fact, within distributed databases, whether there’s a true “outage” or not, we’ll always face a trade-off between latency and consistency. That is, there will be different amounts of latency between our different nodes and so we’ll always have a choice of returning potentially stale data earlier vs. waiting for all of the nodes to return.
If you’re interested in learning more, I’d recommend checking out the PACELC framework, which makes this trade-off more explicit.
Summary
Distributed databases are powerful but they come with lots of additional complications. In particular, we always have to assume the eventuality of network outages (Murphy’s law of distributed databases).
How data is distributed across the nodes can impact performance dramatically, and this impact will be different for different queries.
Finally, the CAP theorem helps us reason about the trade-offs we make when we experience network outages — in the case of distributed databases, that means a trade-off between consistency and availability.
In the next installment of this series, we will discuss consensus in the context of distributed databases.
The series continues with Chapter 8 here.







