A deep dive into data lakes


The volume, velocity and variety of data have grown exponentially alongside “big data” and the widespread adoption of cloud-based tools and technologies. Teams with the ability to analyze enormous volumes of data have the potential to uncover extremely granular insights about an organization’s operations, customers and opportunities. However, before data can be analyzed, it must be stored and accessed cost-effectively. Moreover, data can’t simply be dumped into a location, but must be organized and, if possible, structured so that it can be interpreted and turned into actionable insights as quickly and easily as possible.
With the rise of “big data,” data lakes – centralized repositories that enable an organization to store both structured and unstructured data at scale with minimal processing – have grown in importance and usage. Data lakes are designed to easily scale cloud-based storage without adding additional compute. This decoupling between storage and compute enables considerable flexibility and cost savings, allowing organizations to pay cheaply on the basis of usage. Moreover, data lakes are often compatible with range of data ecosystems and complementary tools, allowing organizations to choose tools that fit their needs with little danger of vendor lock-in.
Scalable, flexible, affordable large-scale storage is the essential backbone of all analytics. The quality of analytical insights improves with increased volumes and quality of data. Machine learning and artificial intelligence workloads, in particular, rely on very large volumes of semi-structured and unstructured data, including media files of all kinds. Any models that leverage natural language processing or image recognition depend on data that cannot be stored in a conventional tabular format. Generative AI similarly depends on large volumes of media and poses the same data integration challenge.
In addition, many machine learning and AI workflows also depend on streaming capabilities to adjust the outputs of a product in response to user behavior in real time – think Youtube or Netflix. For these reasons, data lakes have long been the preferred data repositories for machine learning and artificial intelligence initiatives.
Why Fivetran supports data lakes
Historically, the ability of data lakes to easily absorb large volumes of data also made data lakes difficult to manage, putting them at risk of becoming unnavigable “data swamps.” Data lakes have also historically been difficult to govern because of the huge volume and diversity of data involved, as well as the need to assign permissions based on specific objects or metadata definitions.
Until recently, relatively few organizations had use cases requiring either unstructured data or particularly large volumes. For these simpler analytics use cases, the data warehouse offered adequate scalability and flexibility, along with tools for better governance and security, that made the cost premium over data lakes worth it for most companies. If an organization needed support for unstructured data, it could maintain a separate data lake as an object storage while maintaining the corresponding metadata in the data warehouse.
Accordingly, Fivetran has historically been skeptical of the data lake and generally advocated for the use of data warehouses for analytics. Three major trends have changed our position:
- The data needs of the typical organization have increased considerably in scale and volume, making the cost advantages in compute and storage offered by data lakes more meaningful. Organizations now make the easy scalability and cost savings offered by data lakes a priority. For organizations that must accommodate large volumes of semi-structured (i.e. JSON) and unstructured data (i.e. media files), the data lake can serve as a better platform for a “single source of truth” than a data warehouse.
- Data lakes are increasingly capable in terms of cataloging, governance and the handling of tabular, structured data — as well as security and regulatory compliance. High-performance structured data lake formats offer benefits normally associated with data warehouses such as ACID compliance and row-and-column level querying and editing.
- The functions and capabilities of data warehouses and data lakes are increasingly consolidated under a common cloud data platform or data lakehouse. This simplifies an organization’s data architecture by obviating the need to maintain a separate data lake and data warehouse, using the data lake to stage all data while moving curated, filtered and transformed data from the data lake into the data warehouse.
The development of the modern data lake architecture, sometimes called the “data lakehouse,” has brought the ideal of a unified data platform to serve all analytics needs, ranging from BI and reporting to machine learning, closer to reality. As generative AI has grown in importance and usage, so has the need for scalable, flexible and affordable data repositories as well as simpler, more modular and sustainable architectures.
Support for data lakes as a destination by Fivetran continues to grow. One very important development is support for structured data lake formats, enabling organizations to stand up governed data lakes. This will continue to be a key capability as predictive analytics and generative AI continue to become more potent and accessible for organizations of all kinds.
Structured data lake formats and the governed data lake
Fivetran currently supports data integration into two structured data lake formats that offer capabilities normally associated with data warehouses: Delta Lake and Apache IcebergTM.
Structured data lake formats enable data lakes to be governed. They incorporate several strengths of data warehouses, including:
- ACID (atomicity, consistency, isolation and durability) compliance is a key characteristic of structured databases that organizes all changes to a database into monolithic transactions, guaranteeing the validity of data regardless of potential mishaps (i.e. software or hardware failures).
- Schema enforcement ensures that invalid or improperly structured data is never ingested into a destination. A related capability, schema evolution, means the ability to accommodate changes to the structure of data over time.
- Cataloging and governing data ensures that teams can keep track of their data assets and products, including the provenance of data models created to answer specific analytical questions.
- Row-and-column level querying and editing using SQL allows transactions, aggregation functions and other transformations to be easily performed on the data, massaging it into formats accessible to analysts.
- Security through data access control enables the principle of “least privilege,” ensuring that people only have access to data they need to perform their roles and limiting the potential for data to be compromised.
Delta Lake
Delta Lake is an open source storage layer designed to work with Apache Spark. It provides ACID transactions, metadata handling, and unifies stream and batch processing. Delta Lake uses versioned Parquet files to store your data in your cloud storage. Apart from the versions, Delta Lake also stores a transaction log to keep track of all the commits made to the table or blob store directory. Simply put, the Delta Lake is a layer over Parquet files that integrates with Spark's compute layer.
Fivetran currently supports Delta Lake combined with major cloud providers such as AWS, Azure, OneLake and Databricks itself, avoiding vendor lock-in. By year’s end, we also plan to support Google Cloud Storage with BigLake. In practice, this means that Fivetran extracts and converts data from structured data sources of all kinds into Parquet files with Delta Lake metadata.
Iceberg
Apache Iceberg is an open-source table format designed for managing large, evolving datasets in data lakes. It was originally designed, built and deployed at Netflix to bring the capabilities of cloud-native data warehouses to their data lake. Designed for portability and interoperability with a very wide range of data lakes and data processing and analytics tools, Apache Iceberg has accumulated a very large community of users across many top tech companies. Unlike Delta Lake, it is not tied to Parquet and is also capable of being layered over formats such as Avro and Orc.
Fivetran currently supports Amazon S3 as a destination for Apache Iceberg, offering secure, fully managed pipelines and comprehensive compliance. As with Delta Lake, Fivetran supports Apache Iceberg with Amazon S3 through connectors that automatically convert data into the appropriate format
How Fivetran supports data lakes
Fivetran is fundamentally a data integration solution. Whether the destination is a data warehouse or data lake, the challenges involved in moving data from sources such as applications, files, event streams and operational databases are much the same.
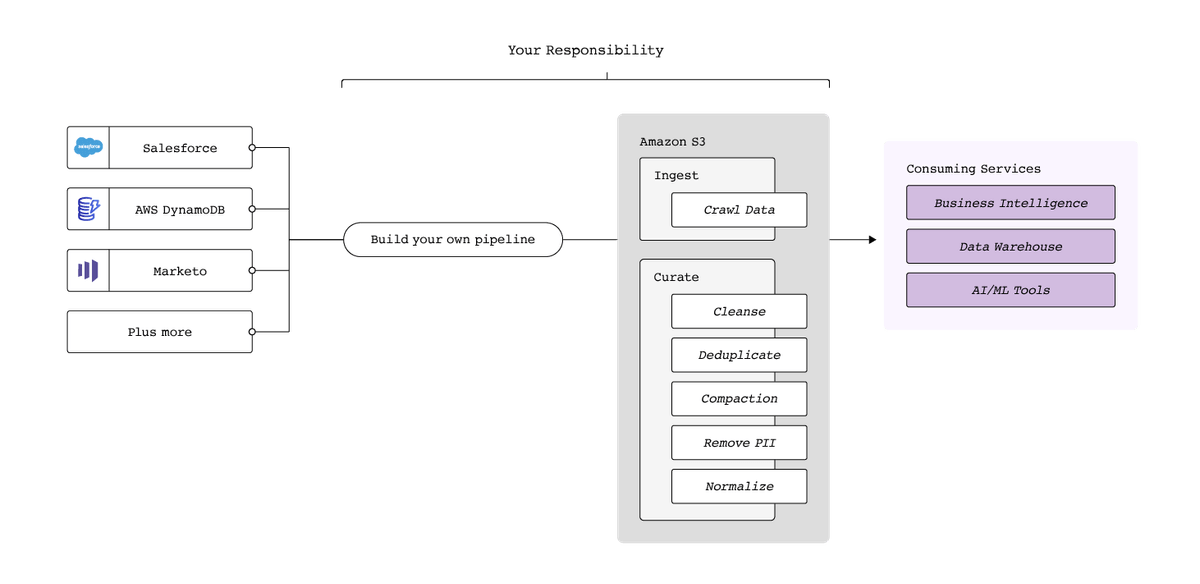
At its core, Fivetran automates data integration, including the conversion of raw data into data lake formats like Apache Iceberg or Delta Lake. Concretely, Fivetran turns data integration from an engineering-intensive process requiring careful design, building and maintenance into a matter of navigating a series of menus. Setup takes no more than a few minutes, and maintenance is fully outsourced to an experienced team, obviating the need to ration engineering time or keep it on call for pipeline breakages.
Data integration and movement capabilities that Fivetran brings to the table include:
- Incremental updates through log-based change data capture (CDC) that automatically identifies and replicates changes from a source to a destination
- Idempotence, ensuring the reliability and integrity of data syncs
- Schema drift or schema evolution handling, detecting structural changes in source data and replicating them in a destination
- Guaranteeing pipeline and network performance through algorithmic optimization, parallelization and pipelining
- Enabling SQL-based transformations and the orchestration thereof, allowing analysts to take a systematic, collaborative, version-controlled approach to producing data models from raw data
Beyond automating data integration and data movement, Fivetran also guarantees the security and governance of the data, ensuring regulatory compliance and the protection of sensitive data and trade secrets. To this end, Fivetran offers the blocking and hashing of sensitive data, end-to-end encryption, role-based access controls, process isolation and other features. In addition, Fivetran offers a metadata API that offers full visibility into all of your data in transit, allowing you to keep track of all data assets and products.
Combined with governed data lakes, the capabilities we offer are a tremendous data engineering force multiplier. By making data accessible from the data lake with the click of a button, analysts, engineers and data scientists alike can pursue higher-value projects and uses of data. The combination of Fivetran and structured data lake formats transforms data lakes from ungoverned dumping grounds of data, into organized, governed, user-friendly data stores, with quick and efficient access to data and many opportunities to apply it to AI and large language models.
The growth of generative AI makes these capabilities all the more important. For most business use cases, the chief limitation of generative AI is that it lacks any context or data that is specific to an organization’s line of business and internal operations.
Current AI architectures presuppose the existence of data that can be converted into vectors and knowledge graphs and supplied to a foundation model (see below).
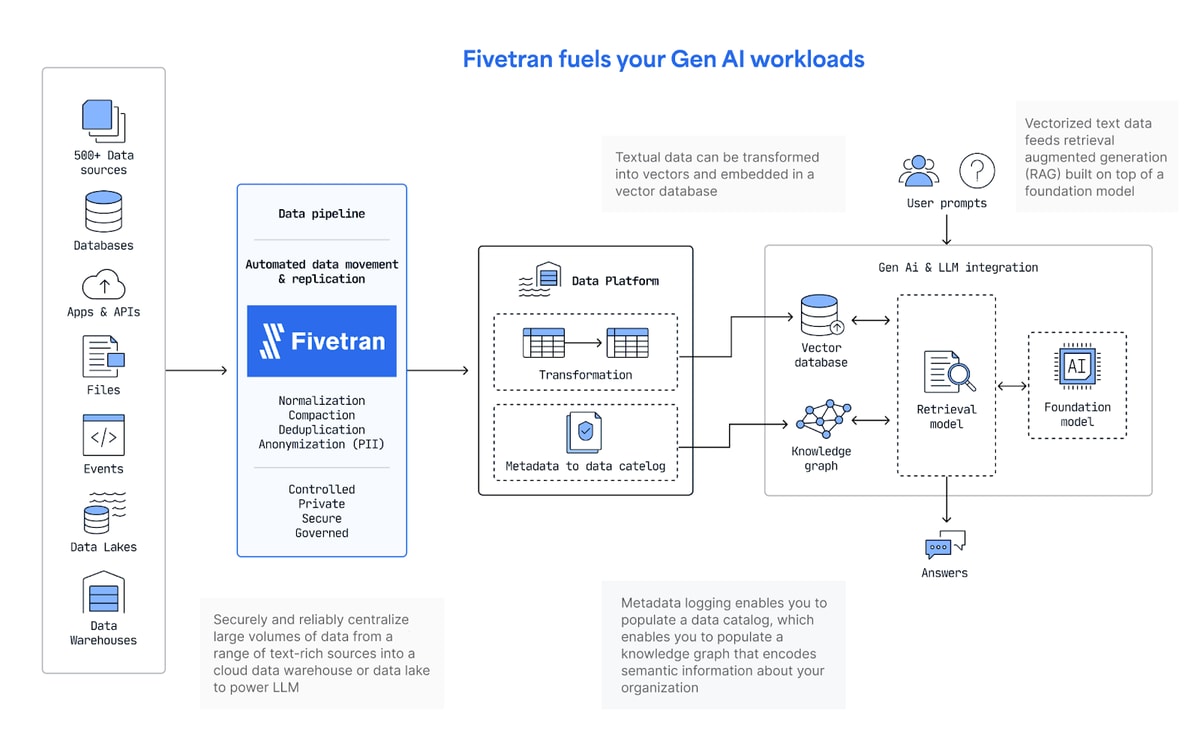
With Fivetran, the movement of critically important data into a data lake with a simple, no-code approach unlocks not only analytics but also AI. With data already accessible through a data lake, it is a relatively simple matter to use it for generative AI. With the help of Fivetran, customers can avoid the challenges that historically hindered data lakes and achieve a headstart on innovative, transformative analytics and AI projects.
Apache Iceberg is a trademark of the Apache Software Foundation.
[CTA_MODULE]
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







