

If you are a small but growing tech company, chances are good that you use GitHub for collaboration and version control. Fivetran offers a GitHub connector to help you quickly gather data about issues, pull requests and commits. We also offer a dbt package to transform your data into more tractable, analytics-ready models.
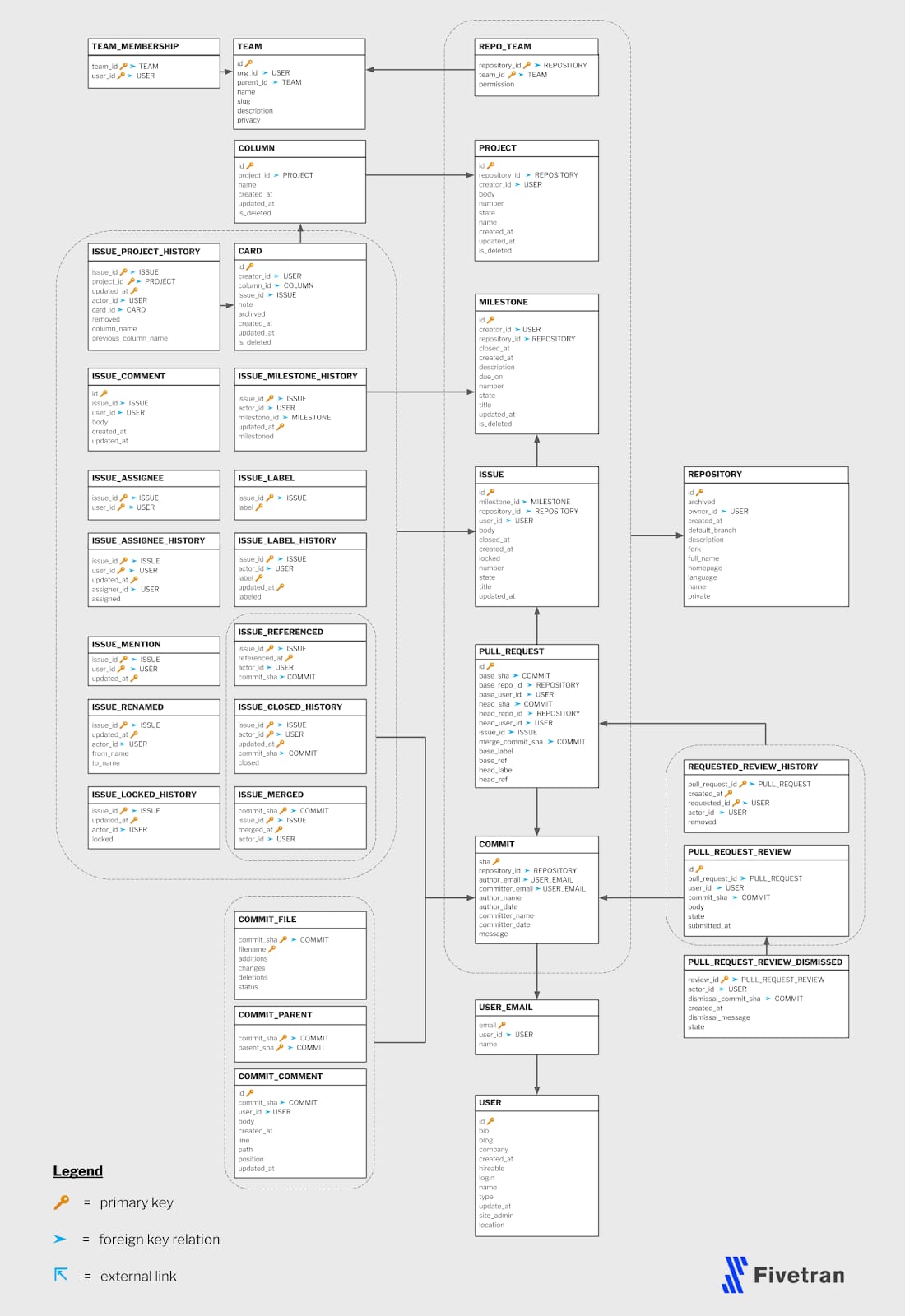
See the most current version of the ERD here.
GitHub data can help you track the following:
- Types of engineering work
- Productivity and velocity
- Bug resolution
To glean insights from issues, pull requests, and commits, you will first need to identify the right metrics. This may require transforming the normalized schema provided through the GitHub connector. Then, you will need to represent those data models on dashboards or visualizations.
1. Types of engineering work
One of the fundamental tradeoffs your engineering team must contend with is splitting time between maintaining the stability of the product and creating new features.
On one hand, a product that does not evolve new features will eventually be supplanted by competitors that do. On the other hand, a product that fails to perform as promised will lose its user base and hurt your brand.
The questions to ask and metrics to answer them
You will have to look outside of GitHub to see whether customers immediately prefer better performance or new features, but GitHub data can tell you how you’re apportioning your resources.
1. How many issues are opened for bugs, code hygiene and new features?
If you aren’t in the habit of labeling your issues by category, you should do so. Group your issues by label and determine the breakdown of your work.
Tables and fields
- Github.issue - id, created_at
- Github.issue_label - issue_id, label
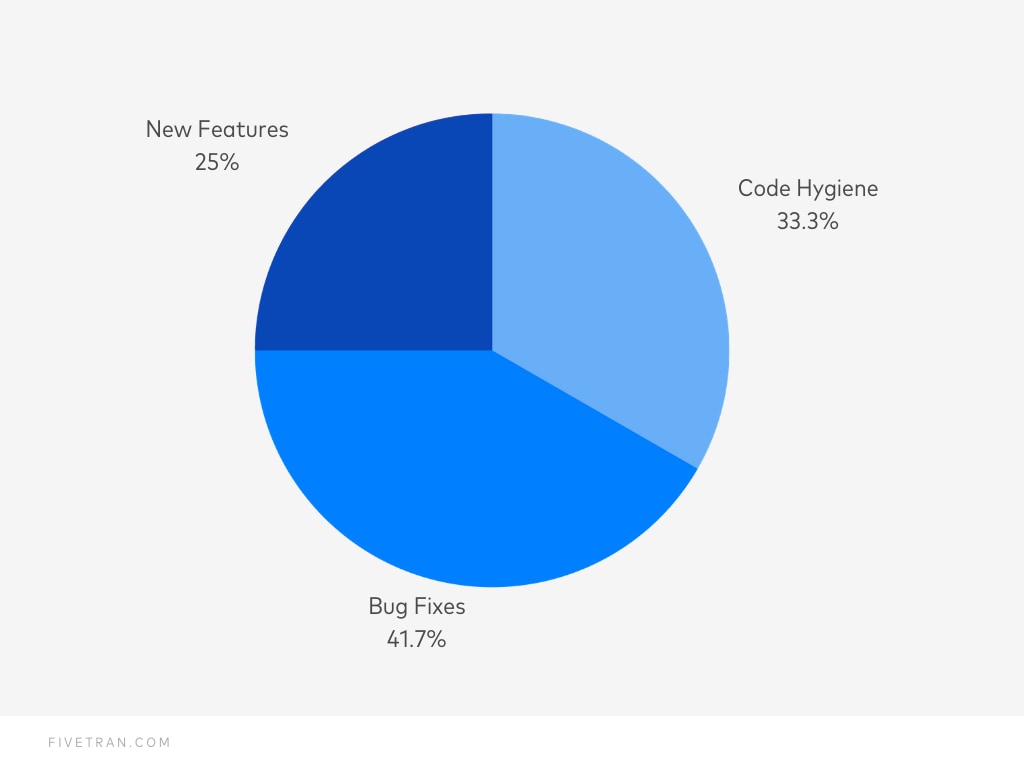
Arrange this data by time to observe any trends and compare them with other happenings, i.e. customer feedback.

2. How much work do you dedicate to each category?
You can estimate effort by attributing story points or a similar metric to each issue. Group by label to see which categories get the most attention.
Tables and fields
- Github.issue table - created_at, closed_at fields
- Github.issue_assignees - issue_id, user_id fields
- Github.issue_label - issue_id, label

3. Do some of your engineers specialize in certain categories?
Are there any teams or engineers who seem to specialize in a particular category? Group by team or assignee and look at both raw numbers and percentages by label to find out.
Tables and fields
- Github.issue_label - issue_id, label
- Github.issue_assignees - issue_id, user_id (can join this to github.user to get user.login)

2. Does the time elapsed influence the chances of the pull request being closed?
There is a good chance you will notice that, beyond some interval of time, the chances of a pull request ever being successfully closed drop precipitously.
Tables and fields used
- Github.pull_request - id
- Github.pull_request_review - pull_request_id, submitted_at
- Github.issue - created_at, closed_at (all pull requests are in the issue table with pull_request = TRUE)
3. Do different engineers review and close pull requests at different rates?
Certain engineers are better at reviewing pull requests than others. It might be worth identifying and assigning the most efficient reviewers.
Bin the data by reviewer and determine the average elapsed time to review.
Tables and fields used
- Github.pull_request_review - user_id (this is the reviewer), pull_request_id, submitted_at
- Github.requested_reviewer_history - pull_request_id, requested_id (this is the reviewer user_id), requested_reviewer_history.created_at

Next steps
As you can see, there are many trackable points within GitHub data, and the data can be further enriched by blending it with other data sources as well. For instance, you can measure product health data by finding which features of your product are responsible for the most bug fixes, then further validate your findings by examining data from Zendesk or another customer support data source.
In addition to the data already available through the Fivetran ERD, make sure to explore the data from the dbt package. It includes tables designed to streamline your analytics efforts
Good luck!







