Unleashing the power of Fivetran and Azure Synapse for accelerated data movement


One of the most enjoyable aspects of my role is witnessing the reactions of our consulting services partners when I demo Fivetran. They are impressed by the speed, simplicity and self-service nature of our platform and recognize how it can expedite their clients' ability to deliver data products and services. The "wow" factor of Fivetran is hard to miss.
Since Fivetran expanded our partnership with Microsoft and joined the Microsoft Intelligent Data Platform partner ecosystem, we’ve seen a surge in requests from Microsoft consulting services partners (both GSIs and SIs) seeking a comprehensive understanding of our Automated Data Movement Platform.
Here are some of the questions that arise:
- Does Fivetran support Azure Synapse, and how can it benefit my Microsoft clients?
- How does Fivetran differ from Azure Data Factory (ADF)?
- How straightforward is it for Microsoft clients to purchase Fivetran through the Azure Marketplace?
In this post, I will focus primarily on how Fivetran and Azure Synapse operate together, but I’ll also touch on the other subjects above, which should help you gain a better understanding, regardless of whether you are a Microsoft partner or a customer.
Additionally, I reached out to Scott Fitzharris, General Manager of Azure Data & AI in the Enterprise Commercial South Region, for his insights on the Fivetran-Synapse partnership, and here's what he had to say:
“Personally, I love the power that Fivetran puts into the hands of the people that need it the most. Fivetran helps our Azure customers take modern data management to an entirely new level. And what’s even more powerful is the combination of Fivetran and the Microsoft Intelligent Data Platform, including Synapse Analytics. Our customers are asking for ease of use in combination with a powerful data analytics environment. Microsoft and Fivetran take that to the next level!”
[CTA_MODULE]
Creating data pipelines is more than just the “build”
To fully understand the value of Fivetran with Azure Synapse, I like to start with what it takes to create a new data pipeline from scratch — start to finish.
Almost every new data product, analytic model or report requires a new dataset or subset of data that requires a new data pipeline. A single new dataset typically takes anywhere from 4-6 sprints (8-12 weeks) to cover all core activities outlined in the diagram below. In addition, the teams building one-off pipelines are dealing with constant one-offs such as an API rate limit change, schema changes, table changes, data type assignments, orchestration, security, connectivity, etc.
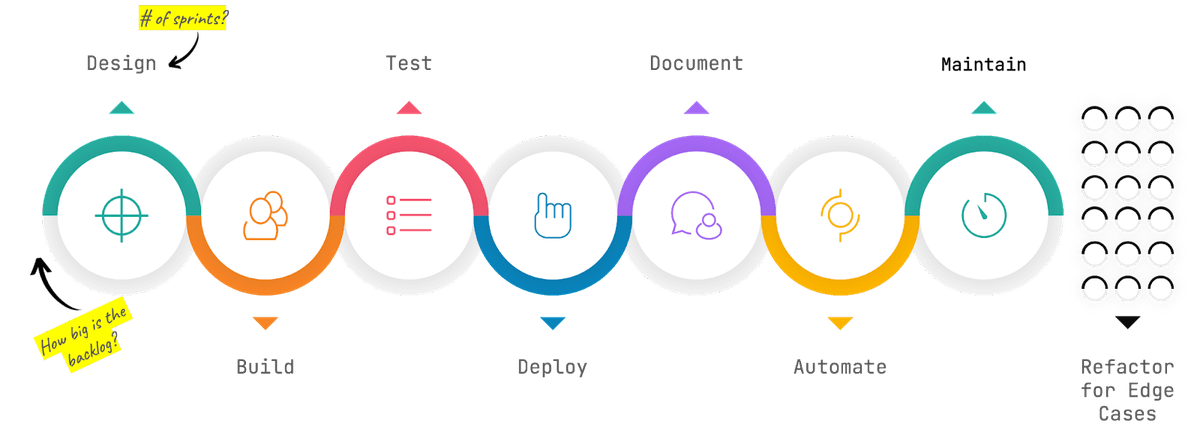
Following the "one-off" model above is a long way from “set it and forget it” — I typically call that model “set it and keep your fingers crossed”.
My top 10 “build” considerations
Here’s my top ten list of data pipeline design considerations for databases as a source (in case you’re thinking about choosing to build from scratch):
- Patterns, use cases, applications (for this database)
- Location (on-premise or cloud)
- Type and version (plus OS version)
- Size (total, redo, archive, change rates, change rate timing, etc.)
- Size again (schemas, tables, largest tables, # columns)
- Special features in use (e.g. Oracle RAC, ASM, ADG, etc.)
- Complexity (data types, customization, etc.)
- Utilization % and Users (Total, Type (reporting, etc.)
- Existing workloads (OLAP vs OLTP)
- Deployment specifics (networking, security, privacy, access, current process, etc.)
Fivetran SaaS and Azure Synapse
I’ve worked with large enterprises and large government agencies throughout my career and they all have at least one thing in common: a lot of databases running everything from core financials to operational applications or industry-specific apps. There’s significant value in moving these RDMBS data sets to Azure Synapse to unify analytics, data apps and AI/ML workloads on an enterprise cloud data platform.
Fivetran’s automated data movement platform handles just about any source type including applications, events and files, but I’ll focus on database sources for now. Databases are updated frequently, so capturing and persisting those changes on a timely basis to Synapse is foundational. Ultimately, it’s about delivering timely, usable and trusted data with data movement pipelines that don’t break. As outlined in the Fivetran documentation, database connectors are designed for correctness and safety. Correctness means that the destination is always an accurate replica of the database source. Safety means that no matter what, Fivetran should never cause problems in the source database.
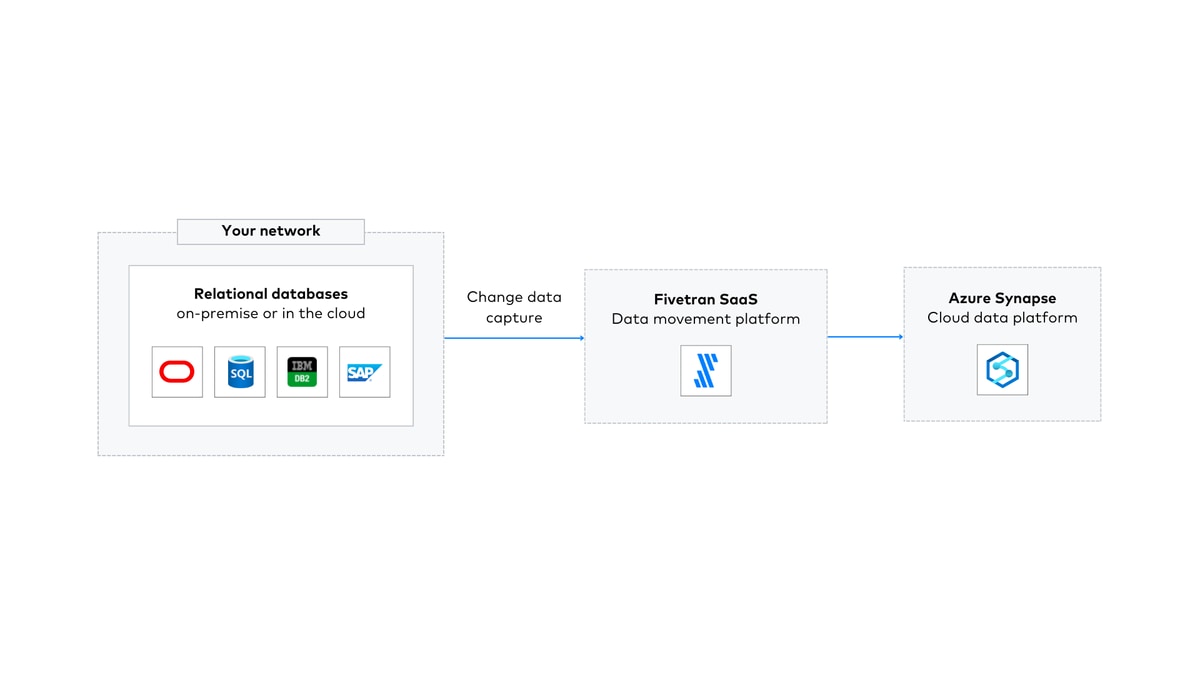
So how does Fivetran’s fast, simple and self-serve approach work when I’m using Synapse as my cloud data platform for analytics workloads?
Let’s get to it.
Setting up Synapse with Fivetran
I’ll assume that Azure Synapse is already setup in your Azure account, but if not, you can check out this how-to video that takes you through end-to-end Synapse setup from scratch — including creating a dedicated SQL pool, setting up an ADLS storage account, creating a Synapse workspace and using Synapse studio.
{kind=link}
Just like setting up any destination in Fivetran, Synapse is quick and simple to set up. Make sure you have the Synapse connected server name (host name), username and password and the Synapse database name from your SQL pools, and determine how you want to connect (there are multiple options here depending on your requirements) and that’s it.
450+ sources to connect to Synapse — let’s go with Oracle
Once you have Synapse set up as a destination, you can choose from 450+ sources across multiple categories including databases, applications, files and events. Keep an eye on that 450 number as it seems to increase daily (thanks to the Fivetran engineering team!)

I’ll focus on Oracle database connectors for this example. You can see the range of Oracle options that are available. I’ll choose Oracle RDS as my source.
Setting up an Oracle database source in Fivetran, regardless of the flavor of Oracle, is simple and standardized. When I need some support, I have access to the Setup Guide in the right gray navigation bar. Fivetran needs to be able to authenticate to the Oracle RDS database, so I’ll provide those credentials.
I also need to choose how I want to connect to Oracle RDS (the same thing I did when setting up Synapse as a destination earlier). I won’t go into this in detail, because Fivetran’s docs provide a Choose the Right Database Connection Option guide here that you can review. At a high level, there are five options today that span connecting directly to the Oracle RDS database to connecting via PrivateLink which keeps any traffic from being exposed to the public internet (Fivetran always encrypts any data in motion using Transport Layer Security (TLS) and any data that is ephemerally at rest as well (AES256).
So far, so good in terms of keeping things simple and no code when connecting Oracle to Synapse.
Lastly, I need to let Fivetran know my Update Method or how I want Fivetran to capture changes for this Oracle RDS connector. The two options I have for this Standard connector are log-based with Log Miner and — if I want to go with a log-less option — I can choose Teleport sync. Update methods vary depending on the database (Oracle options will be different than SQL Server options which will be different than PostgreSQL options, etc.).
Additionally, update options vary based on the type of Fivetran database connector and deployment option used. You can see the Fivetran Standard Oracle RDS connector options below. If I were to use a High Volume Agent (HVA) connector, I’d ensure that supplemental logging was turned on for the Oracle database. Likewise for Fivetran HVR. You can check out this link for the benefits (speed, bandwidth and security) of this approach for any databases that generate large amounts of data or have an extensive historical data repository. Also, the capture methods available for Oracle using HVR are here.
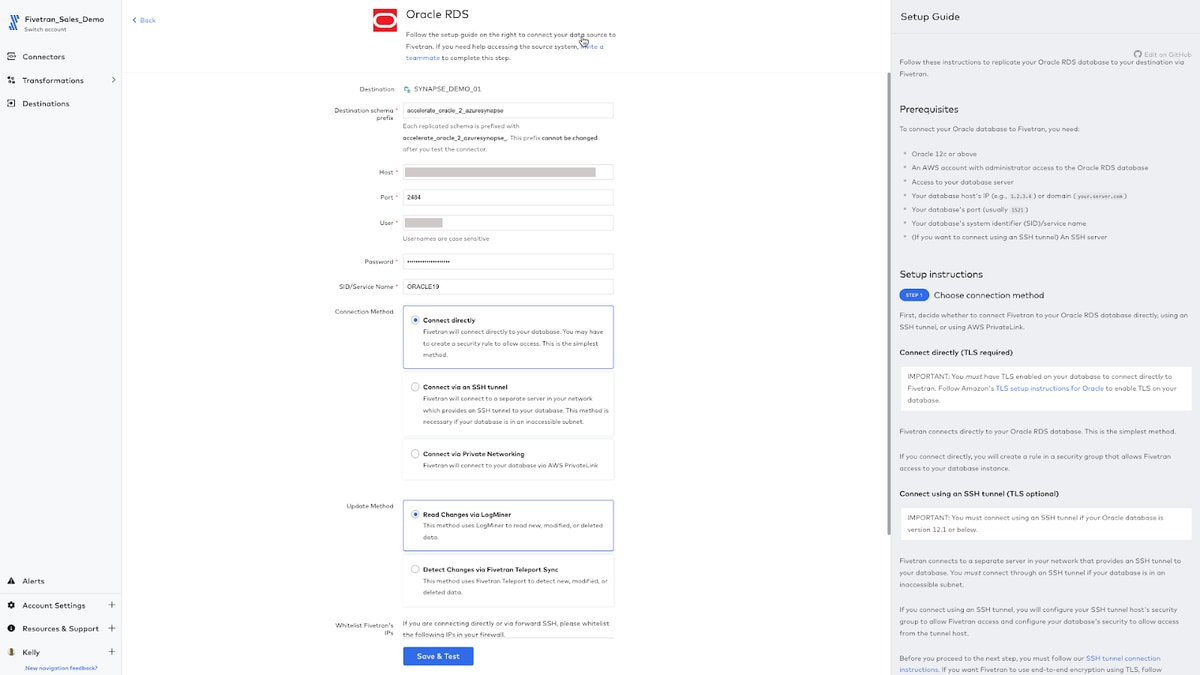
Next, for this connector, I’ll specify which schemas, tables and columns I want to sync from Oracle RDS to Synapse. I could simply select all schemas, all tables and all columns (or any combo) but in this case —I chose to block all schemas but AGRICULTURE, and I’ve decided to move just two tables: CALIFORNIA_WINE_PRODUCTION and COFFEE_PRICES (two of my favorite drinks). I can always adjust my source dataset later on for this connector.

Depending on your requirements, Fivetran incremental change data capture for Oracle as a source can be dialed in to “continuous” for HVR (more on that later), one minute for High Volume Agent (HVA) connectors and as low as five minutes for Standard connectors. Fivetran will automatically set this connector up for incremental syncs for this dataset with a default of six hours which I can adjust up or down as needed for my use case.
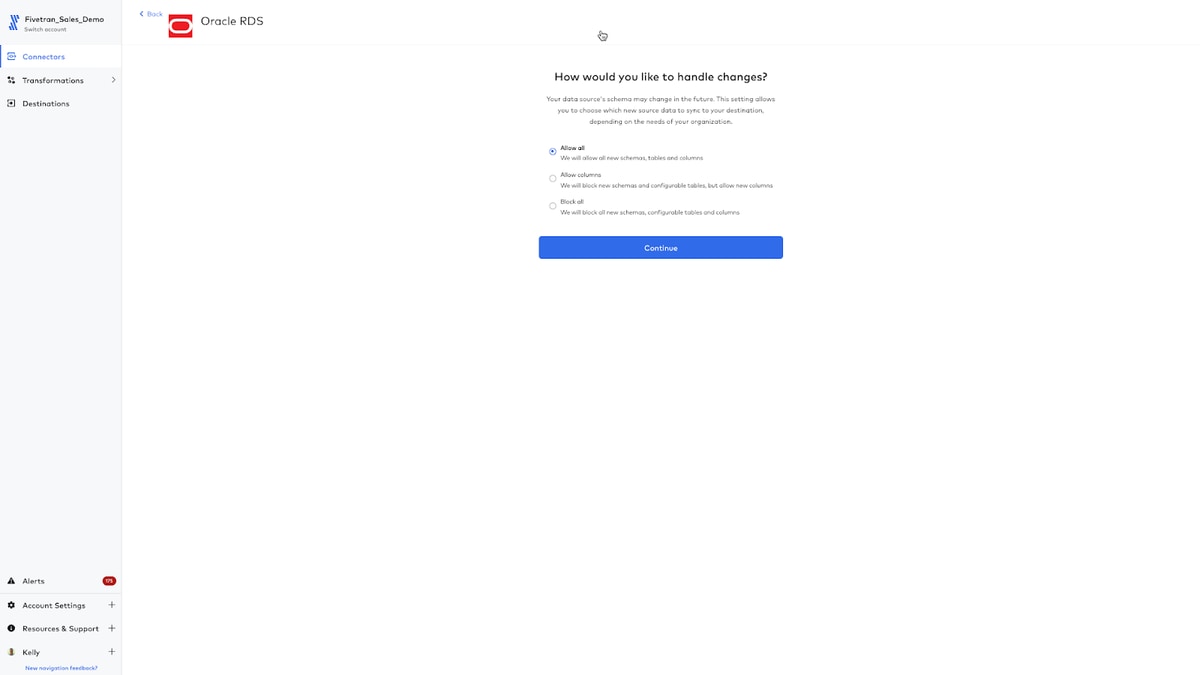
And that’s it! I fired off the initial, historical sync and it was completed in under one minute. My incremental sync is also set up and Fivetran will move any changes for that Oracle database incrementally via change data capture to Synapse.
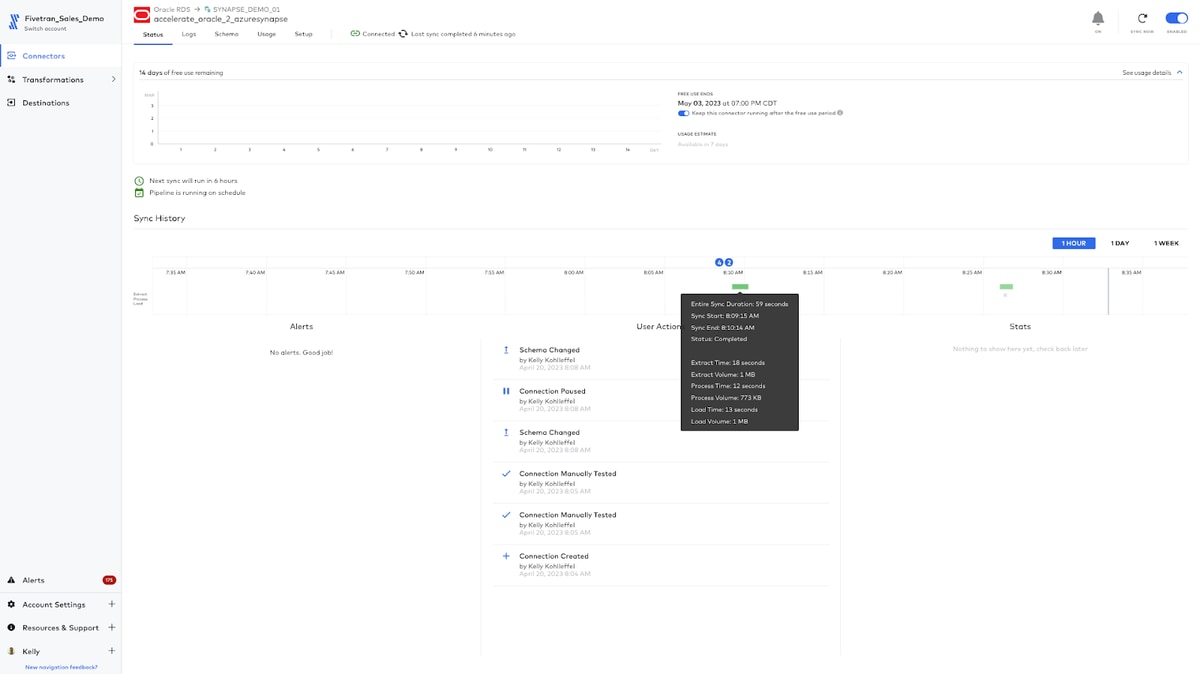
Key Learnings for Fivetran and Azure Synapse with Oracle as a source
10 minutes (or less) is all the time you need to onboard any database source (on-premise or cloud) to Azure Synapse with Fivetran and be set up for both historical and incremental syncs.
100 is the percentage of data that always loads, is verifiably correct, flexible to changing downstream needs and organized & understandable. Fivetran normalizes the data with automatic data updates (DML), automatic schema replication (DDL), automated recovery from failure and efficient writes to Synapse to help lower compute costs.
0 is the amount of effort required from data engineering and development teams or for ongoing operational maintenance since Fivetran is no-code, fully automated, and fully managed.
Consuming data in Synapse
So let’s take a look at our new dataset in Synapse. I like the flexibility that Synapse gives you for quick and easy access to data and thought I’d show you three different ways that I typically consume data in Synapse.
Azure Synapse Analytics Data Studio
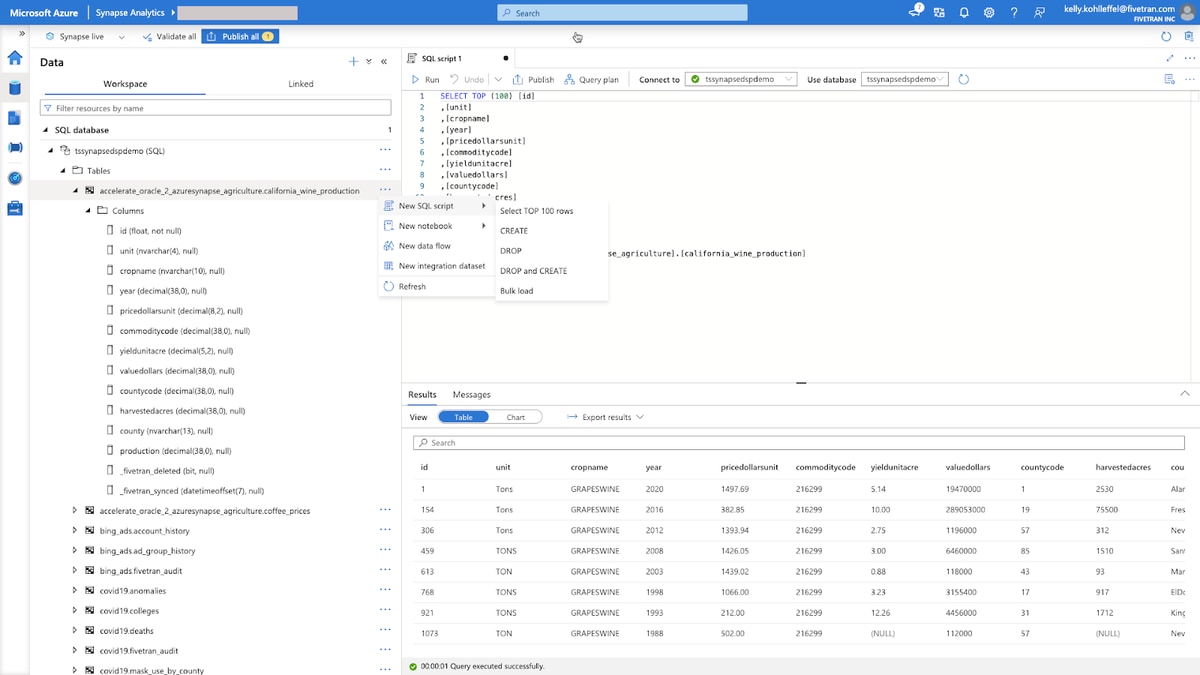
This is the Synapse Analytics UI and it provides a range of features and capabilities for working with the next dataset. Below you can see the schema name (aka connector name plus source schema name) that I used for this Oracle RDS to Synapse connector (accelerate_oracle_2_azuresynapse_agriculture). That schema name was automatically created in Synapse by Fivetran with the initial historical sync. Fivetran will also manage any schema drift over time to ensure that the Oracle source to Synapse destination remains in sync.
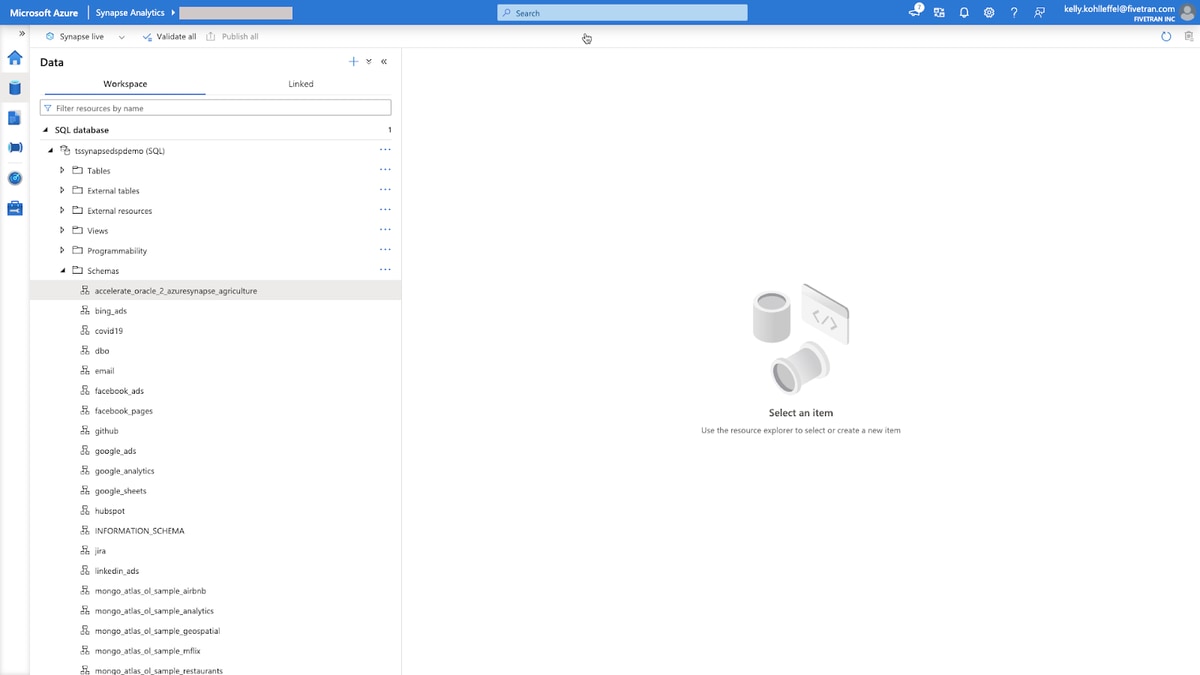
Clicking on “tables” allows me to see both the california_wine_production table and the coffee_prices table and from there I can run any SQL queries that I want against the dataset (in this case a simple Select for the TOP 100 rows), but more importantly, I can continue my downstream analytics engineering workflows to enrich and transform the data in Synapse to get to the final modeled dataset for various use cases.
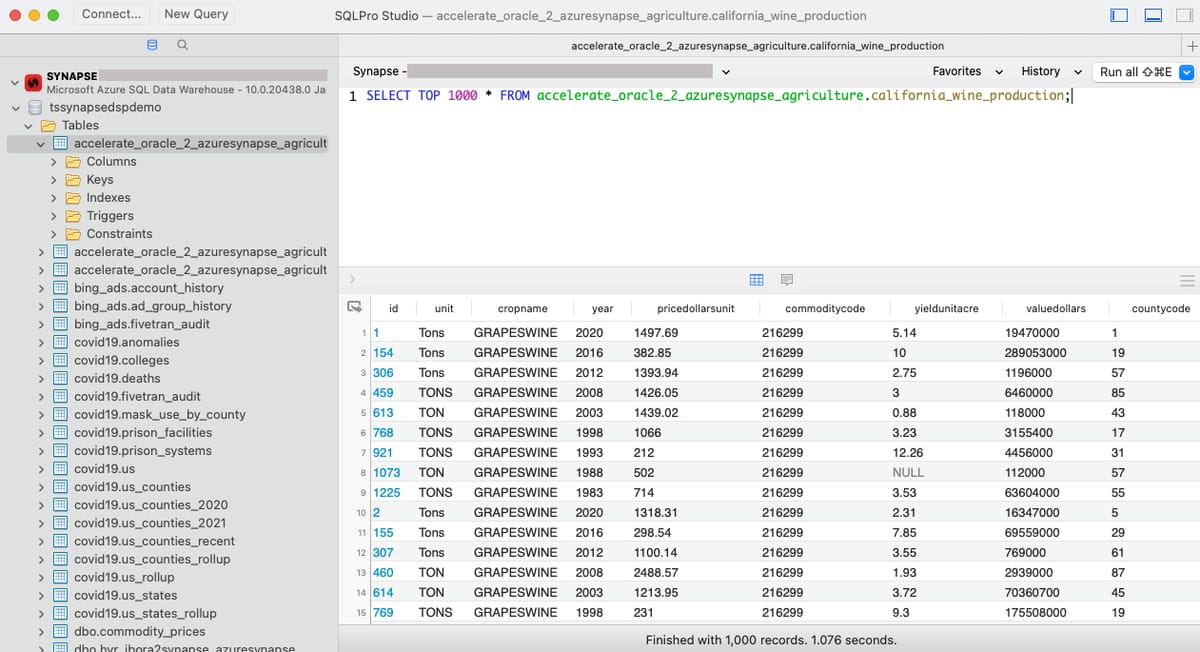
SQLPro Studio and Synapse
SQLPro Studio is my go-to database management client for quick and easy access to just about any database environment — and Synapse was no different. Connecting to Synapse with SQLPro Studio is a snap using SQL Server authentication and you can see below the same accelerate_oracle_2_azuresynapse tables. It’s great for any type of custom query in Synapse and is a 100 percent native Mac app.
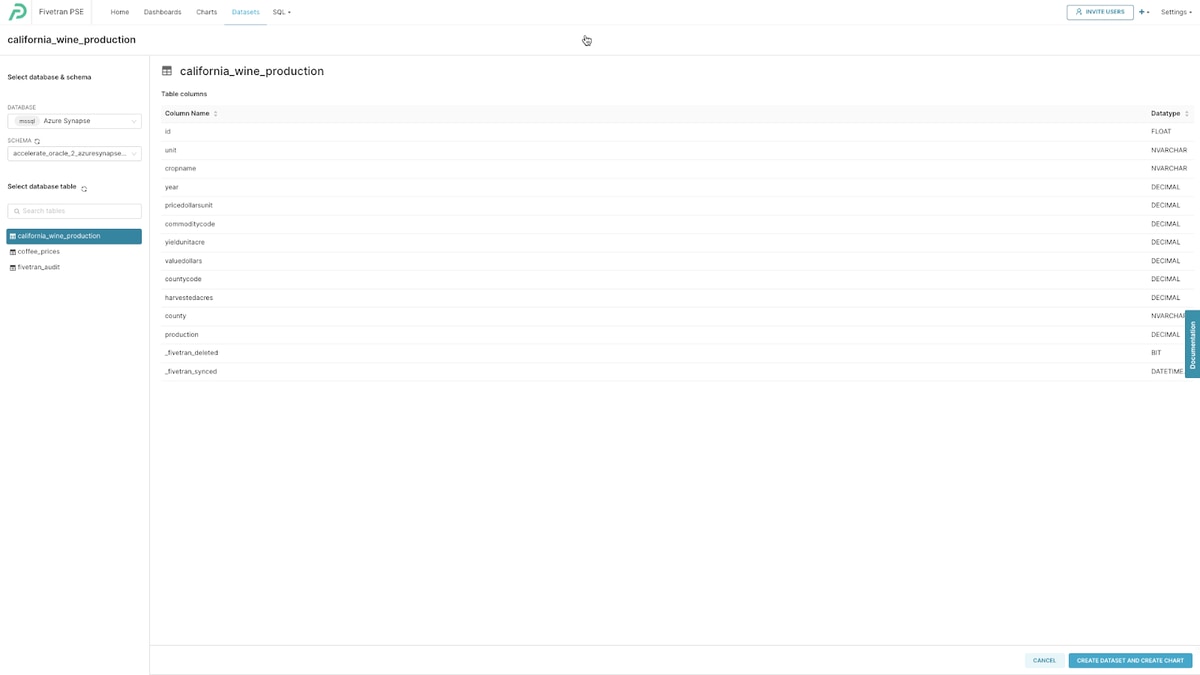
Preset.io and Synapse
Certainly, Power BI is a pervasive BI and analytics tool used by millions of subscribers, but what about a popular open-source visualization tool? How will that connect to Synapse? I enjoy using Preset.io (a fully managed version of open-source Apache Superset) for its slick connectivity to any database and a UI that allows for custom, interactive analytics and instant visualization of any data in Synapse.
Connecting Synapse to Preset is simple (just select Synapse as your database in Preset and add your credentials to the URI connection string below) — linked here:
From there you can select your schema in Synapse accelerate_oracle_2_azuresynapse (by now you know this schema well) and I’ll choose the california_wine_production table.
There’s a range of charting options to visualize your Synapse dataset and for what I want to show here, but I’ll use the traditional bar chart.
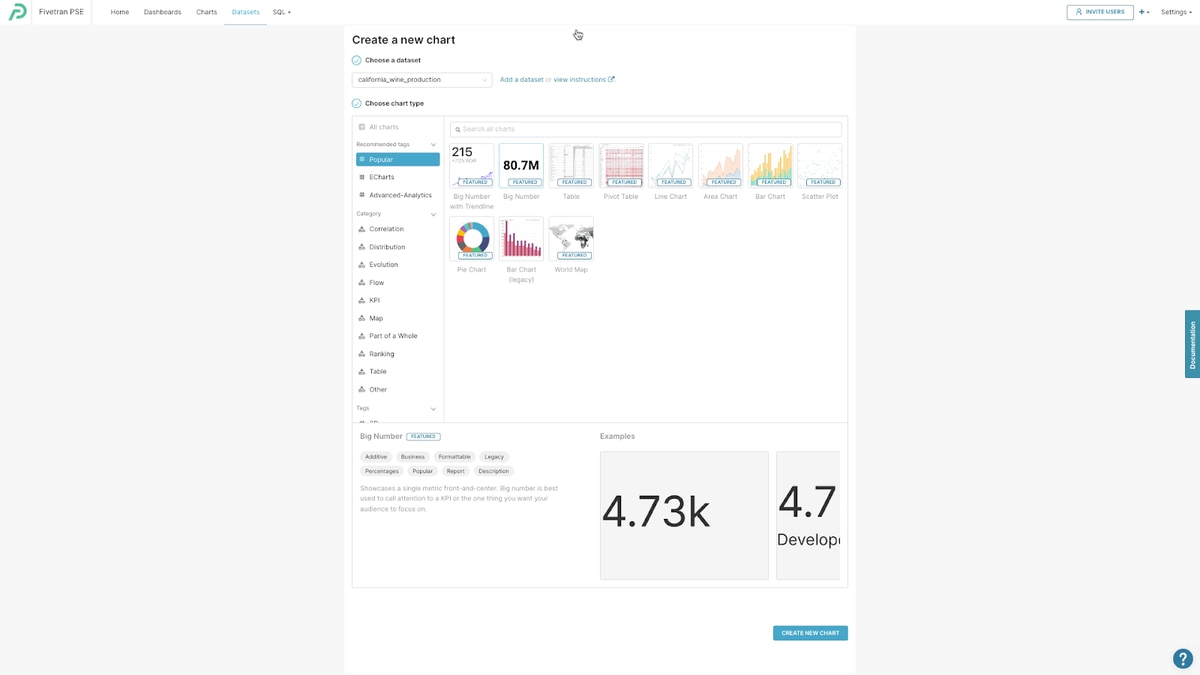
Just drag and drop the columns onto the x-axis and metric sections in the Preset UI, click “Update Chart” and you’ve got a visualization for the 1980-2020 Production Yield Units per Acre for California.
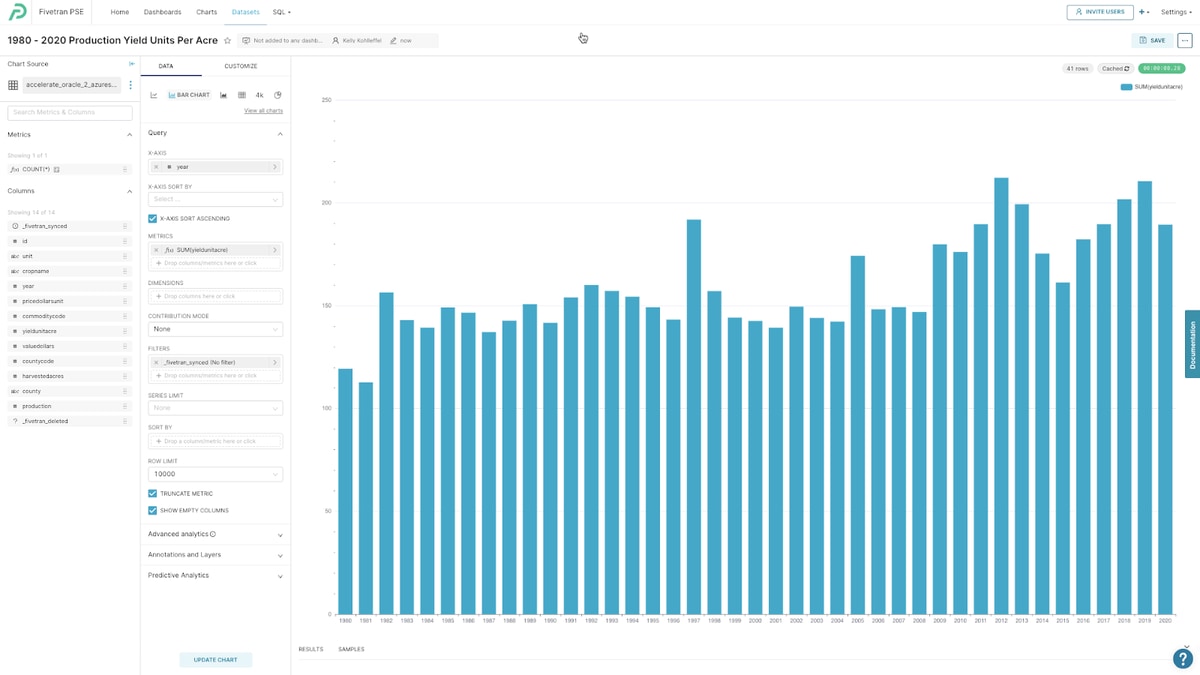
And there you have it. Three great ways to visualize and consume Oracle data that’s been moved by Fivetran into Synapse.
Fivetran SaaS HVA and Azure Synapse
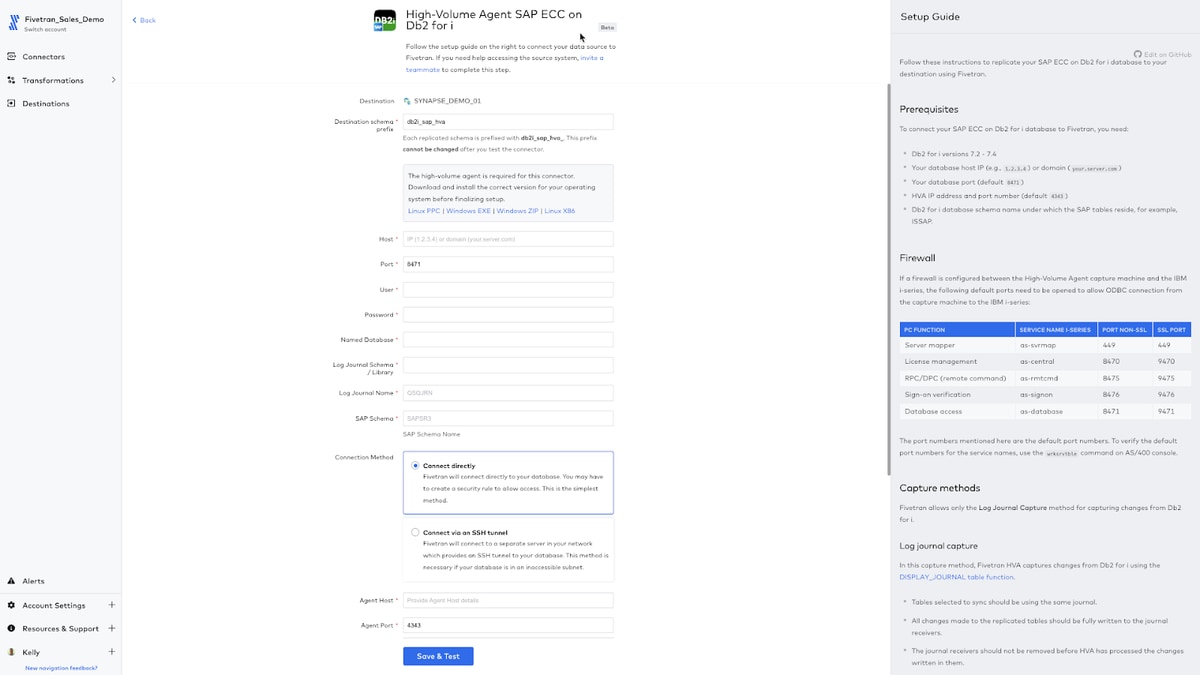
I mentioned earlier Fivetran SaaS High Volume Agent connectors and it’s worth noting that thousands of enterprise Microsoft customers also use SAP ERP. I won’t step through it here, but when SAP is needed as a source for Synapse, Fivetran has you covered whether SAP is running on Hana, Oracle, SQL Server or even DB2i. Below is the connector setup page for Fivetran High Volume Agent (HVA) SAP ECC on DB2i to Synapse. It doesn’t get much easier than that to connect SAP ECC to Synapse (look for a full walkthrough in a future post).
The only difference between an HVA connector and a standard connector which we just walked through is deploying the agent at the source (more about that in a moment) and providing those agent credentials in the setup form.
HVR and Azure Synapse
So far, I’ve reviewed the Fivetran SaaS deployment options with Synapse and source databases, but what about a scenario where you need to deploy Fivetran on-premise or in your own cloud infrastructure, such as in Azure VMs, and then move data to Synapse? We have you covered for that deployment option as well with Fivetran's HVR.
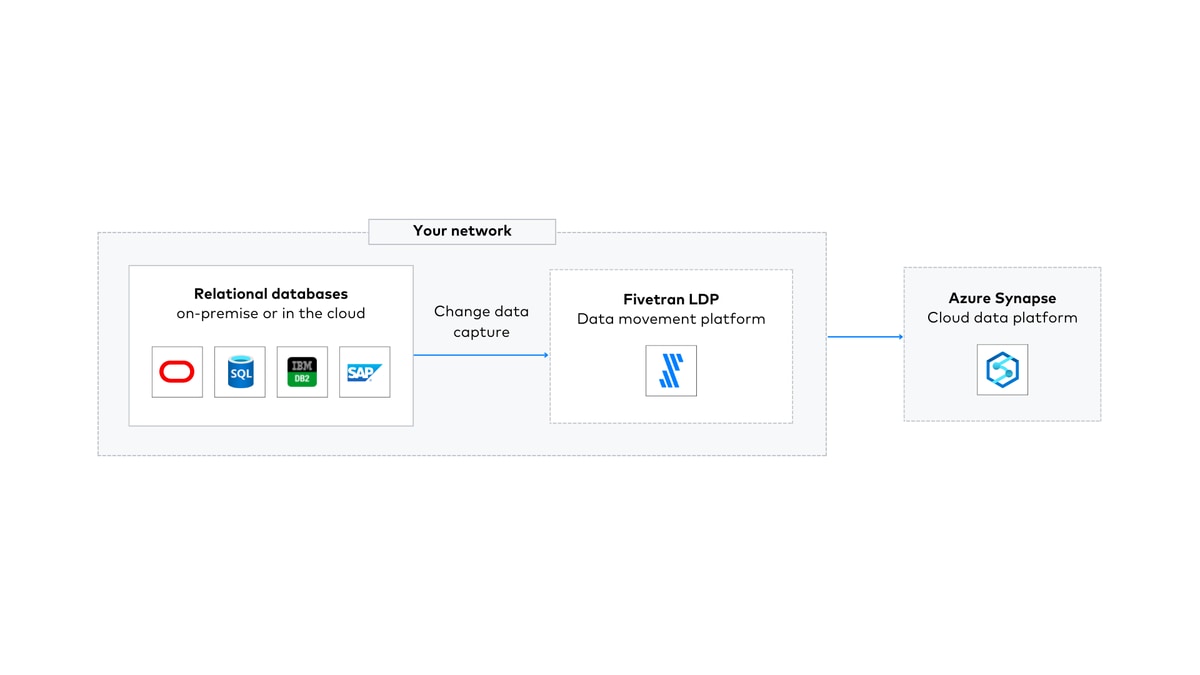
You can check out all the details on HVR here and below I’ll walk you through a quick example of setting up SAP Hana to Azure Synapse replication with HVR. Just like with Fivetran SaaS HVA connectors, you’ll deploy an agent at the source for HVR, and that will provide low latency and high throughput (agents provide filtering, compression, and encryption — and allow max performance for high volume database and SAP environments) with a very light footprint.
For this data movement channel in HVR, I simply select my source location (SAP HANA) and my target/destination location (Azure Synapse) which I’ve previously defined. I can also specify which replication option I want to use based on my requirements and use case.
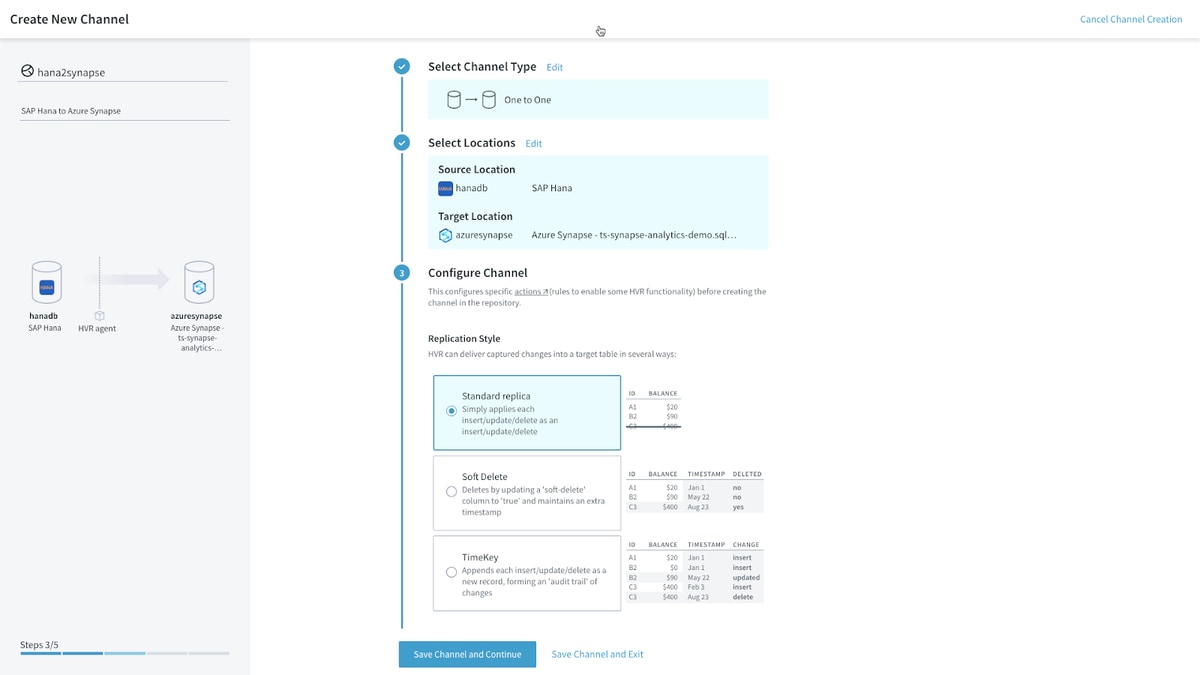
From there, I select the SAP HANA tables that I want to replicate with HVR.

HVR is Continuous replication
Lastly, activate the replication and HVR automatically kicks off multiple jobs including Activate (readying the environment), Refresh (initial, historical sync of my selected dataset), Integrate (replication of the dataset into Azure Synapse) and Capture (continuous incremental sync of all changes / continuous change data capture).
HVR’s replication is not bound by an incremental sync time constraint and flows data continuously from Oracle into Synapse. I told myself that I wouldn’t use the words #eal-#ime —but you likely get the idea.

There are many advanced capabilities and almost unlimited flexibility in HVR — you can check out more HVR concepts here.
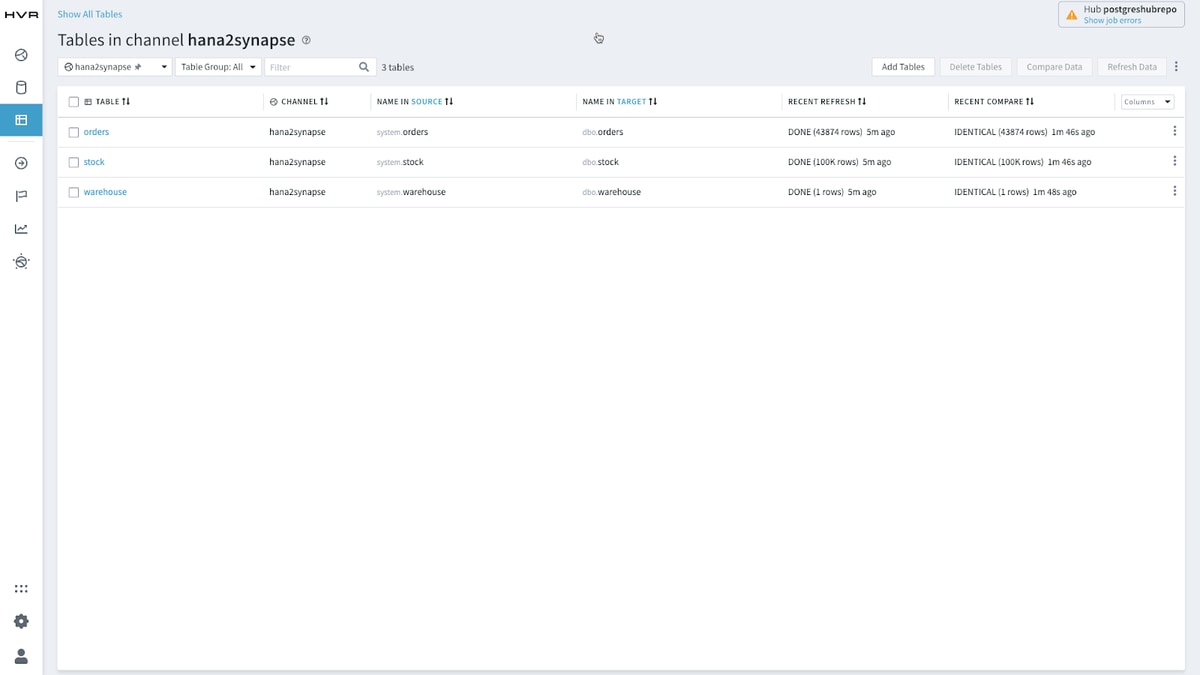
Consuming data in Synapse (this time moved with HVR)
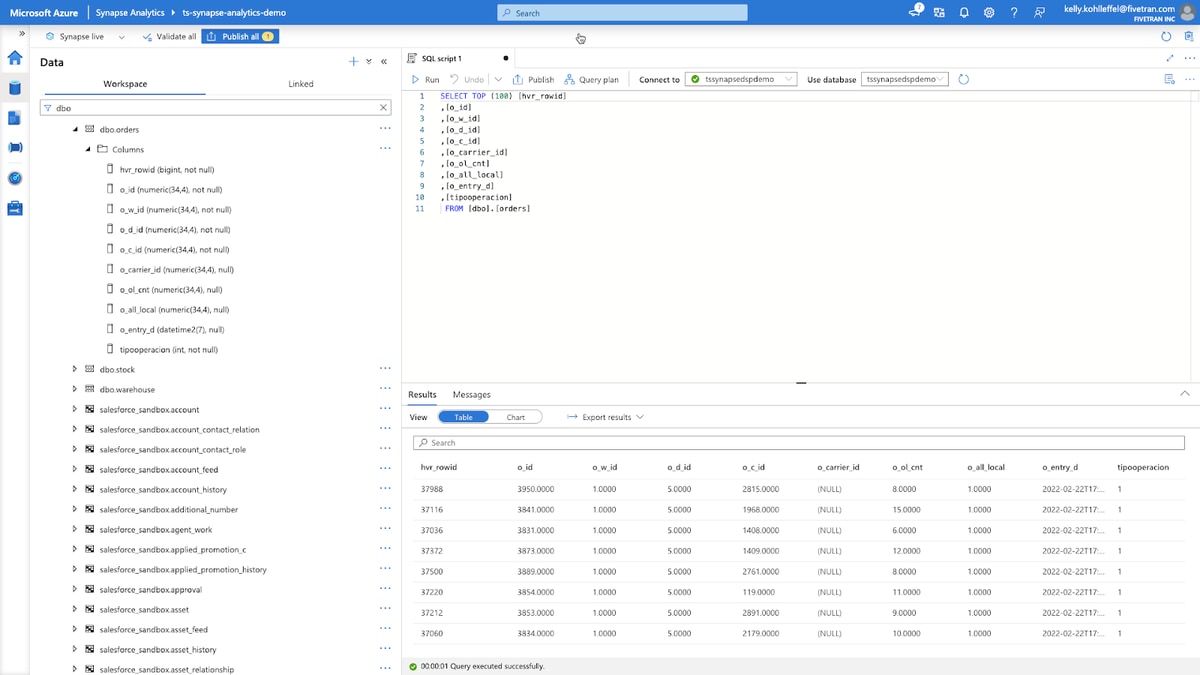
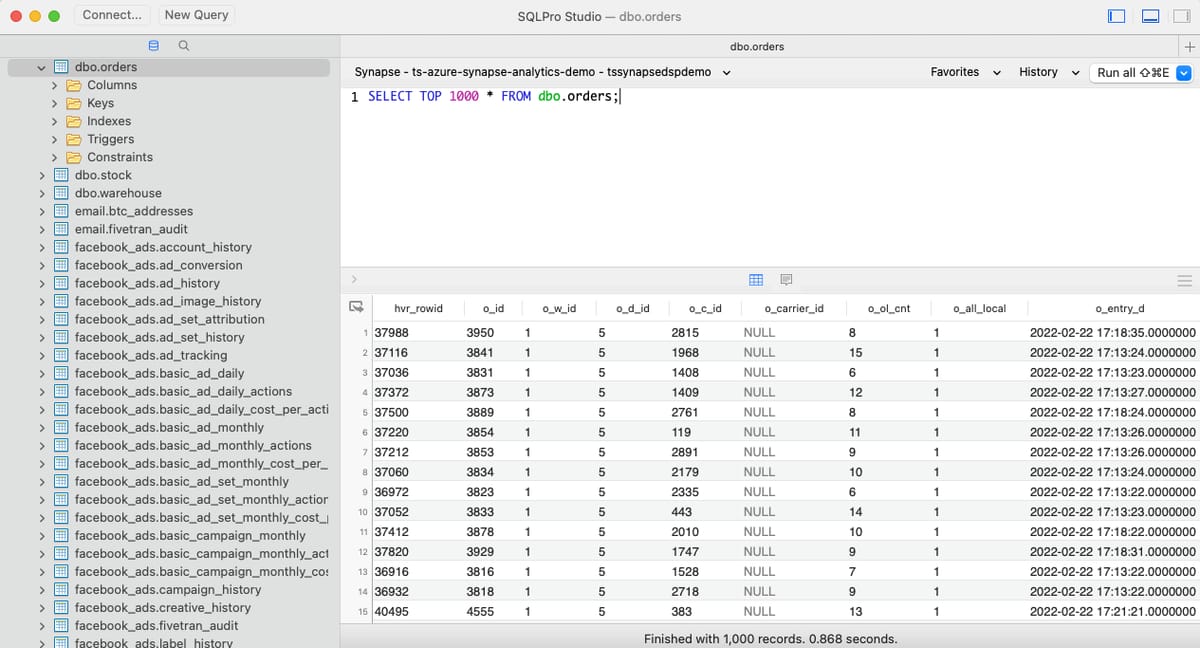
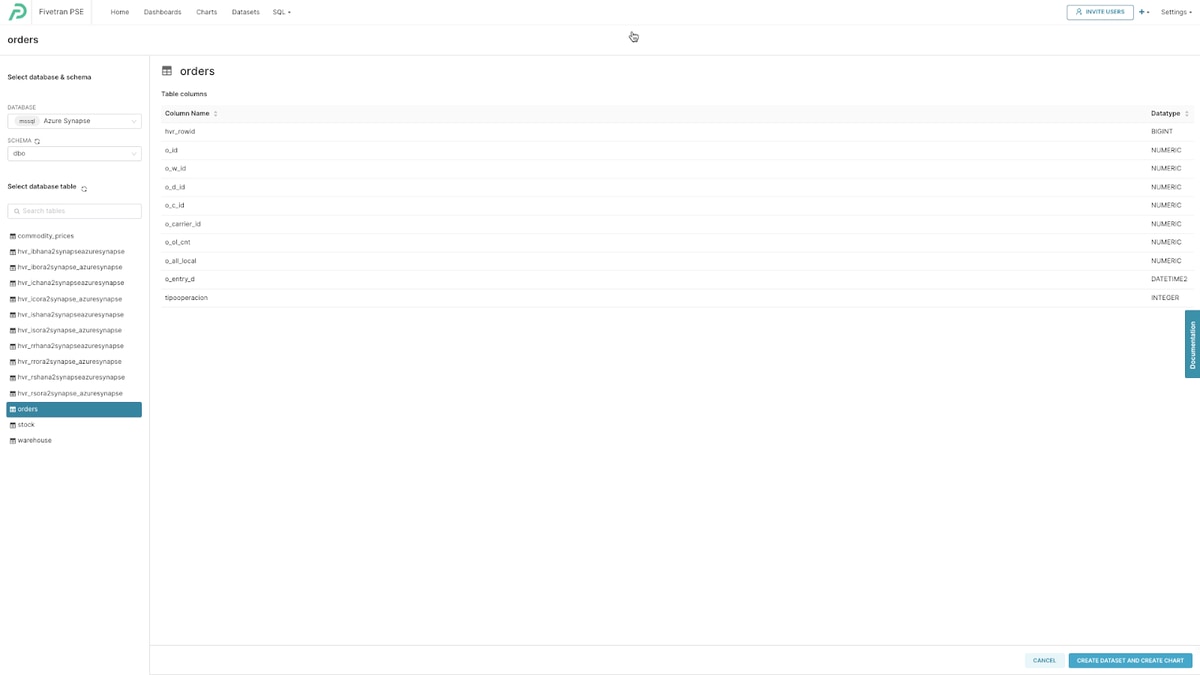
There’s no difference in the range of consumption tools from what you saw earlier and below are those SAP HANA tables moved into Azure Synapse with HVR and consumed with the Azure Synapse Analytics Data Studio, SQLPro Studio and Preset.io.
Azure Synapse Analytics Data Studio
SQLPro Studio
Preset.io
Fivetran supports other Microsoft Azure destinations and sources too!
The spotlight has been on Azure Synapse as a Fivetran destination and Oracle as a source, but it’s worth mentioning that you can use other first-party services in Azure for destinations with Fivetran as well including:
- Azure Databricks
- Azure Azure SQL Database
- Azure PostgreSQL Database
- Azure SQL Managed Instance
- Azure Blob (HVR)
- Azure Data Lake Storage (HVR)
From a data source perspective, Fivetran has many Microsoft connector options available:
- Azure MySQL
- Azure Blob (HVR)
- Azure Boards
- Azure Data Lake Storage (HVR)
- Azure MariaDB
- Azure Event Hubs
- Azure Service Bus
- Azure Blob Storage
- Azure SQL Database
- Azure PostgreSQL Database
- Azure SQL Managed Instance
- Azure Cosmos DB - NoSQL API
- Microsoft Lists
- Microsoft Teams
- Microsoft Contacts
- Microsoft Advertising
- Microsoft Dynamics 365 CRM
- Microsoft Dynamics 365 F&O
- Microsoft Dynamics 365 F/O
- Microsoft Dynamics 365 Business Central
My perspective on ADF and Fivetran
Another question that our partners ask is, “If my customer already has Azure Data Factory, how should I think about using Fivetran?” First, it’s worth acknowledging that all Azure customers have ADF in their data movement tool bag already and it can be used very effectively across many sources and targets.
Second, I tend to avoid recommending any one tool or platform as the be-all-end-all super tool for data movement. Not only are there always exceptions, but business requirements and use cases may dictate how fast you have to deliver a data product or service (this is key to staying relevant in your data program and organization).
- Do I have the time to create from scratch (knowing full well that it’s about more than just building the pipeline) and that operational sustainability plays a big part once that pipeline is delivering data?
- Likewise, if I choose a tool with a lower-code approach, does that meet my “relevancy” SLA?
So, my suggestion is to value business and relevancy metrics as your foundation for determining what approach, tool or platform you use with multiple options in your tool bag.
- How fast does the consumer data product or service need to be delivered to the business?
- Is my data movement approach or the tooling that I plan on using going to complicate my architecture or simplify it?
- Once a data movement pipeline is created, how much work and oversight will be required to operate, maintain and care/feed going forward and what is my appetite to do that work knowing that there are higher value areas for the team to work on?
- Is the pipeline creation going to take an engineering or development team to build and maintain it or is it self-service with idempotency built in?
- What level of latency and scale is required for this data source and ultimately for the data product that the data source is contributing to?
- What about security and governance concerns?
- How immediately usable and trusted is my new dataset when it lands?
- Am I factoring in people costs, maintenance costs, integration costs and all the other costs that should be considered for this one data pipeline?
- If I take a particular approach, do my team and I become more relevant in our overall organization (or business unit) or less relevant?
Final thoughts
Fivetran offers significant value and an obvious “wow” factor in moving data to Azure Synapse to unify analytics, data applications and AI/ML workloads. By providing fully managed and fully automated data movement pipelines that are fast, simple and self-serve, Fivetran helps Microsoft customers accelerate their ability to deliver scalable and sustainable data products and services.
[CTA_MODULE]
_______________________________________________________________________________
About the author
Kelly Kohlleffel leads the Partner Sales Engineering team at Fivetran, where he works with a broad ecosystem of technology and consulting services partners on modern data solutions. He’s been in the data industry for 30 years and before Fivetran, he spent time at Hashmap, Hortonworks and Oracle. You can connect with Kelly on LinkedIn or follow him on Twitter.
[CTA_MODULE]
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







