How to build a customer support chatbot in 15 minutes


AI-powered automation is transforming how businesses leverage data, unlocking new levels of productivity and innovation across industries. At the forefront of this shift are generative AI (GenAI) applications, which utilize retrieval-based methods and large language models (LLMs) to understand and generate human-like content. These applications enable organizations to achieve unprecedented efficiency.
Despite this potential, creating and managing the foundational elements for Generative AI projects, such as Retrieval-augmented generation (RAG) data models, remains a major challenge.
What is retrieval-augmented generation (RAG)?
Retrieval-augmented generation (RAG) is an approach in generative AI that enhances the performance of a foundation model (such as an LLM) by supplementing it with additional data during the generation process. By retrieving relevant business data, you can produce responses that are more informed, accurate, and aligned with your company's unique domain knowledge.
Building high-quality RAG pipelines is often labor-intensive and error-prone. Key steps, like provisioning vector databases, embedding source documents and queries, conducting similarity searches to retrieve relevant content, and fine-tuning outputs, require significant effort and expertise.
Even after investing significant time in these processes, you may face persistent issues, such as poor data quality, irrelevant document retrieval, or slow response times, hindering AI performance and delaying innovation.
Introducing Fivetran’s GenAI-Ready Data Model
To address these challenges and simplify the process, we’ve developed the GenAI-Ready Data Model - Fivetran’s pre-built data model that enables you to turn data from popular sources like Zendesk, Jira, and HubSpot into GenAI-ready tables with the click of a button. The model formats unstructured document data into manageable chunks of text, vectorizes each chunk, and stores it in a destination for seamless AI model processing.
With these models, you can quickly build and deploy intelligent tools, such as AI-powered search assistants or customer sentiment analyzers, with minimal technical effort or setup. Fivetran customers are already realizing significant value from the model, particularly in customer support operations. Teams are using it to power AI-driven chatbots that surface insights in seconds, integrate seamlessly with existing systems, and adapt to their unique knowledge base—enabling faster, more personalized support and driving customer loyalty.
"By leveraging GenAI-ready data models, we can quickly categorize tickets and model raw data from Zendesk, enabling support analysts to surface solutions instantly based on past resolutions. Additionally, these models empower our engineering leaders to uncover themes from Jira tickets, gain insights into developer effort and client engagement, and identify key investment opportunities. - Head of Growth at a prominent financial services firm in New York
Repetitive requests and recurring issues that often require manual searching or collaboration across multiple teams have often already been resolved in the past and documented in tools like Zendesk or Jira but require rework, customization, or additional research when they arise again. A RAG application streamlines this process by automatically retrieving relevant context from historical data and generating intelligent responses. This approach significantly reduces resolution times and resource demands for support teams.
Internally, our GenAI-Ready Data Model powers a widely used internal chatbot for Fivetran employees—FivetranChat. Handling hundreds of queries per day with an 85% user satisfaction rate, the chatbot operates at minimal cost. It leverages proprietary data from sources such as Zendesk, Slack, Salesforce, and Google Drive to provide accurate, context-rich answers to questions about Fivetran's products, operations, and policies. By reducing the need for manual document searches or person-to-person queries, FivetranChat streamlines workflows, enhances productivity, and resolves routine inquiries efficiently. It is accessible via Slack and is especially popular among technical and customer-facing teams.
How to get started?
Now let’s explore how you can use the GenAI-Ready Data Model to power your own customer support chatbot. We’ll walk through each step of the process, from setting up a data model to embedding it for semantic search, and even building a custom application.
Prerequisites
For non-Fivetran customers, we offer a unique 14-day free trial to get started instantly.
Before setting up the data model and the chatbot, you should ensure you have set up at least one of the supported data sources in Fivetran’s GenAI-ready Data Model such as Zendesk, Jira, or Hubspot.
Steps to set up the GenAI-Ready Data Model
- Navigate to the Transformations Page:
In the Fivetran dashboard, go to the Transformations page and select the destination where you want to build the model. Navigate to the Quickstart section and click on ‘Add data model.’ - Select Your Data Sources:
Choose the knowledge sources you want to include for your support co-pilot, such as Zendesk, HubSpot, and Jira. - Build the Model:
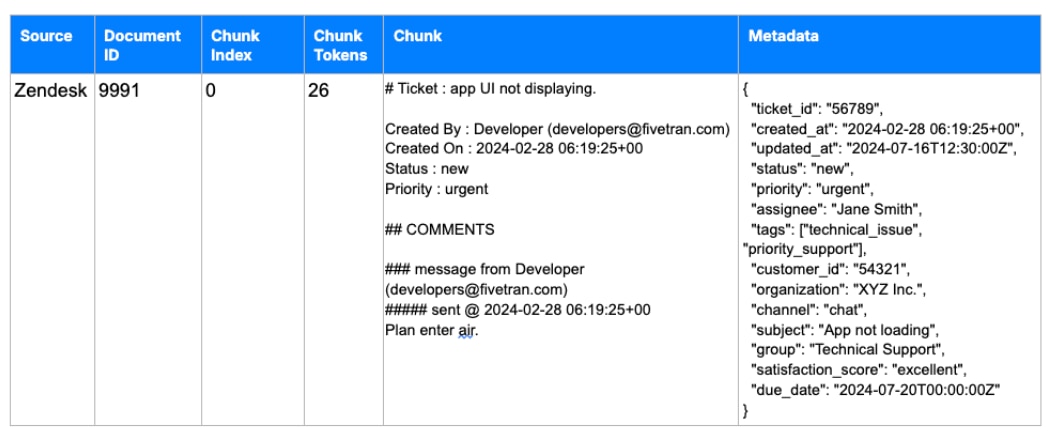
Upon setup, Fivetran will create an output table in your destination called rag__unified_document.
Each record in this table represents a chunk of text prepared for semantic search and includes fields such as:- Source (e.g., Zendesk ticket, HubSpot account)
- Document ID
- Chunk Text
- Chunk Index
- Metadata
Creating the Cortex Search Service
With the data now prepared in the rag__unified_document table, the next step is to create a Cortex search object in Snowflake. Cortex Search is a fully managed service that automatically generates vector embeddings for your text data, combines them with keyword indexes, and keeps everything refreshed behind the scenes. Cortex Search’s “hybrid” approach—semantic + keyword search—enables you to quickly retrieve the most relevant content for tasks like retrieval-augmented generation (RAG).
This saves you from setting up separate infrastructure or custom pipelines for embedding and indexing. It also offers built-in semantic re-ranking for more accurate search results, so you can spend less time on tuning search parameters and more time creating AI-driven applications, such as chatbots and intelligent search assistants.
Set up the Search Service:
Use the following SQL statement to create a Cortex Search Service object. Replace <insert_database_name> with the name of your database containing the rag__unified_document table and replace <insert_warehouse_name> with the warehouse you want the service to use:
Creating a chat interface using Streamlit
Streamlit is an open-source framework that makes it quick and easy to build interactive data applications with minimal code. By using Streamlit, you can spin up a custom chat UI for your support agents—giving them immediate access to context-rich answers drawn from their Snowflake-hosted knowledge base.
Fivetran has built an example Streamlit application to demonstrate how customers can quickly create an enterprise ChatGPT-like interface, grounded in your own data.
Before getting started, you must have Python 3.9+, pip and git installed on a local machine.
Follow these steps to set this up:
- Clone the repository
- Checkout the Snowflake Chat branch
- Install Python dependencies
- Deploy via Streamlit
If running locally, open a terminal in the project directory and run:
Once the app starts, you’ll receive a local URL where you can test the chat functionality.
- Test the Interface
Navigate to the Streamlit URL in your browser, type in your Snowflake instance information and start asking questions. The interface will use your Cortex Search Service to retrieve relevant chunks of data and provide AI-driven, contextual answers.

- Publish Your App
Streamlit Cloud: Push the repo to your own GitHub and connect to your Streamlit account to share with others in your organization.
Snowflake: Alternatively, leverage Snowsight to securely deploy and distribute the app internally.
With just a few commands, you can give your support agents an intuitive, self-service chatbot that taps directly into your latest Zendesk, Jira, or HubSpot data—helping you solve customer issues faster and more accurately.
Unlock the power of Fivetran—start your free trial now. Start building smart chatbots with this step-by-step video walkthrough.
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







