How our product team uses AI to manage customer feedback at scale


At Fivetran, we manage over 700 connectors, each with its own stream of feature requests and customer feedback. For our product team, this is both a blessing and a curse: we have an incredibly rich signal about what customers want, but the sheer volume can be overwhelming. The traditional approach of manually triaging requests, researching feasibility, and communicating with customers simply doesn't scale.
To address this challenge, we built an internal tool that integrates the data from multiple sources with AI agents. The result is a customer feedback intelligence platform that uses Fivetran connectors and Activations, BigQuery, dbt, and AI agents to help product managers stay on top of thousands of feature requests.
[CTA_MODULE]
A problem of scale
Our connector portfolio spans every major SaaS application ecosystem—Salesforce, Workday, SAP, Oracle, Microsoft, and hundreds more. Each connector has its own set of feature requests coming from multiple channels:
- Fivetran feature request portal — where customers submit and vote on feature ideas
- Salesforce — captured by our sales team during customer conversations
- Jira — where our product team maintains their product backlog
- Support tickets — escalations from customer success and support teams
Before this tool existed, our product managers spent hours each week manually correlating data across these systems to determine which requests were valid, which would have the most impact, were technically feasible, and had already been addressed. The feedback loop was slow, and requests too often fell through the cracks. Even when we completed a request, we would often miss notifying the customer.
Combining agentic AI with data integration
We built an internal application that demonstrates the value of centralizing all your business data using the same tools we recommend to our customers.
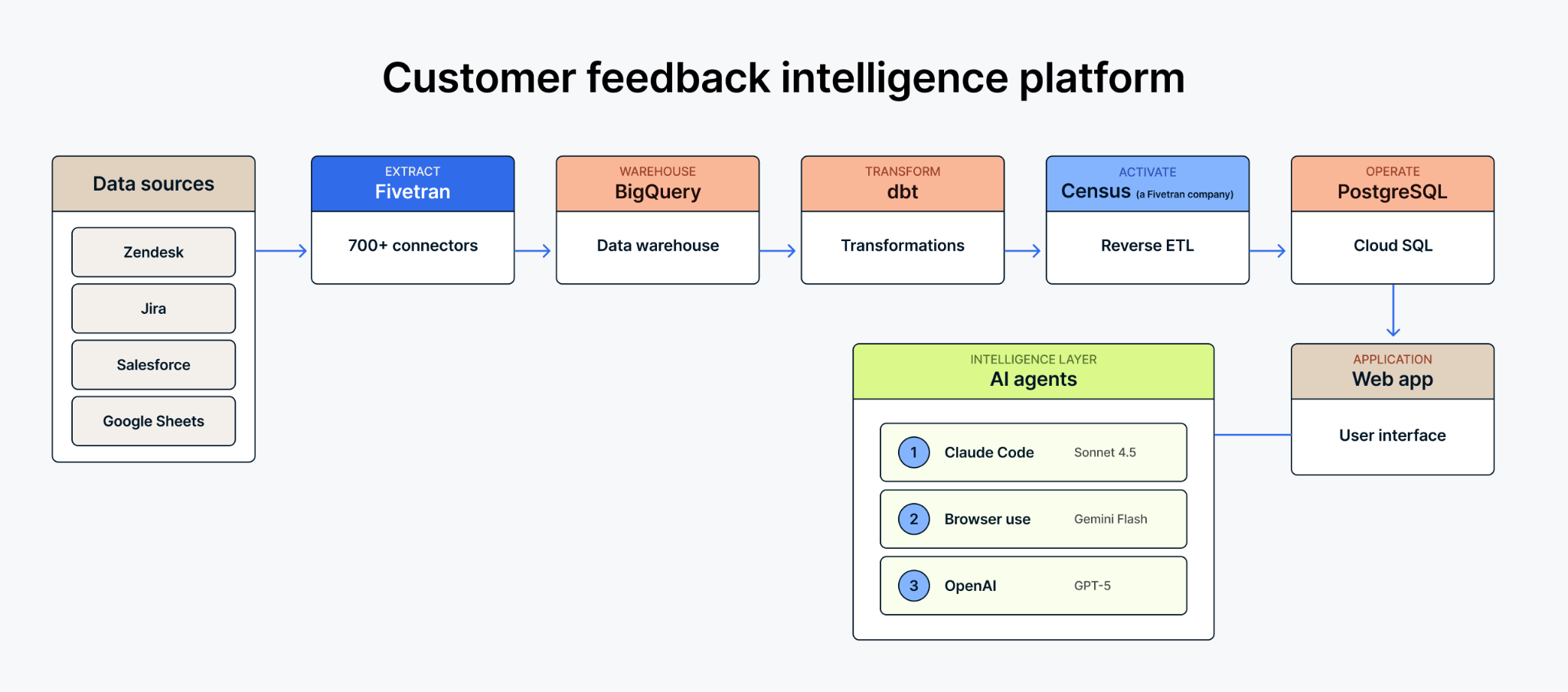
Data integration with Fivetran connectors
We use Fivetran connectors to pull data from our operational systems into BigQuery:
- Zendesk syncs forum posts, comments, and user engagement data
- Jira brings in task status, sprint assignments, and engineering priorities
- Salesforce captures feature requests tied to new deals, upsells, and renewals
- Google Sheets loads product manager ownership mappings and manual reference data
All this data lands in our BigQuery data warehouse, giving us a single source of truth for feature request intelligence.
Transformation with dbt
Raw data from these sources isn't immediately useful. We use dbt models to transform and join the data into a unified feature_requests model that combines Zendesk forum posts with Jira linkage, Salesforce opportunity data, customer ARR, and PM mappings. This materialized view gives us a complete picture of every request — its source, its business impact, product area and its status.
Data activation
Here's where it gets interesting. Analytics data in BigQuery is great for dashboards, but it's not ideal for a responsive application. We use Fivetran Activation to sync our materialized feature request data from BigQuery to a Cloud SQL PostgreSQL database. Our activation runs hourly on weekdays, keeping the app's operational data store fresh with the latest requests.
This reverse ETL pattern bridges the gap between analytics and operations—the same pattern we help our customers implement for their own use cases.
The application layer
The front end is a React application with Firebase Functions handling the backend. Product managers can search, filter, and browse feature requests by connector, product manager, source system, or status. The PostgreSQL database provides low-latency queries that make the experience feel instant.
The AI layer: Where the productivity begins
Data infrastructure is essential for enabling every analytical and operational use of data, but the real productivity gains come from the AI components we've layered on top.
Multi-agent triage system
When a PM selects a feature request for deeper analysis, our system kicks off a three-step AI agent workflow:
- Assessment agent (built with Claude Agent SDK) — Analyzes the feature request alongside our current implementation, reads our internal documentation such as our product principles, and documents and formulates research questions for the browser agent.
- Browser agent — A browser use agent to gather external signals and information from the internet, such as reviewing API documentation and other information required for the triage.
- Synthesis agent (built with Claude Agent SDK) — Combines all findings into a feasibility report with effort estimates and implementation recommendations.
The output is a complete report that includes a feasibility assessment, “T-shirt sizing” effort estimates, API research findings with evidence, and a pre-formatted command that triggers an implementation agent.
AI-powered customer communication
Once a PM has context for a request, the tool helps generate personalized customer outreach. Using OpenAI’s latest GPT model, the system can draft emails for different scenarios.
The AI drafts are personalized based on the customer's history, the feature context, and the PM's communication style. This cuts email drafting time from minutes to seconds while maintaining the human touch that customers expect. There is always a PM in the loop reviewing and editing the messages before they are sent; as powerful as AI is, present-day agents still require quite a bit of human supervision.
The business impact
This isn't just a cool internal project—it's changing how we operate:
- Faster response times — Feature requests surface in the app within an hour of submission, and are enriched with the information PMs need to act on them
- Better prioritization — PMs can instantly see which requests have the highest customer impact and demand
- Closed feedback loops — Customers hear back about their requests, improving satisfaction and trust
- Reduced cognitive load — AI handles the research-intensive triage work, freeing PMs to focus on reviewing/validating findings and making strategic decisions
Lessons for building AI-powered applications
Building this system taught us several lessons that apply to any organization looking to layer AI on their data:
- AI needs clean, consolidated data — The multi-agent system only works because our data team has done the hard work of bringing data together from disparate sources.
- Start with the workflow, not the technology — We built this tool because PMs were drowning in triaging feature requests, not because we wanted to experiment with AI. The technology serves the workflow.
- Different models excel at different tasks — We use Claude for agentic analysis and synthesis, Gemini for browser automation, and OpenAI models for email generation. Match the model to the task.
- You need the flexibility to move data where it is needed — Reverse ETL, for instance, unlocked our operational use cases, moving centralized data from BigQuery into a PostgreSQL backend. Your analytics warehouse is great for analysis but often too slow for applications.
[CTA_MODULE]
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







