How HubSpot’s analytics engineering team gained pipeline autonomy


At HubSpot, people are important. That includes our customers, our customers’ customers and our own employees. We’re focused on doing what’s best for all parties, based on the data we possess.
As a member of the analytics engineering team, it's my job to take our people data and turn it into reporting and analytics. Data sources like Greenhouse and Workday hold invaluable insights for human resources. But, we need the proper tools and processes to unlock them.
Previously, this required working with an engineering team to extract and load data into a warehouse where I could then access and transform it into reporting. While this worked, it wasn’t efficient or automated, as I was dependent on other teams with other priorities. What I needed was access to clean, modeled data, efficiently.
That’s what I found with Fivetran. With time, not only was I able to access data quicker, but do so autonomously, ensuring pipelines worked as I wanted them. I now control all of my necessary data sources — from Workday to Greenhouse, to custom Google Sheets data sources. Data now moves when and how I need it.
And, with their dbt™ integration, I save even more time. Any analytics engineer understands the importance of modeled data. With Fivetran Transformations for dbt Core, I have greater modeling and orchestration capabilities that expedite some of the foundational parts of data transformations (like staging tables), freeing up my time for more advanced data exploration.
The best part? It’s so easy! Let me walk you through an example of how my team uses Fivetran’s dbt offering to accelerate our time to insight:
Orienting yourself
When working with disparate, large datasets, it’s important to have a centralized data strategy. Without the proper people, processes or tools, you end up spending more time on data preparation than data action. Fortunately, with Fivetran, we’ve been able to find the processes and tools that help us turn our data into one centralized strategy for data-driven people growth.
There are two connections that underpin Fivetran - connecting to your data warehouse through the Destination tab and to your Github account in the Transformation tab. This lets Fivetran load data into your warehouse and orchestrate your dbt project.
Utilizing Fivetran’s pre-built dbt data models
A useful tool that Fivetran provides are the pre-built data models that complement their connectors. Once you set up the connector, you can then install open source dbt packages provided by Fivetran that will create predefined models.
You can customize the packages.yml file to add configuration for the Fivetran models. I’ll use Greenhouse as an example.

To install the package, run dbt deps in your local terminal. Once installed, the packages will show up under a folder called dbt_packages. This folder is a default folder for any and all packages installed.

The underlying folders will be auto-installed with the code that builds the pre-made dbt models.
Before running the models, be sure to configure where you want these pre-made models to land in your warehouse and where the source data is located in your warehouse. These will both be configured in the dbt_project.yml file.
The destination of these new models must be configured right under the models tag.

To indicate where the source data is and how to read from the source data, set the variables as indicated in the Fivetran documentation to the relevant source system. Again, I’m using Greenhouse as an example and this is how the documents have indicated to do so. The Greenhouse system allows for custom columns so the source data structure can be different based on company. To account for this, Fivetran makes you define which columns are expected in your source system (an example of that here).
I’ve defined src_db , greenhouse_database and greenhouse_schema to indicate where to read the source data from in my data warehouse. I’ve also defined the variables greenhouse_application_custom_columns, greenhouse_candidate_custom_columns, greenhouse_job_custom_columns to indicate what columns to expect in these source tables.

Now, I’m ready to run the models using dbt build --select greenhouse_source and dbt build --select greenhouse.
Just like that, I’ve automatically cleaned up the raw data and applied some foundational transformations.
An added tip is to enable source freshness tests! This way, you can make sure your Fivetran ingested + transformed data is always fresh. You can read more on that set up here.
Automating the orchestration using Fivetran
One of the best parts of Fivetran’s dbt integration is the ability to manage and orchestrate desired models once the associated upstream data completes syncing. I have some models set up this way through the Fully integrated option, but there are other options to set up your own schedules. This is great as it allows the most up-to-date data models.

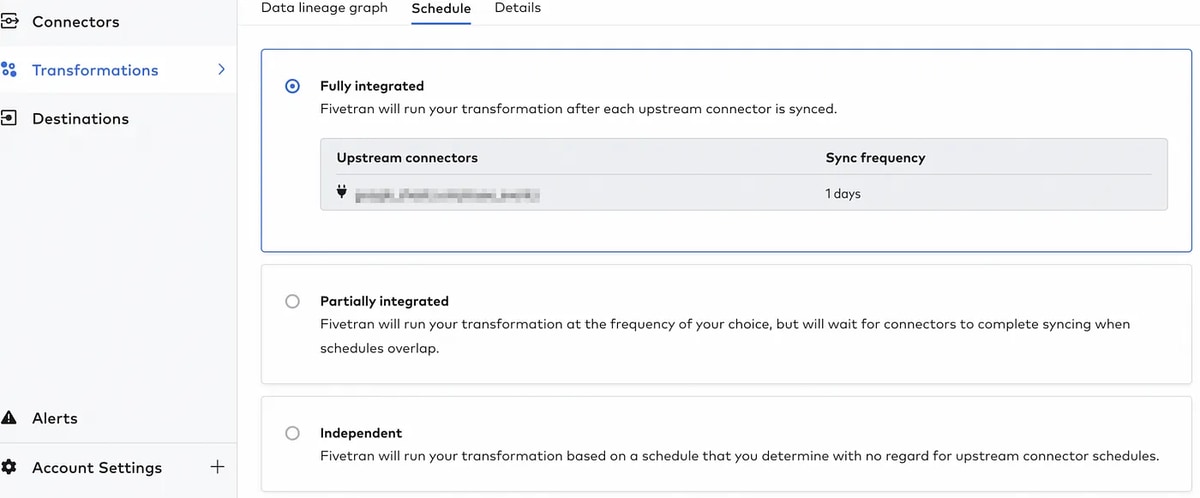
With this level of automation and integration, I’ve saved significant time on some of the basic, time-consuming parts of my job. I can leverage Fivetran’s data models and orchestration capabilities to automate the foundational data modeling work, allowing me to focus more on custom logic. I can also shift focus onto custom data sources that are unique to HubSpot.
Overall, these Transformations capabilities have been an efficiency gain. Our small team can deliver the required and requested people analytics to our aligned stakeholders. We are also excited to check out some of their recent releases like Quickstart data models and Lite connectors.
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







