

Traditionally data analysts have been given access to modeled data published to a data mart. This paradigm was working around the technology limitations of data warehouses of the era: limited compute and storage with hard limits on concurrent queries. As a result, data engineers modeled the data as partly denormalized star schemas or roll-up aggregations that were fractions of the raw data and computationally cheap to query.
Data modeling requires anticipating the downstream needs of the data. Data engineers don’t have a crystal ball, so changing requirements from the business leads to continuous and lengthy iterations with downstream users around the schema. Tightly coupling these business activities is incredibly inefficient, slowing down delivery of insights to the business.
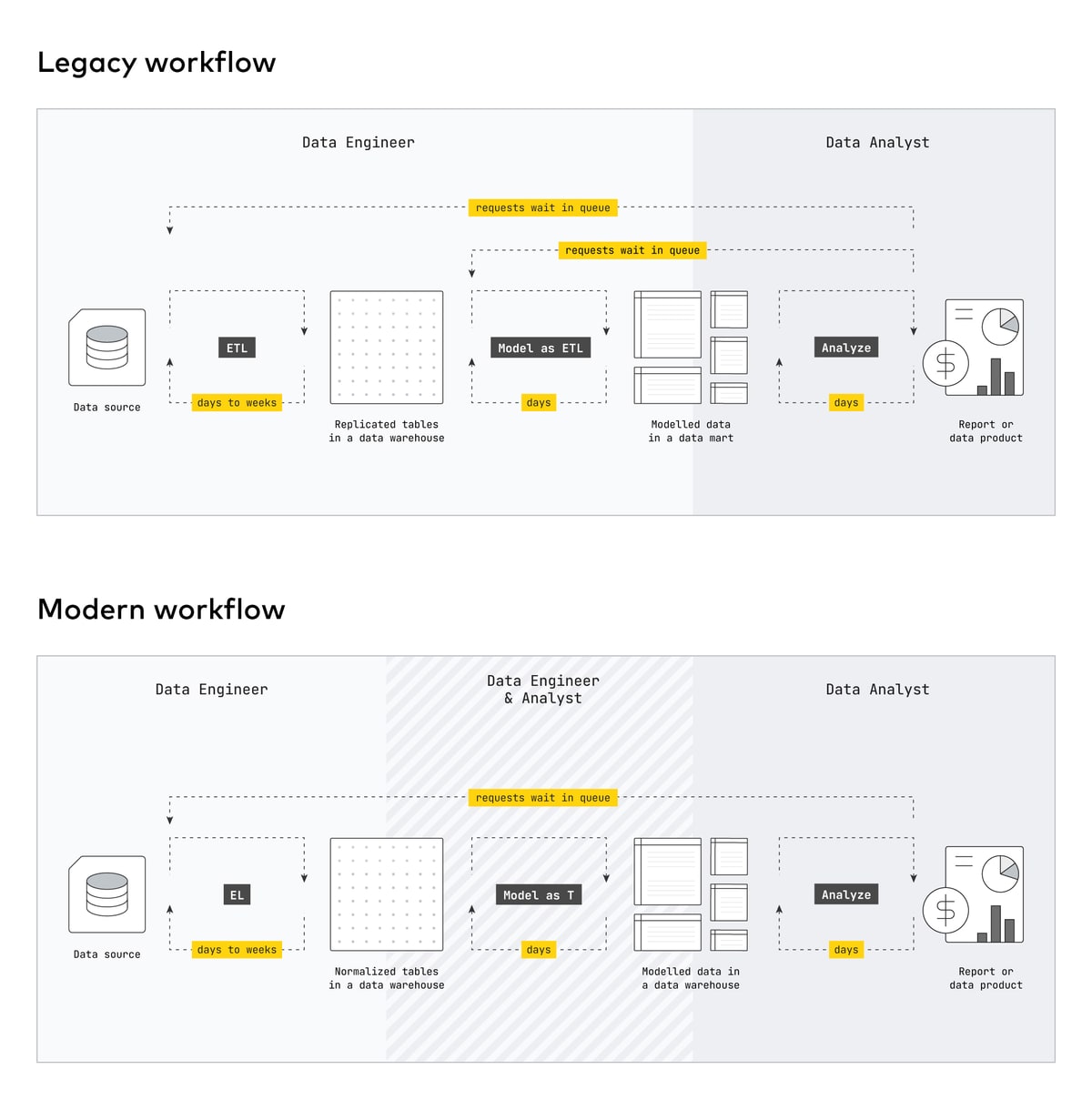
A better business process is to loosely couple the activities of data movement (extract-load) from transformation and analysis, where the interface between them is the landed schema in the destination. This is not a new idea — enterprise data architectures have incorporated this with operational data stores (ODS) or landing zones for enterprise data warehouses. What has changed is the separation of compute and storage in cloud data platform architectures. The compute and storage limitations of yesteryear are gone, which means the complexity of physically separating the data into different computation systems is replaced by logically separating the data by purpose. What are the ideal properties of that landed schema?
- Verifiably correct
- Flexible to changing downstream needs
- Intuitively understandable by data modelers
With a denormalized schema, it is quite difficult to universally prove the data is correct. This is the well-known computer science problem of algorithm correctness. With a normalized schema, you can compare individual records in the source and destination to demonstrate that they were replicated correctly. There still may be modeling errors in later transformations, but you’ve eliminated the entire set of data replication errors.
Denormalization is a continuum with corresponding degrees of flexibility to the downstream user. The most flexible end of that continuum is a fully normalized schema which as faithfully as possible matches the relational schema in the source system. Downstream data modeling can transform the landed schema into an analytical form like a star schema. The alternative of a denormalized landing schema with aggregations is implicitly anticipating downstream needs and limiting flexibility. This is good for modeled data but bad for unmodeled data.
A well-designed normalized schema provides nearly everything someone needs to know to work with the data. The tables represent business objects. The columns represent attributes of those objects. Well-named tables and columns are self-describing. The primary and foreign key constraints reveal the relationships between the business objects. The only part not represented in the normalized schema are the core business processes that cause changes to the data, which have to be communicated elsewhere. That is largely true of any landed schema.[1]

Fivetran delivers normalized schemas for these reasons. Our schemas are as close to third normal form (3NF) as possible, getting you closer to Bill Inmon’s data warehouse architecture out of the box.[2] For Software-as-a-Service API connectors, we’ve designed the schemas to represent the underlying relational data model in that source.[3] For databases, we make a faithful replica of the source schema. For file systems and events, we flatten the first level of fields into columns in a table.

The biggest benefit of adopting ELT is that you can automate extract-load into a normalized schema. The never-ending list of data integration projects and maintenance can be replaced by software. This frees up a significant amount of precious data engineering time to do higher-valued activities. This is the true value of Fivetran.
[1] The event sourcing pattern is better at self-describing the business processes. Each change is stored as an event in an append-only table. Snapshots of objects are (materialized) projections based on the sequence of events. This has the downside that an analysis nearly always starts with the current state of the objects. The complex projection transformations can be tricky to get right. For Fivetran, a practical problem is that most APIs do not expose change events. Instead of using the event sourcing pattern, we’ve made the decision to store the full history of important objects as Type 2 Slowly Changing Dimensions. This is straightforward for analysts to query while better self-describing the business objects.
[2] We make exceptions where a) normalized data is not available through any API (i.e. ad reporting APIs), b) a semi-structured object is dynamically heterogeneous or c) a deeply-structured object very tangential to core business processes.
[3] For API sources, this actually involves non-trivial transformation of the data from the API. It can be quite challenging to undo the API’s obfuscation of the underlying relational data model. Fivetran has built up considerable expertise and process around doing this correctly.
Normalization is one of many challenges involved in data engineering. Learn more about common challenges in this report.
DOWNLOAD







