5 critical features of modern data movement

Data movement refers to moving data from any source to any destination, across any type of deployment – cloud, on-premise or hybrid. Data movement supports all uses of data, including:
- Business intelligence and decision support
- Predictive modeling, machine learning and AI
- Real-time exposure of data, business process automation and data-driven products
As illustrated by the diagram below, data movement can be multidirectional. The sources can include applications, files, event streams and databases as well as data warehouses and data lakes. Data from sources is either aggregated or replicated in destinations including cloud data warehouses, databases and data lakes.
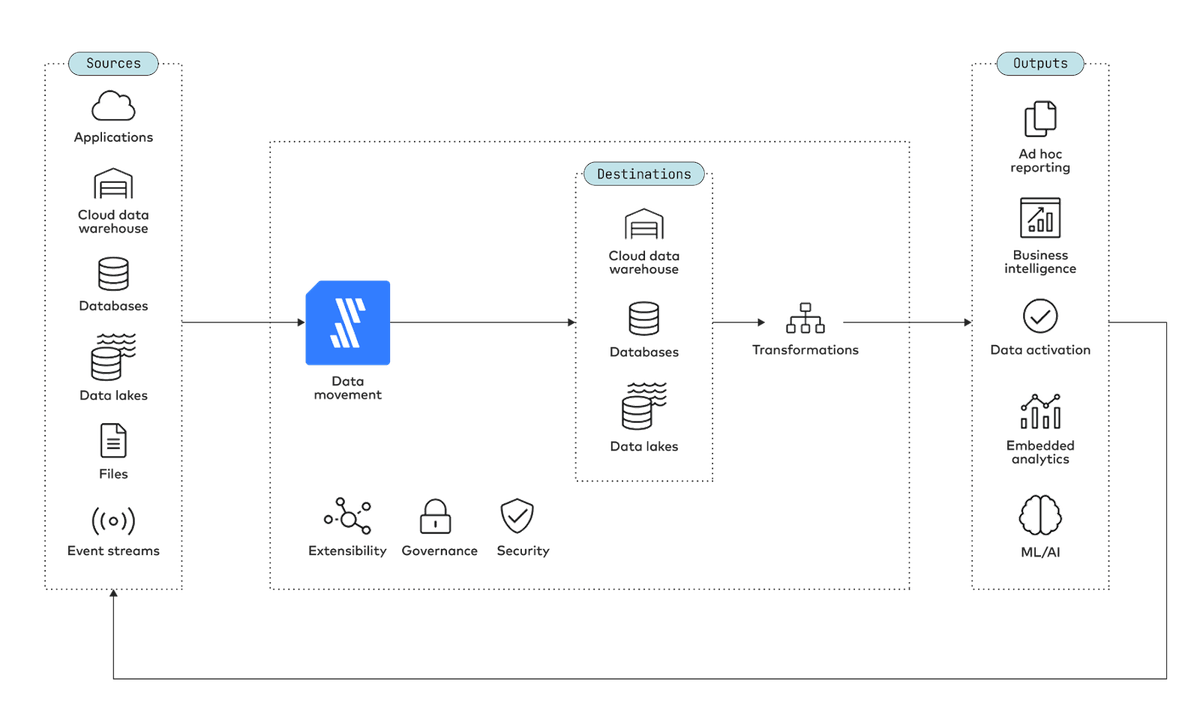
Most commonly, data pipelines move data from applications, databases and file systems into data warehouses in order to support analytics. You may also move data from one database to another, typically for reasons of redundancy or performance.
Moving data from source to destination requires a high-performance system that can be deceptively complex to engineer. Considerations include properly scoping and scaling an environment, ensuring availability, recovering from failures and rebuilding the system in response to changing data sources and business needs.
You must consider the following five features of any data movement solution in order to ensure performant, reliable data operations to enable operational and analytical uses of data.
- Automation
- Incremental updates
- Idempotence
- Schema drift handling
- Pipeline and network performance
1. Automation
At Fivetran, we believe that data movement should be fully managed and automated from the standpoint of the end user. Like a utility, access to data should involve a minimum of bespoke construction, human intervention and configuration. The ideal data movement workflow should consist of little more than:
- Selecting connectors for data sources from a menu
- Supplying credentials
- Specifying a schedule
- Pressing a button to begin execution
The importance of automation ultimately boils down to the scarcity of data talent and the growing complexity of an organization’s data needs as it continues to scale and adopt higher-value uses of data. Designing, building and maintaining a system that is performant, reliable, secure and scalable is a costly engineering effort in time, labor and money. It involves considerable complexity under the hood. The other items on our list will give you specific insight into the challenges involved.
2. Incremental updates

Although full syncs are important for initially capturing a full data set (or to fix corrupted records and other data integrity issues), they are the wrong approach for routine updates because they:
- Often take a long time, especially for large data sources. This makes full syncs incapable of supporting timely, real-time updates. This point is exemplified by the common practice of daily snapshots, where “daily” itself describes the slow rate of syncs.
- Can bog down both the data source and the destination, consuming resources otherwise required for operations and analytics, respectively.
- Consume excessive network bandwidth and compute expenses.
As data sources grow and add records, the problems listed above naturally grow, as well.
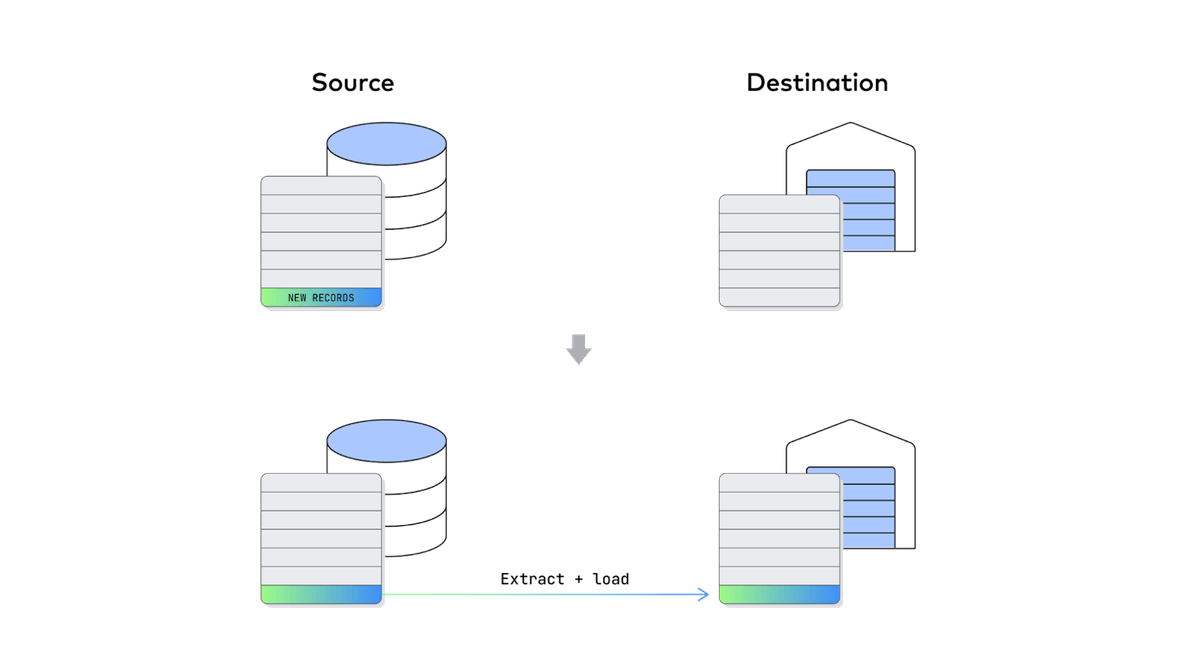
By contrast, a data pipeline that updates incrementally is able to only identify changes made to the original data set and reproduce them in the destination. This leads to shorter syncs and minimizes the impact on operational and analytical systems on either end of the data pipeline.
Incremental updates require the ability to identify changes made to a previous state of the source. This practice is often referred to as change data capture (CDC). There are several methods of change data capture, but two of the most prominent methods are the use of logs and last-modified timestamps. At small enough increments or batches, change data capture enables real-time or streaming updates.
Incremental updates necessarily involve splitting data syncs into small batches, leading us to our next topic, idempotence.
3. Idempotence
Idempotence means that if you execute an operation multiple times, the final result will not change after the initial execution.
One way to mathematically express idempotence is like so:
f(f(x)) = f(x)
An example of an idempotent function is the absolute value function abs().
abs(abs(x)) = abs(x)
abs(abs(-11)) = abs(-11) = 11
A common, everyday example of an idempotent machine is an elevator. Pushing the button for a particular floor will always send you to that floor no matter how many times you press it.

In the context of data movement, idempotence ensures that if you apply the same data to a destination multiple times, you will get the same result. This is a key feature of recovery from pipeline failures. Without idempotence, a failed sync means an engineer must sleuth out which records were and weren’t synced and design a custom recovery procedure based on the current state of the data.
With idempotence, the data pipeline can simply replay any data that might not have made it to the destination. If a record is already present, the replay has no effect; otherwise, the record is added.
4. Schema drift handling
Schemas drift when an application’s data model evolves and its columns, tables and data types change. Faithfully preserving the original values of data and ensuring its smooth passage from source to destination, even as the source schema changes, is a particularly vexing data movement challenge. Schema changes are one of the chief failure conditions for traditional ETL, often causing the data pipeline to fail and require an adjustment that requires scarce and highly specialized expertise.
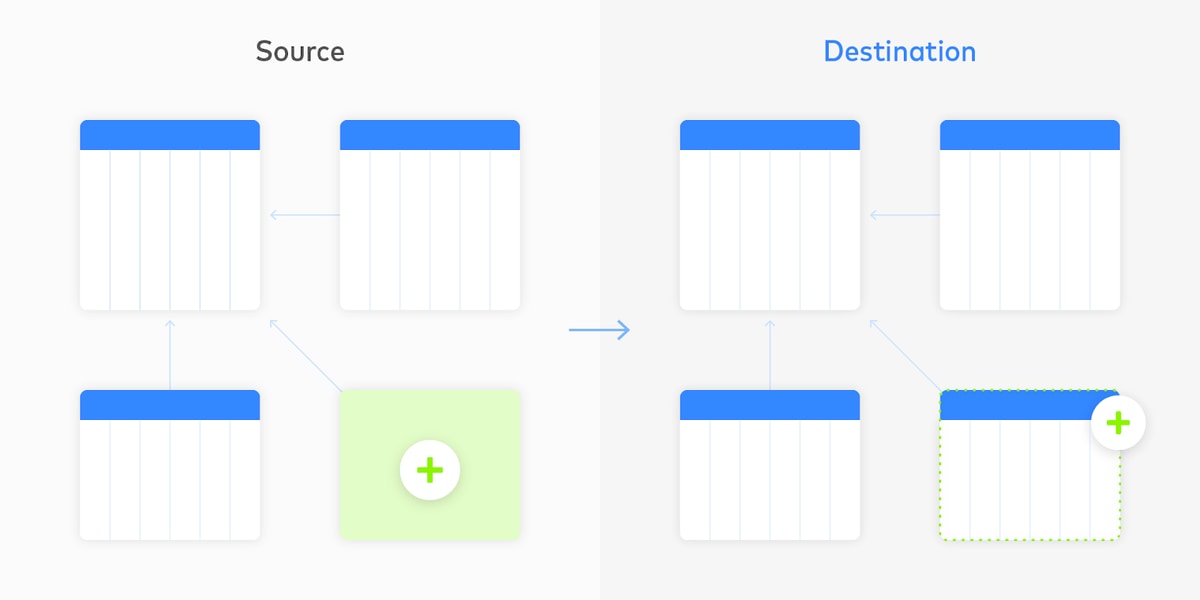
One practical approach to schema drift handling is live updating. The basic behavior is as follows:
- When a column or table is added to the source, it is added to the destination as well.
- When a column or table is renamed, it is renamed at the destination.
- When a column or table is removed, it is removed at the destination.
Live updating perfectly matches the data model in the destination with the data model in the source. This extends to individual records as well. Rows that are deleted at the source are deleted at the destination.
5. Pipeline and network performance
There are several basic methods to overcome bottlenecks in a data pipeline:
- Algorithmic improvements and code optimization don’t involve major changes to the software’s architecture.
- Architectural changes are used to parallelize simple, independent processes.
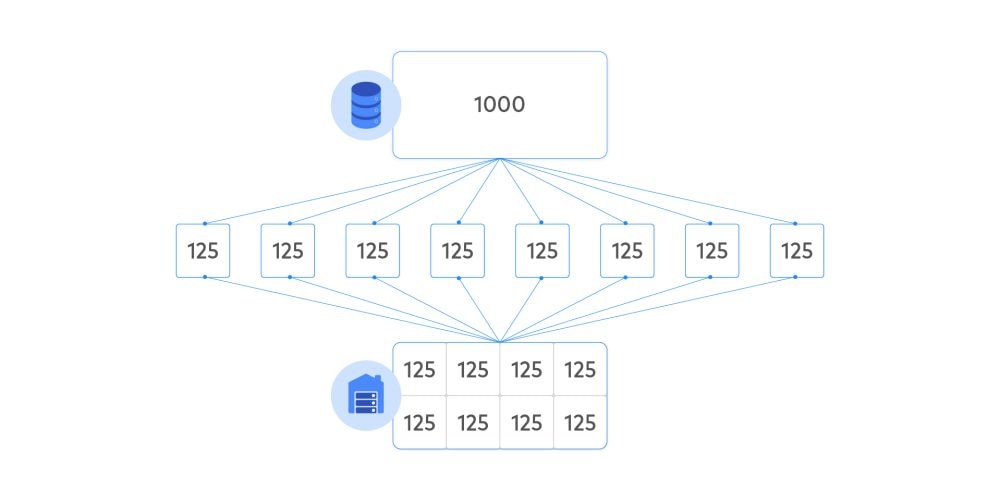
- Pipelining involves architectural changes to separate the data movement process into distinct, sequential stages that can each simultaneously handle a workload, like an assembly line.
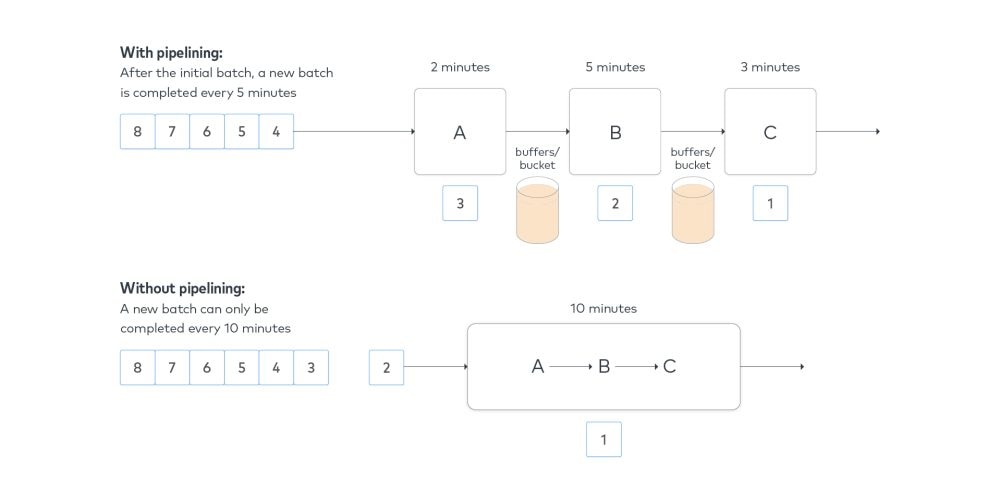
The full workflow of extracting, loading and transforming data can be a complex, path-dependent process. Architectural changes to software affect both how the code is organized and the hardware requirements of the system. This means parallelization and pipelining are potentially costly ways to improve performance and should be pursued only when algorithmic optimization has been exhausted.
Bonus consideration: Transformations
Under ELT architectures, data pipelines extract and load raw data to a destination. Raw data often isn’t especially usable to analysts and other users. Data transformation consists of all processes that alter raw data into structures called data models, collections of tables that directly support analytical and operational uses.
Ideally, a data movement solution should easily accommodate transformations in a destination. This includes:
- The ability to build data models in a collaborative, version-controlled manner (including CI/CD and other engineering best practices)
- A selection of off-the-shelf data models to solve common analytics needs
- Integrated scheduling, enabling the orchestration of sequential transformations based on triggers such as the completion of syncs
- The ability to observe data lineage in order to track the provenance of data models
The topics we have covered in this post – automation, incremental updates, idempotence, schema drift handling, pipeline and network performance and transformations are only the tip of the iceberg. You should also consider security, governance and extensibility. To learn more, check out our Ultimate guide to modern data movement.
[CTA_MODULE]
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







