Why enterprises are adopting Fivetran's Managed Data Lake Service



Data lakes offer incredible capabilities, especially for organizations managing large and complex data environments. However, they’re often underutilized due to common challenges:
- Data integration: Managing data ingestion from various sources is time-consuming and costly.
- Governance: Keeping track of data lineage, metadata and compliance is complex.
- Data integrity: Ensuring consistent and accurate data updates, especially across large-scale operations, is an ongoing struggle.
Fivetran addresses these challenges with a fully managed service that automates the data integration process, ensuring seamless scalability, governance and flexibility for even the largest enterprises. These core capabilities comprise Fivetran’s Managed Data Lake Service.
What is a managed data lake service?
A fully managed data lake service enhances the capabilities of a data lake with support for governance, automation and reliability. By exercising full control over data integration, including absorbing the cost of data ingestion, Fivetran’s Managed Data Lake Service combines the best characteristics of data lakes and data warehouses while virtually eliminating maintenance overhead, offering unparalleled convenience and peace of mind.
Fivetran data pipelines overall offer features and benefits such as support for over 600 unique data sources, real-time data access in with 1-minute sync intervals, reliability with 99.9% uptime and numerous security safeguards. The Fivetran Managed Data Lake Service builds on the capabilities of Fivetran pipelines with additional powerful features:
- Automated governance: Leverages open table formats and catalog integration to ensure ACID compliance and consistent governance across your data lake.
- Automated schema migration/evolution: Seamlessly adapts to changes in upstream data schemas, preventing pipeline breaks and accurately replicating changes in the data lake. Without this capability, you'd be limited to appending data.
- Query-ready data: Open table formats and catalog integration ensure that tables are easily discoverable, properly structured and fully ACID compliant, ready for immediate querying.
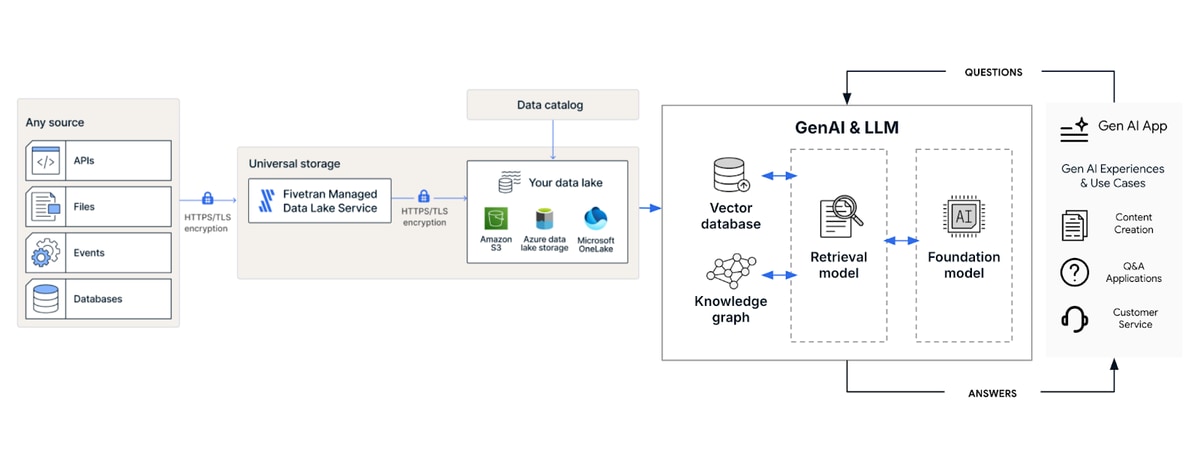
These capabilities empower data teams to focus on driving insights rather than managing data infrastructure. The architecture diagram below illustrates the role our Managed Data Lake Service plays for a generative AI use case; of course, it could power analytical and operational uses of any other kind as well.
Tinuiti, one of the largest independent performance marketing firms in the U.S., needed a managed data pipeline and repository to provide customers with data products at scale. According to Lakshmi Ramesh, VP of Data Services at Tinuiti:
“The data lake is an easy, affordable, secure and robust way to store all our customers' data. The main challenge is in optimizing performance and accessibility, but Fivetran’s support for Amazon S3 with Iceberg further optimizes our Fivetran pipeline. Since the data lake is our single source of truth, it is critical that all the data ingested from different sources be accessible in the data lake.”
Fivetran’s unique strengths
Many data integration solutions offer the data lake as a destination. However, compared with other data integration technologies and services, Fivetran offers the following differentiators:
- Ease of use: Every core capability Fivetran offers is predicated on ease of use and minimal engineering time. Other solutions may offer capabilities on paper but require considerable engineering effort, negating the advantages of involving a third party.
- Breadth of support for data lakes: Fivetran supports a wider range of destinations, open table formats and catalog integrations than almost every competitor.
- Support for open table formats: Few competitors natively support open table formats, specifically Iceberg and Delta, which are essential for maintaining critical data integrity and governance. These formats enable key features such as:
- ACID compliance
- History mode
- Schema migration
- Continuous table maintenance: Fivetran supports the following capabilities:
- Catalog integration: Integration with a data catalog ensures the catalog accurately records data pipeline metadata, meaning users can quickly discover, access and govern key datasets.
- File clean-up: As data volumes grow from continuous pipeline delivery, not all historical snapshots are needed. A well-architected pipeline should not only deliver data but also manage clean-up. Fivetran supports data retention policies and automatically removes orphaned files when they are no longer relevant, optimizing storage and ensuring efficient data management.
Overcoming misconceptions about data lakes
Some organizations hesitate to adopt data lakes due to misconceptions, often stemming from past experiences with outdated data lakes before open table formats and managed services became available. Common examples include:
“Our existing data warehouse architecture works fine.”
While your data warehouse may meet current needs, enterprises are increasingly future-proofing their data architectures to reduce vendor lock-in. A data lake, combined with an open table format, offers vendor-neutral storage and seamless integration with downstream services — providing the flexibility needed for emerging use cases.
Similarly, while data warehouses are effective for BI/analytics, many enterprises turn to data lakes for AI/ML use cases due to their flexibility, scale and cost efficiency. Data ingestion accounts for up to 30% of data warehouse expenses. Many enterprises adopt data lakes as a more cost-effective universal storage layer, using data warehouses and other services as query engines.
“Our existing data lake architecture works fine.”
While your current setup may work, it likely involves redundancies and high maintenance costs. Fivetran’s service eliminates these inefficiencies, allowing you to consolidate and simplify your data infrastructure.
“Open table formats don’t offer any real advantages.”
Using raw CSV or Parquet files limits governance and ACID compliance. Fivetran’s support for open formats like Delta Lake and Iceberg ensures your data remains reliable and secure and ensures you stay compliant with proper metadata management.
“A managed data lake is no different from other solutions.”
Fivetran offers extensive support for open formats, seamless integration with data catalogs and automatic data clean-up, which differentiates it from other services that write data to a lake.
[CTA_MODULE]
If your data architecture is at risk of vendor lock-in, experiencing rising costs, facing compliance risks or consuming excessive engineering hours just to maintain, it’s time to consider a managed data lake solution. With Fivetran, you can future-proof your data architecture to support your longterm business strategy, reduce total cost of ownership and create a seamless, scalable infrastructure that supports building data and AI products.
[CTA_MODULE]
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







