Transforming data: How an ELT platform can accelerate analytics

A key benefit of implementing an ELT platform is that it can make data transformation simple, powerful and seamless, within its own UI. Ideally, its transformation offering will follow evolving best practices in the analytics world, providing CI/CD features and prebuilt data models.
The approach should also be accessible. SQL has become the de facto coding language of data transformation, so a good ELT tool should be SQL-based, ensuring that all analysts across the organization can leverage it.
Here are the capabilities you should look for in terms of integrated data transformation, many provided by dbt™, the leading SQL-based transformation tool. The Fivetran transformation layer integrates tightly with dbt while providing additional features that make data transformation faster and more powerful.
[CTA_MODULE]
Fast, collaborative and transparent modeling
Version control
dbt Core* offers a full change history of your transformation models, making troubleshooting and validating data integrity far more efficient. You can easily revert transformation models back to previous versions if needed and compare changes over specific periods of time.
Branching and merging capabilities facilitate collaboration, allowing team members to work concurrently while keeping multiple work streams independent.
CI/CD is rapidly becoming a best practice; along with dbt, Fivetran is committed to following it so that our customers can scale their transformations effectively.
Prebuilt data models
Prebuilt data models reduce the need to manually code SQL, saving your data team weeks of time. You’ll be able to focus on deeper analysis and generate insights faster instead of doing foundational data modeling.
Fivetran has created an extensive library of open-source data models that can be readily applied to supported data sources. Built on top of common table schemas from our connectors, Fivetran data models automate much of the dbt development required to make your data analytics-ready.
Our ad reporting package, for example, rolls up ad spend, clicks and impressions across Apple Search Ads, Facebook Ads, Google Ads, LinkedIn Ad Analytics, Microsoft Advertising, Pinterest Ads, Snapchat Ads, TikTok Ads and Twitter Ads, offering a unified view of your ad efforts.
Modularity
With dbt, you can reproduce a transformation across multiple models and handle the dependencies between models. For example, if you have a “product” model that joins a product table to a category table, you can reuse this model across all relevant data sources — minimizing your need to build code from scratch.
Managing and scheduling transformations
Getting started with Fivetran Transformations for dbt Core* is as easy as connecting a Git repository with an existing dbt Core project in it. After Fivetran successfully connects with the repository, you have the option of choosing which models you want us to manage and how you want to schedule them. Fivetran will constantly sync with the Git provider, ensuring that all updates are reflected in your models. This reduces your maintenance time by ensuring your data is always modeled most accurately.
Importantly for teams looking to save time and keep data fresh, Fivetran offers what is known as “fully integrated” scheduling — by default, your new transformations are synchronized with their associated connectors. Because Fivetran manages the extract and load, we know exactly when to orchestrate your data model transformation, giving you full automation while reducing latency.
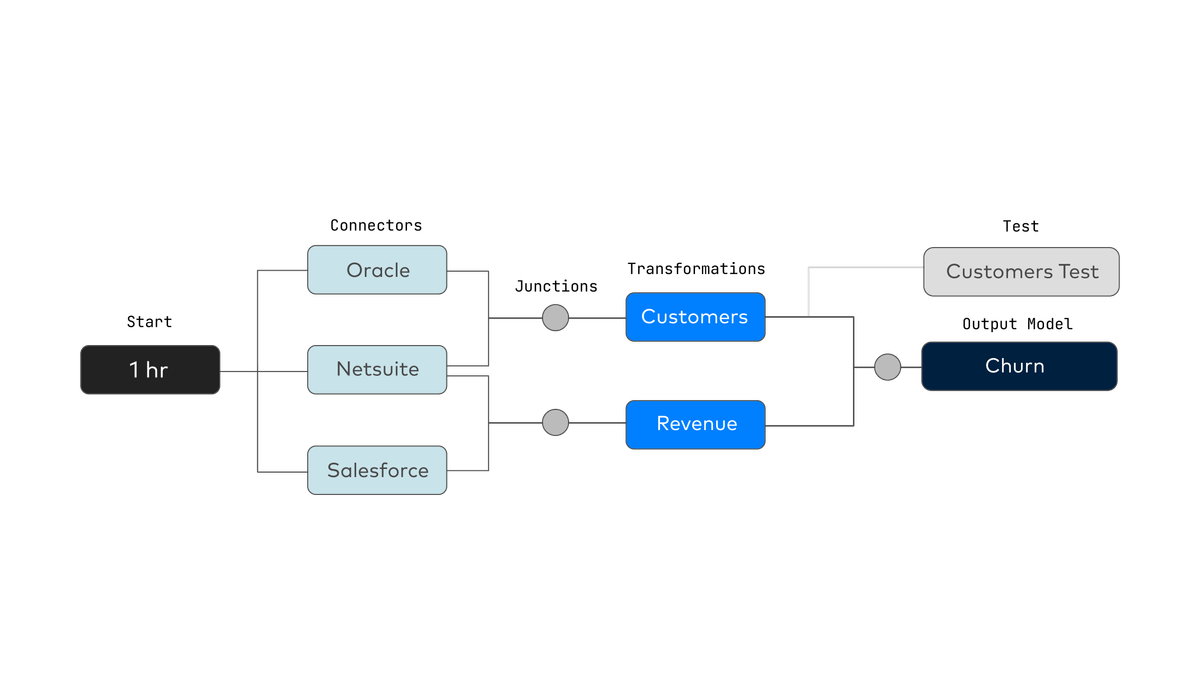
Prior to Fivetran, SpotOn, a leading software and payments company, transformed their data using manual stored procedures that grew to over 2,000 lines of code. By implementing dbt Core, they were able to modularize their modeling and orchestrate the process automatically.
“By integrating Fivetran and dbt, Fivetran becomes not only the ELT tool but also the orchestration tool, which is great for reliability, scalability and dev time,” says Tom Gilbertson, Project Manager for Data and Analytics at SpotOn. “Fivetran gives us a centralized, one-stop shop for our entire ELT pipeline — no third-party tools required. That made our processes more efficient and cut down on monitoring.”
Transformation best practices plus greater ease of use
To further streamline your ELT process, Fivetran offers Quickstart data models, which allow you to use our prebuilt data models without building your own dbt project — meaning you manage the entire ELT pipeline without leaving the Fivetran platform or writing any code. Quickstart data models are enabled by default for new eligible connections, along with a 14-day transformation trial. For existing connections, just set up your Quickstart data model and we’ll create the dbt project and transformation for you, while also providing our other transformation features. You’ll be able to view, manage and edit your entire pipeline right from your UI.
Learn more about creating a highly efficient data team and stack
Collectively, these best-practice capabilities allow your team to create scalable and powerful transformations much faster. If your team spends less time doing things like poring over API documentation, conducting root-cause analysis and manually coordinating data syncs and transformation runs, they’ll be much more effective supporting business decision-making.
To learn more about how to optimize your data stack and make your team more efficient, read our recent ebook, How to choose the most cost-effective data pipeline for your business.
[CTA_MODULE]
*dbt Core is a trademark of dbt Labs, Inc. All rights therein are reserved to dbt Labs, Inc. Fivetran Transformations is not a product or service of or endorsed by dbt Labs, Inc.
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







