
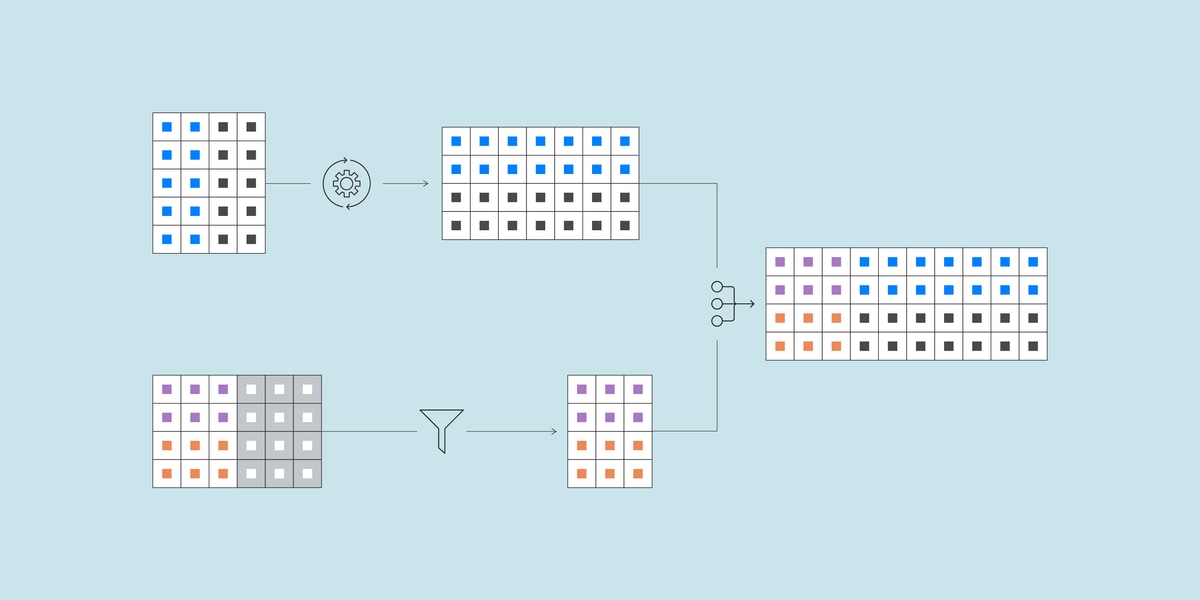
Fivetran Transformations offers a new vision for the “T” leg of ELT. The promise of ELT is to shift data integration from an engineering- and IT-centric activity to one that is well within reach of analysts. Fivetran Transformations is a further step in this direction, enabling data teams to make more progress with less engineering. We treat each data model, its update schedule and its full lineage, beginning with raw data from the source and ending in analyst-ready data models, as a single unit of analysis with its own SLA.
Fivetran Transformations has supported dbt Core since 2019. dbt Core arranges SQL-based transformations into modular, sequential scripts that are easy to maintain and debug, and applies data engineering best practices to building, testing and running SQL-based data models. On top of that, dbt Core supports an extensive community library of prebuilt data models, offering data teams the potential to save considerable data exploration and modeling time.
However, dbt Core is still fundamentally coding-intensive and usually requires orchestration through a workflow management tool like Airflow. This is a real boon for engineers who are comfortable building complex systems and running programs from a command line, but can be daunting for analysts, whose core competencies generally do not include writing and managing configuration files.
The most recent iteration of Fivetran Transformations offers an integrated, end-to-end user interface and experience that allows you to manage connector and transformation orchestration from a single platform with minimal configuration and code.
Use Fivetran to manage transformations in the UI
The key to making dbt Core analyst-friendly is to wrap an easy-to-use, UI-based orchestration layer around it that features integrated scheduling that automatically schedules and runs transformations in an automated, path-dependent manner as connectors finish syncs. This ensures data freshness and reduces latency. By running models in the correct sequence, users can prevent unnecessary syncs, saving compute costs. Integrated scheduling also promotes data integrity by preventing discrepancies between related tables.
Under the hood, this is what integrated scheduling looks like:
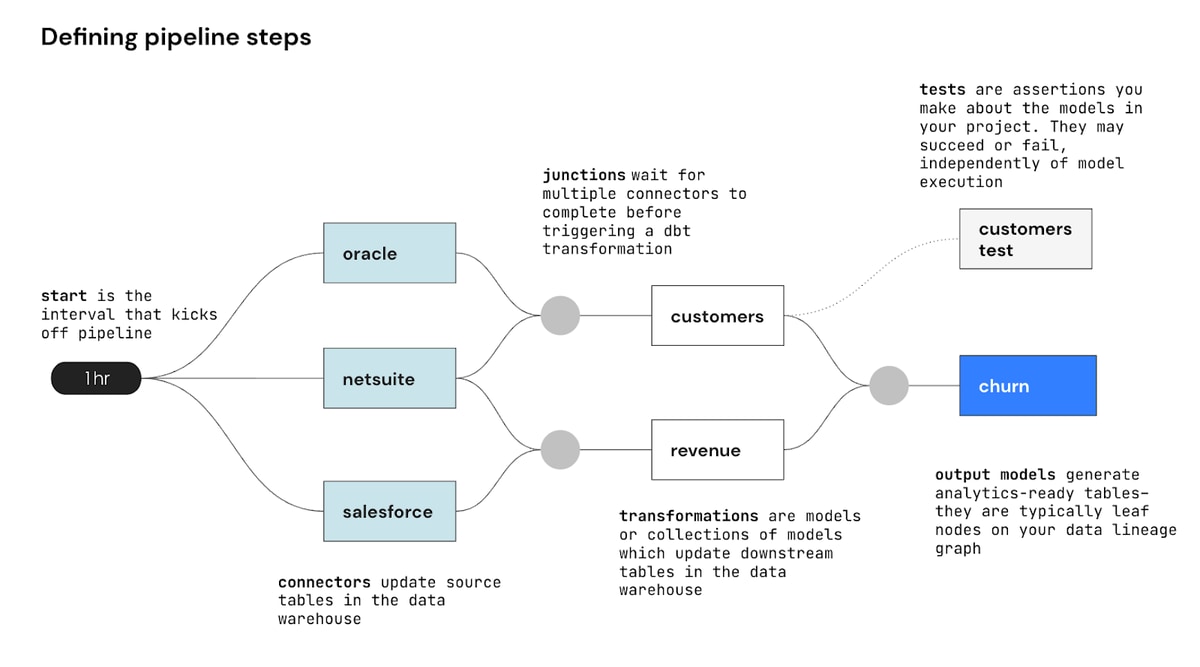
This pipeline waits for Oracle, NetSuite, and Salesforce connectors to complete their syncs before running downstream transformations in the warehouse. When Fivetran runs the “churn” transformation, it executes a dbt command that rebuilds not only the churn model, but also the customers and revenue models upstream of it.
Some models feed from multiple connectors and you may end up with overlapping connector schedules.
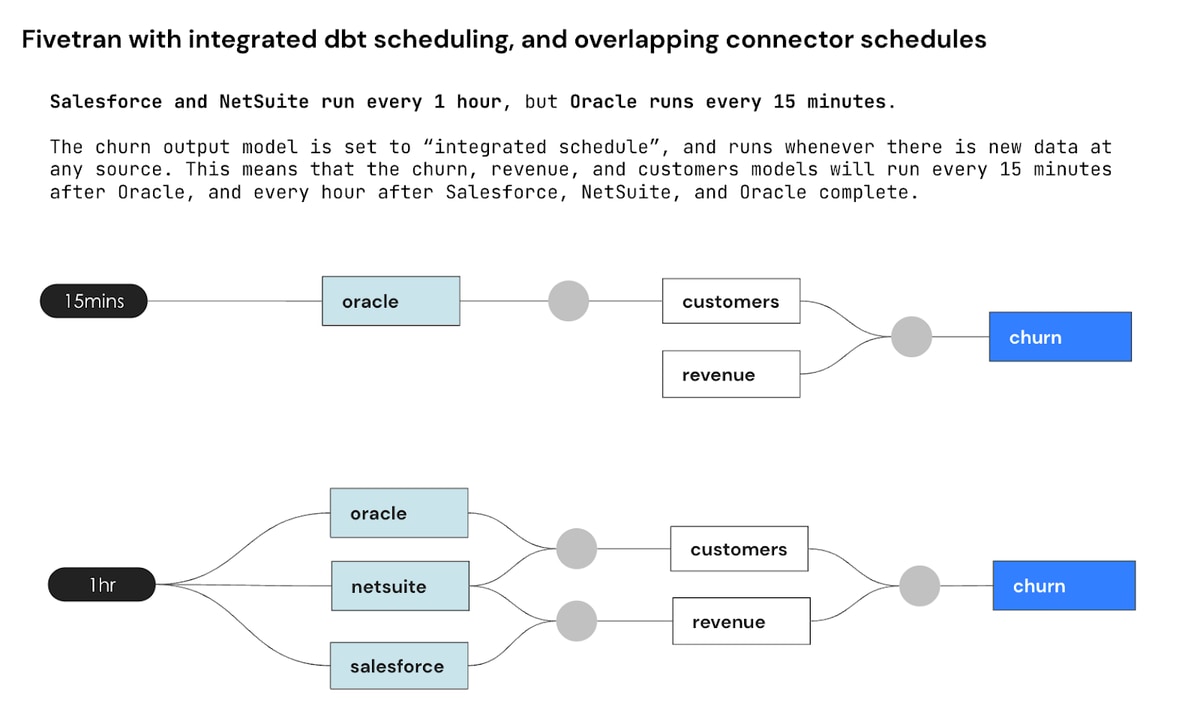
In this case, as soon as new data is available at any upstream source, the churn transformation runs.
Combined with the existing benefits of dbt Core, this graphical user interface (GUI) allows you to set up integrated and custom schedules for models you have already developed in SQL, completely obviating the need to handbuild any kind of orchestration and saving considerable engineering time.
How to set up Fivetran Transformations
The initial setup still requires some command line interface (CLI) manipulation and writing of configuration files. In order to get started with Fivetran Transformations, you will need:
- A local installation of dbt Core
- An integrated development environment (IDE)
- A version control system, such as GitHub, GitLab, BitBucket, etc.
- One of the following destinations: BigQuery, Snowflake, Redshift, Databricks, or PostgreSQL
Then, you will have to:
- Create a Git repository for your new dbt project. Your dbt project is a container for your data models.
- Create a dbt project in that repository from the command line.
- Specify the credentials for your data warehouse in the “profiles.yml” file.
- Commit and push the Git repository for your dbt project to link them together.
- From the Fivetran GUI, go to Transformations and start the guided setup.
- Use the SSH key from your Git repository to link your Fivetran account with your version control
- Before you can add transformations through the Fivetran GUI, you will need to populate your dbt project with data models. You can use off-the-shelf models from Fivetran or create your own custom models.
Now, you’ll be able to use the GUI to coordinate all your orchestration and scheduling. For more detailed instructions, see our setup guide.
Adding Fivetran Transformations from the GUI
This GUI is shared with our connectors, meaning you don’t have to change environments to orchestrate transformations. From our connector GUI, it’s an easy matter to find Transformations on the left sidebar.

In the Transformations interface, the default “Managed in Fivetran” tab displays output models and details about their statuses. You can add a new transformation with the button in the upper right. Note that the “Managed in Code” tab allows you to check the statuses of custom orchestrations.
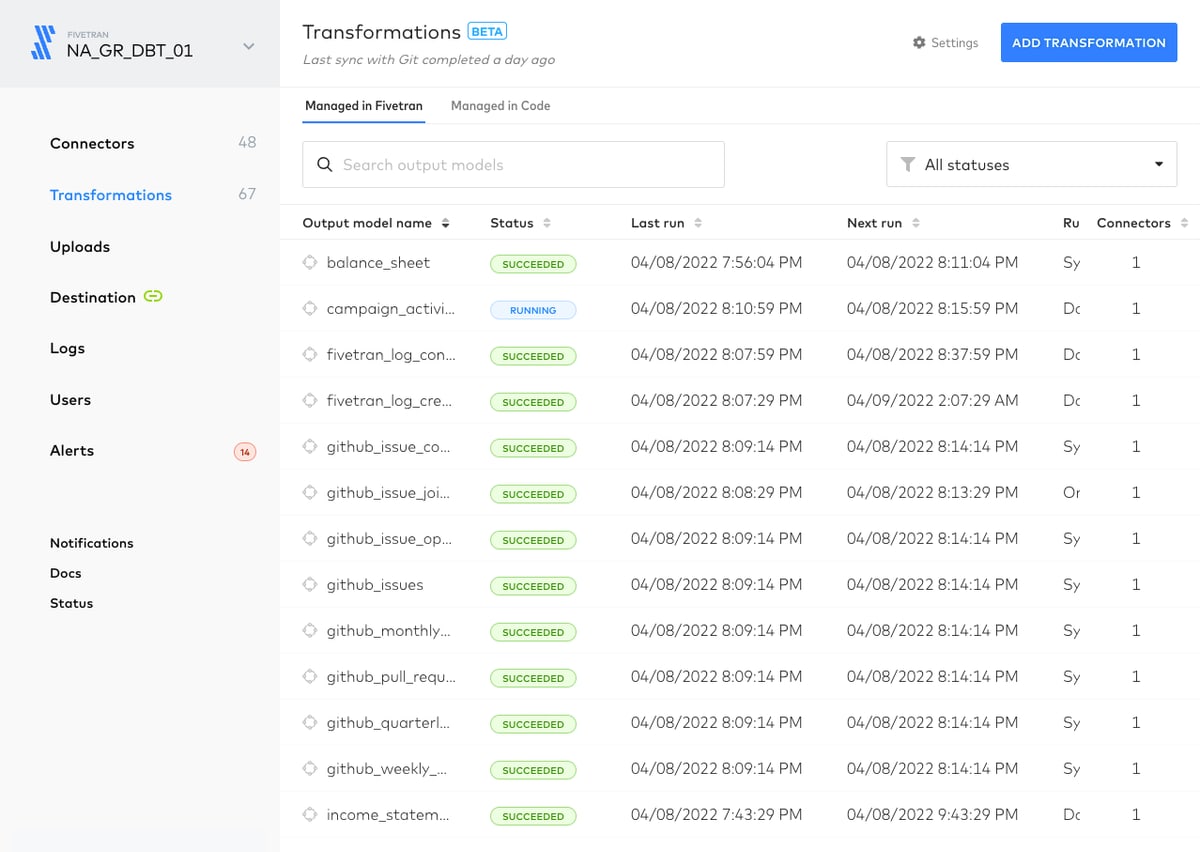
Once you click “Add Transformation,” you can select a model from a dropdown list which lists the models you have built in dbt.
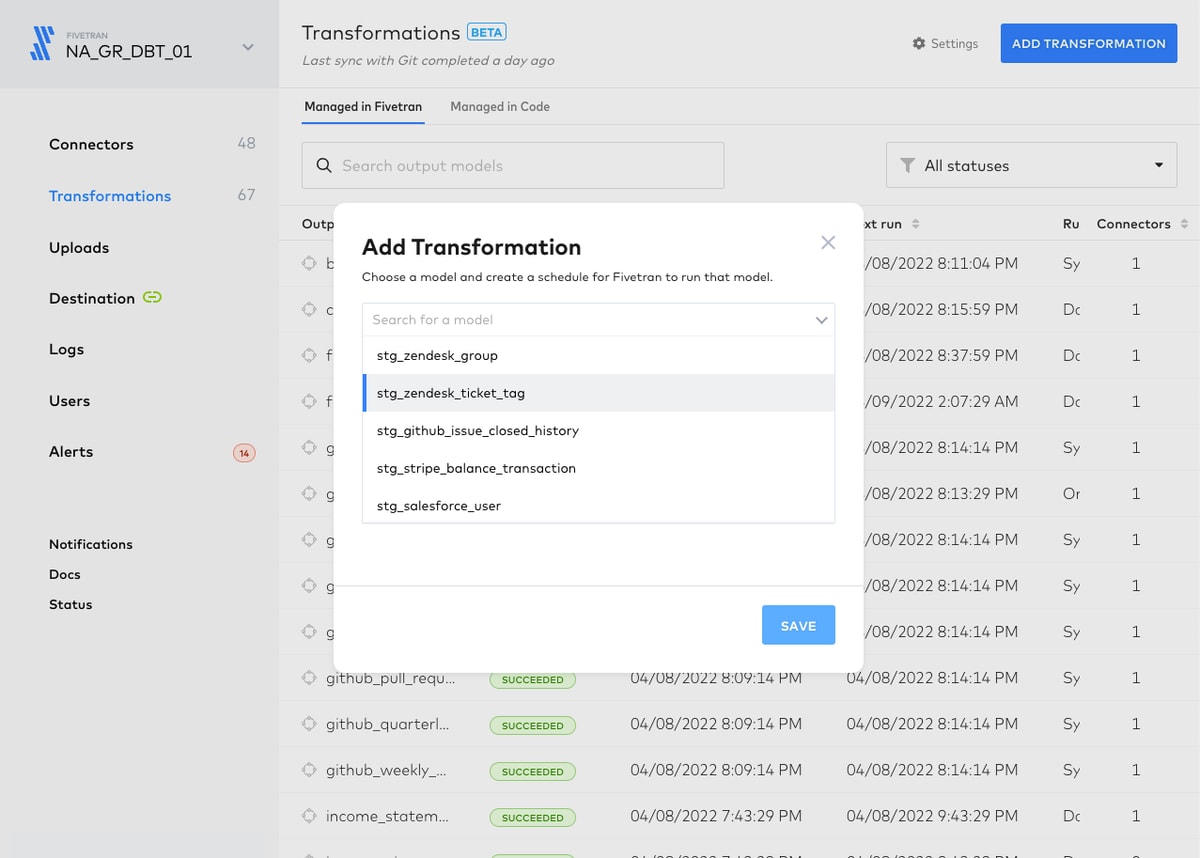
And then choose the default “integrated schedule,” which triggers transformations only when the upstream syncs are completed, or on a custom, time-based schedule.
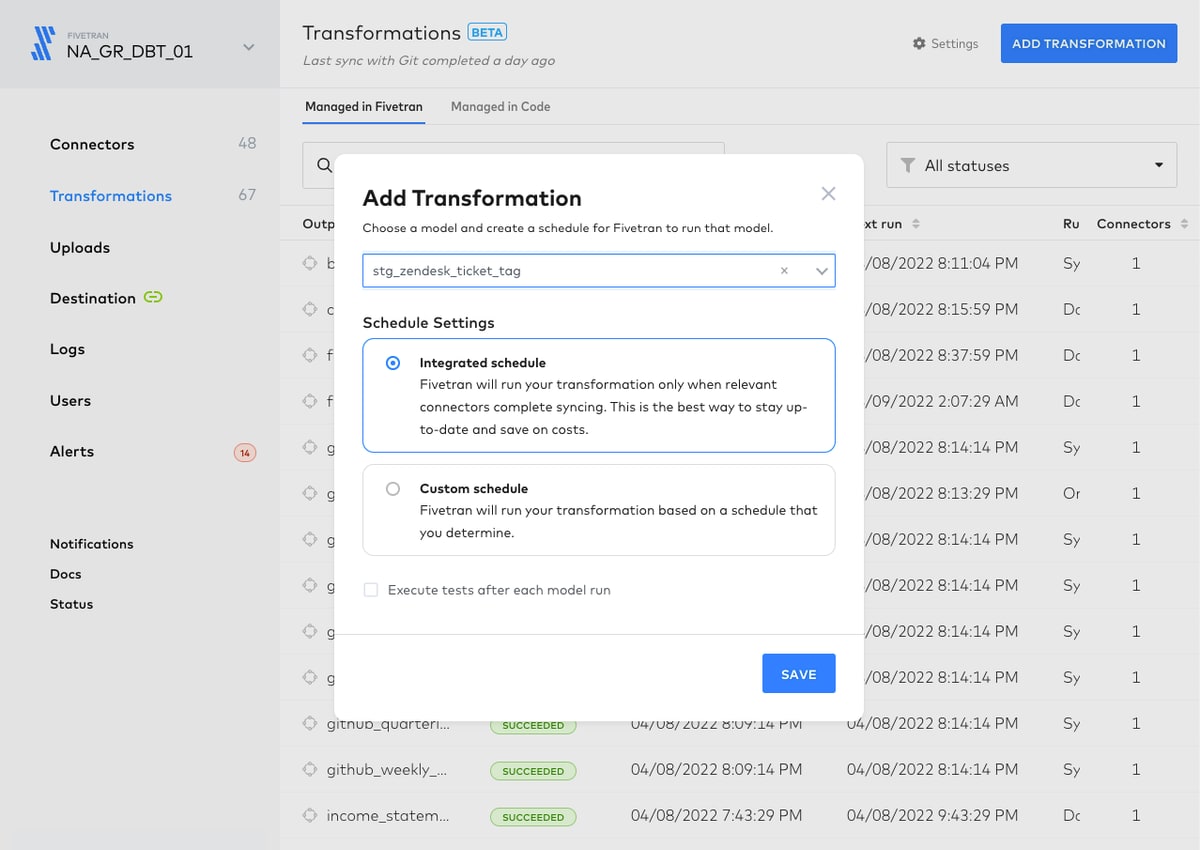
The simplicity of this interface makes the full workflow far easier for your analysts to interpret, maintain and debug.
For more details, see our Transformations setup guide and explore our library of data models to add Fivetran to your dbt project today.







