How do people use Snowflake and Redshift?


The average Snowflake customer spends about $300,000 per year on the platform. 90% of this is queries. What do these queries look like? We might imagine the typical user of Snowflake to be an analyst, with all their company's data at their fingertips, answering questions about what is really happening in the business. Is this what a typical workload looks like? It turns out that Snowflake and Redshift have both published representative samples of what real user queries look like on their systems, and they are filled with insights about how data warehouses are used in the real world.
Data warehouses are ETL Tools
Snowflake and Redshift didn't publish the exact queries run by their users, but they disclosed enough information for us to understand the overall breakdown of query types:
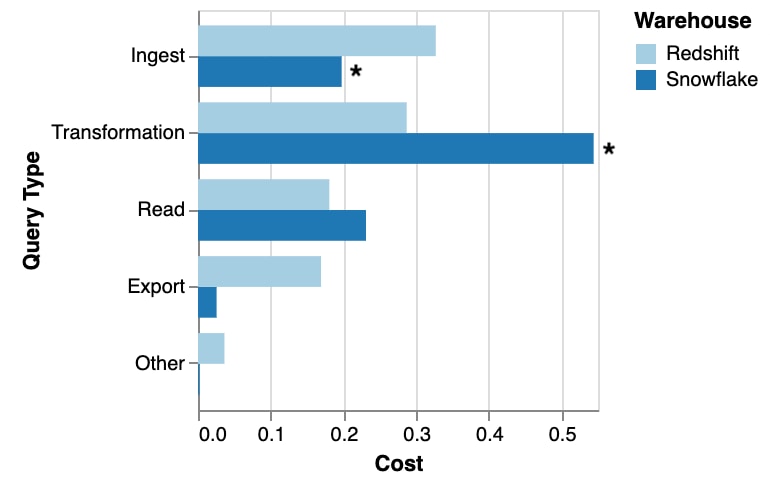
* Some Snowflake ingest cost is marked as transformation due to limited information in the sample published by Snowflake.
You can think of these broad categories as representing stages of data processing:
- Ingest brings new data into the system and merges it with existing data.
- Transformation turns the "raw" data into simplified, easy-to-query views.
- Read is primarily business intelligence dashboards and data science.
- Export sends data out of the data warehouse to other systems.
- Other is primarily system maintenance functions.
The vast majority of the workload is ingestion and transformation! Data warehouses are primarily used as ETL tools.
Most queries are small
When we think about data warehouses, we often think about massive datasets. Vendors emphasize their ability to scale, and publish performance benchmarks with 100 TB datasets. How big are the datasets users actually query?

Of queries that scan at least 1 MB, the median query scans about 100 MB. The 99.9th percentile query scans about 300 GB. Analytic databases like Snowflake and Redshift are "massively parallel processing" systems, but 99.9% of real world queries could run on a single large node. I did the analysis for this post using DuckDB, and it can scan the entire 11 GB Snowflake query sample on my Mac Studio in a few seconds. The small data hypothesis is true.
Do we need massively parallel processing?
Massively parallel processing (MPP) is unquestionably elegant. An MPP system like Snowflake or Redshift can execute a SQL query across multiple computers, distributing and redistributing the data as the query progresses so that the work is evenly divided. For example, suppose you want to know what are the most popular Python packages. This can be expressed as a SQL query:
BigQuery can run this query for you, distributing the data across nodes as necessary, without you having to know or care about how any of this works. But suppose you want to do something that can't be expressed as a SQL query, for example if you want to fit a logistic regression model using scikit-learn:
You will have to run models like this on a large single node outside the elegant MPP world:
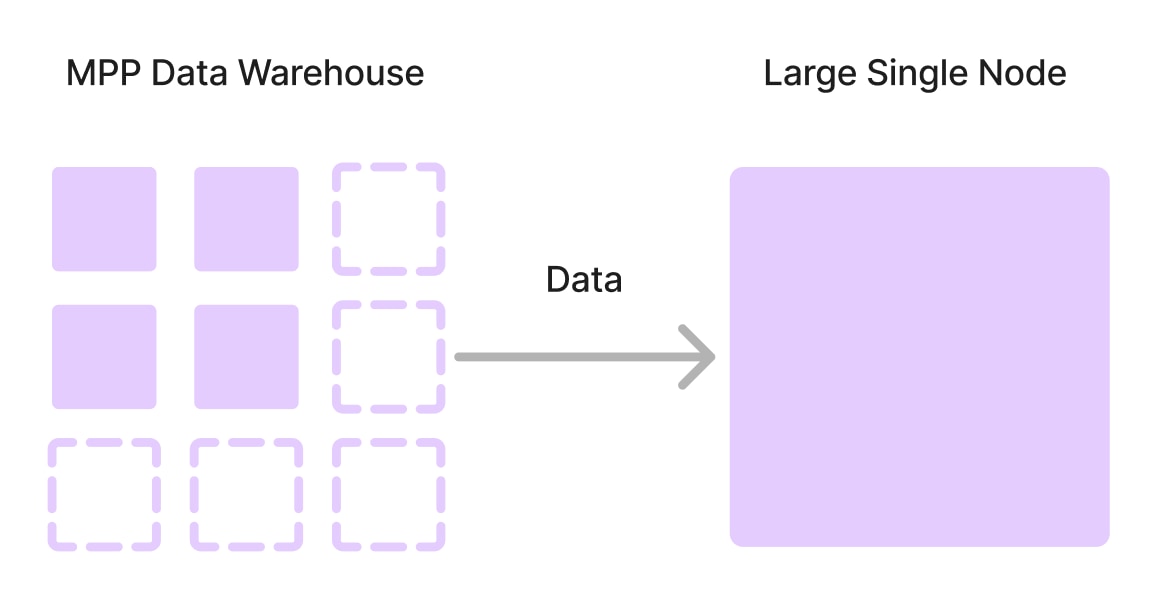
This solution works, but the simplicity of the MPP system is lost, and you pay a meaningful cost to simply export the data out of your data warehouse.
Data lakes will change everything
Data Lakes explicitly separate the storage layer of the data warehouse into a separate, vendor-neutral format in object storage. Multiple, specialized execution engines can interact with the same data lake, mediated by a catalog that provides transactions and fine-grained permissions.

This paradigm will enable customers to use specialized execution engines for specific workloads, instead of having to fit everything into the constraints of MPP. This is already happening:
- The Fivetran data lake writer is a specialized ingest service.
- Microsoft Power BI includes a specialized BI engine.
When you build a specialized engine for a specific workload, you can be more efficient, because you can rely on special characteristics of your workload. For example, when Fivetran built our data lake writer service, we were able to make it so efficient that we can simply absorb the ingest cost as part of our existing pricing model. Ingest is free for Fivetran data lake users.
Additionally, local compute is going to be an important participant in data-lake implementations, because small queries represent such a large portion of real world workloads. If your query scans less than 100 MB, it probably makes more sense to simply download the data and execute the query locally.
More work needs to be done by vendors and the open-source community to make all the participants of this system interoperate seamlessly. In particular, every system needs to read and write the customer's catalog, so that all these engines share a single logical database. But the benefits to the customer will be huge: the systems of the future will be more efficient, provide a better user experience, and make it easy to run all kinds of workloads, including new machine learning and AI workloads that haven't been invented yet. Companies like Fivetran and Snowflake are working hard to make data lakes as easy to set up and operate as traditional data warehouses.
If you want to live this future today, the Fivetran data lake service is the fastest way to start.
The code for this analysis is available at github.com/fivetran/snowflake_redshift_usage
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







