
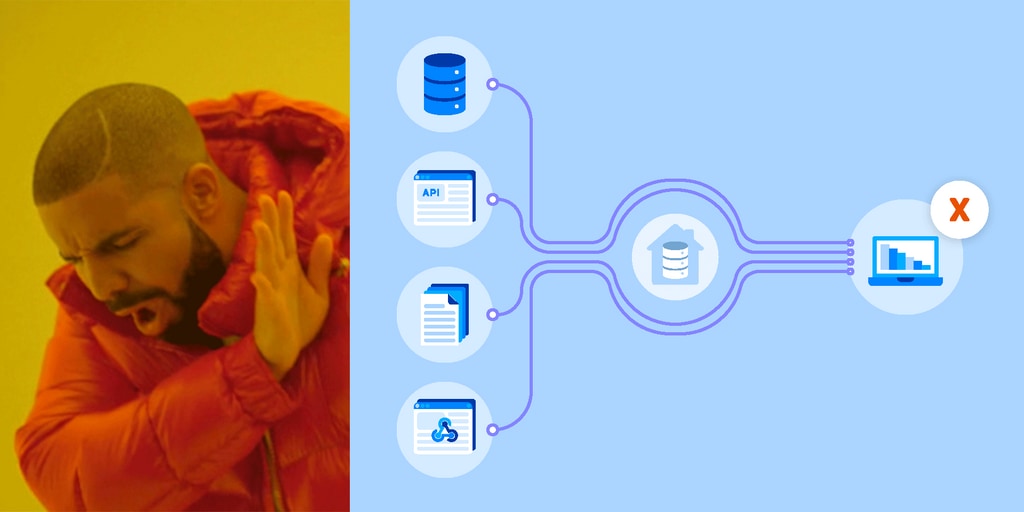
We live in a golden age of business intelligence. Analysts today can choose from a range of classic products such as Microstrategy and Qlik, mainstays like Tableau, and newer offerings like Domo, Looker and Mode. Many of these products feature tools to read data directly from files and data feeds (Looker, one of our partners, emphatically does not). These tools are often described as “connectors” and at Fivetran, we make a lot of them. Our connectors, however, connect from data sources to data warehouses, while connectors featured by BI tools connect data sources directly to the visualization and analytics layer.
Connecting data directly from the source to a BI tool is useful in a pinch. It’s certainly a sensible way to conduct a one-time, low-stakes exploration without having to fumble around with a relational database or data warehouse. It is not, however, a sustainable way to build dashboards and pursue data-driven decision-making.
There are several serious drawbacks to this approach:
- Raw data can often be out-of-date, denormalized, or poorly structured
- There is no built-in capacity for consistency, version control, and collaboration
- All-in-one solutions are often black boxes
Denormalized and Demoralized
Raw data “pulled” or “exported” from a data feed is most commonly presented in document-based formats such as JSON and XML. These formats consist of key-value pairs, frequently with multiple layers of nesting and one-to-many relations in each record. The data is at best loosely structured and never normalized.
Platforms like Tableau accommodate these structures and do a remarkable job of inferring the schema, but still leave quite a lot of interpretation up to the user. More tabular file types like CSVs don’t pose this problem but still lack normalization.
If you attempt to use this data, not only will you have to reconstruct the schema yourself, but you may end up storing large amounts of duplicative data as well. Moreover, it’s dangerously easy to accidentally (or maliciously) compromise, corrupt or delete data stored on files, whether they are stored locally or in something like an S3 bucket. Finally, episodically downloading or exporting data not only poses a work burden but ensures that your data will never quite be in real-time.
You can, of course, avert this problem by querying the data feed directly, but that will consume your allotment of calls to that particular API. Moreover, some APIs are simply incomprehensible. Fivetran spent three years making sense of the NetSuite API, even with the help of documentation and a wide range of users.
A House Divided
One of the main benefits of data warehousing is that it brings transparency to your business operations, with common access permissions, versions and formats. The alternative is that different teams within your organization will be working with conflicting versions of the data, or incompatible data types. Further, data may be inaccessible to some members of your organization. Without a data warehouse, there is no such thing as a “shared source of truth.”
Any data professional can tell you that wrangling with inconsistent representations of dates and times is one of the most loathsome data chores. This is further compounded by the differences in date and time notation between North America and the rest of the world.
Another consideration is that your data source is unlikely to maintain a history of certain data. Often, if the status of an entity changes, the corresponding value will simply be overwritten. The way to remedy this is to continuously integrate your data into a place with a process for tracking these changes.
Imagine trying to reconcile records from a turbulent time in your organization’s history, when different business units used different software, different versions of the same software, and different date and time formats!
Blacked Out
Business intelligence platforms that offer integrated connectors often suffer from yet another serious problem. Sometimes they are completely opaque, with limited templating options and little built-in access or visibility into the underlying schema, data, and transformations.
One of our customers experimented with an all-in-one solution that combined business intelligence and integrated connectors and was stymied by its inability to observe – and fully understand – what was happening under the hood. The business was locked into existing templates without the ability to produce the specific analyses it wanted.
Cut Through the Knot
Business intelligence tools are designed to deal with the front end of data science: visualization, analysis, and some light modeling. They are emphatically not data engineering tools and you should not count on them to meet your data pipeline needs. You should treat tools with built-in connectors much like you would treat the foldable scissors on your multi-tool: something that will work when nothing else will, but not the first resort.
For any organization whose spreadsheets have begun to get unmanageable, there is no question that a data warehouse is necessary. Trying to circumvent the need to build a data pipeline by connecting data directly to a BI tool will only lead to needless complications in the longer term.
Fivetran offers a comprehensive solution to the problem of building data pipelines. We partner with, and support, a wide range of data warehouses. Unlike companies that build BI tools, data connectors are our specialty. We don’t have the conflicting mandates of building both data pipelines and visualization and statistical tools.
If your organization is ready to start using a data warehouse, then give us a try here!







