

Active metadata: Open the black box of your data pipelines


The era of big data and the shift to the cloud have pushed data teams to get innovative in the construction of their data and analytics ecosystems. And let’s be honest, this is out of necessity as organizations push to be more data-driven. Businesses can’t wait days on a data request to support a decision they need to make now. Data pipelines are supporting more operational, real-time / near real-time and event-driven analytics than ever before, in addition to the core weekly/monthly/quarterly reporting that executives demand.
With the increase in complexity and pressure on data teams to create and maintain these pipelines, having clear insight into what is happening across your data estate is crucial. Did something break? Are all jobs successful? What assets does the pipeline impact downstream? Has the quality of the data changed? Who is utilizing the data products our pipelines are feeding?
All of this can be answered using active metadata!
What is active metadata?
Just like data mesh or the metrics layer, active metadata is another hot topic in the data world. As with every other new concept that gains popularity in the data stack, there’s a sudden explosion of vendors rebranding to “active metadata”, ads following you everywhere and … confusion.
With everyone talking about active metadata, it must be pretty easy to understand, right?
Well … sort of. Let’s break it down a bit further. (Check out this blog for all the details.)
As we embraced the internet and data exploded, companies realized they needed to manage all this new data. For a couple decades, companies spent millions on their metadata and billion-dollar data cataloging tools emerged. Yet just last year, Gartner declared that “Traditional metadata practices are insufficient…” That’s because this age was driven by passive data catalogs, which aggregate metadata from different parts of the data stack and let it stagnate. They solved the “too many tools” problem by adding … another tool.
Metadata is like any form of critical information. If it sits passively in its own little world, with no one seeing or sharing it, does it even matter? But if it actively moves to the places where people already are, it becomes part of and adds context to a larger conversation.
Active metadata sends metadata back into every tool in the data stack, giving data teams context wherever and whenever they need it — inside the BI tool as they wonder what a metric actually means, inside Slack when someone sends the link to a data asset, inside the query editor as try to find the right column and inside Jira as they create tickets for data engineers or analysts. This makes it possible for metadata to flow effortlessly and quickly across the entire data stack, embedding enriched context and information wherever data professionals spend their time.
Four ways that active metadata can shine a light into your data pipelines
Let’s deep dive into a few examples of where metadata can be activated to open up what can be a black box.
Discoverability: The most basic way to use metadata is collecting and displaying it. Metadata like descriptions, ownership, certifications, data classifications and more help users find the data they need, know if they can trust it and know who to reach out to if something looks off.
However, to truly activate this metadata, it needs to be delivered to the consumer in a workflow they are familiar with. For example, Atlan activates metadata via a Chrome extension that allows users to see all the metadata context they need right in their BI tool. By not breaking a user's daily workflow, this metadata activation is a game changer when it comes to adoption.

Root Cause Analysis: Inevitably, some part of a data pipeline will break. Things happen — changes to data upstream, new schemas or changes to business logic. Diagnosing where and what happened requires active metadata.
Atlan integrates into your existing pipelines or CI/CD processes, using the operational metadata to detect when something goes wrong and trigger announcements to users. At a more fundamental level, information such as last run date, success/failure indicators and pipeline owners is visible for expedited root cause analysis.
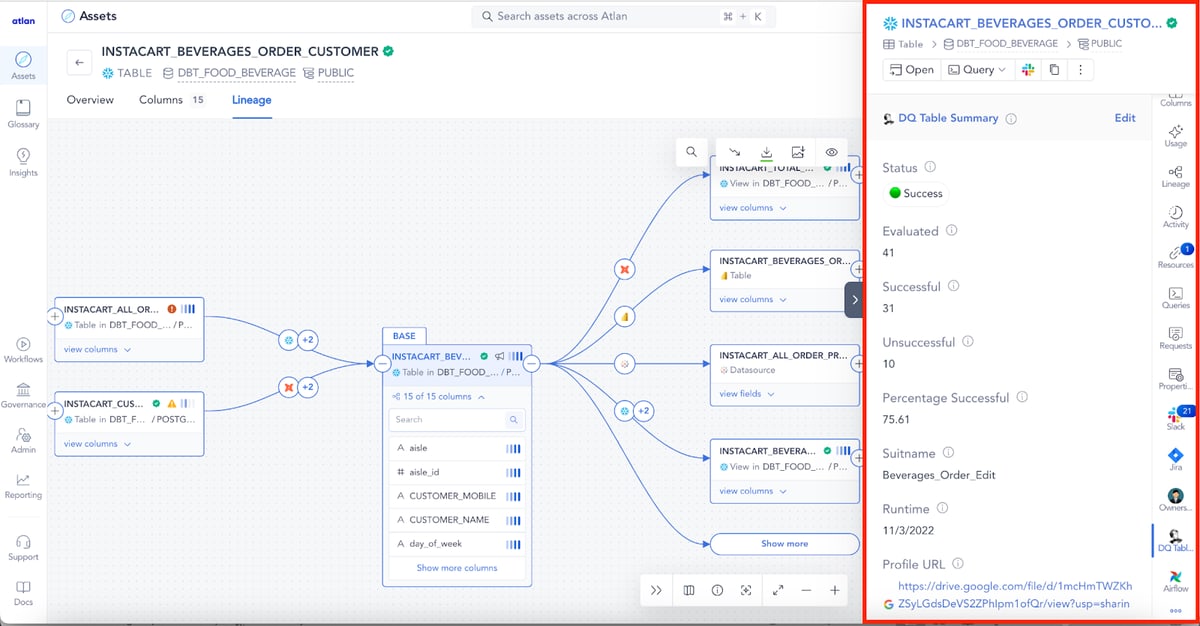
Impact Analysis: After root cause analysis, you often need to change a data pipeline. The last thing any engineer wants is the frantic Slack message from an analyst or business user saying their dashboard has disappeared hours after you just pushed something to production. By activating metadata, Atlan can generate column-level lineage spanning your entire data pipeline.
I hear you saying, “Sounds like I’d have to manually look through a lineage DAG to see the impact of my changes.” Oh no, no. I said active, remember? We’ll bring the information from the lineage graph directly into your Git process, so any pull request automatically generates an impact report of any assets that would be affected if you push your changes. No manual browsing required!

Cost Optimization: If you don’t have money on your mind, you should. I think it’s safe to say with all the economic uncertainty 2023 brings, we are all a bit more cost conscious than we already were. Activating metadata can help here too.
Cloud compute and storage costs are one of, if not the most, expensive pieces of your data stack. Using metadata to identify data assets with no lineage allows organizations to clean up unused or orphaned tables. Atlan activates metadata from the queries run against your data warehouse to identify inefficient, long-running, and expensive queries. With this information, you can make small changes to query structure or intelligently allocate compute resources to save some serious dollars.
Opening new possibilities with Atlan and Fivetran together
With the combined power of Fivetran and Atlan, joint customers can move faster with more visibility across their entire data stack.
After less than 60 seconds of setup, Atlan’s integration leverages Fivetran’s Metadata API to create automated visibility of your data stack. With end-to-end lineage covering everything from upstream sources to the warehouse and BI layer, customers stay informed across complex data stacks with powerful root cause and impact analysis. Read more about the Atlan + Fivetran partnership here!
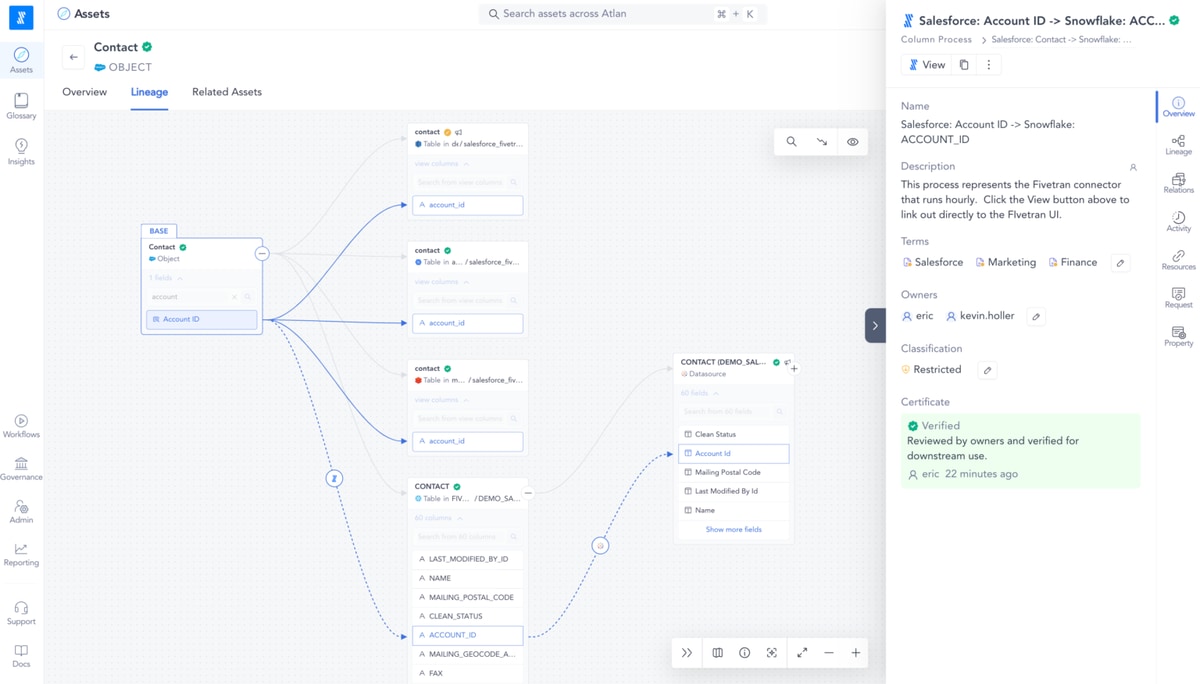
This integration improves daily workflows for diverse data users by unifying context from across the modern data stack and making it accessible anywhere via active metadata.
By making it easier to understand the flow of data from Fivetran through the data stack, trace data back to its origin at the column level, carry out root cause analysis for broken dashboards and notify downstream data consumers, data engineers can build trust and visibility for the entire organization. Meanwhile, data analysts can get complete context about the Fivetran sources, connectors and destinations that feed into their dashboards without actually leaving those dashboards.
Overall, this gives enterprises the first end-to-end view of the modern data stack, creating column-level lineage from sources like Salesforce and Postgres all the way to BI.
Hear more from Austin and Atlan at this year's Modern Data Stack Conference on April 4-5, 2023. Register with the discount code MDSCON-ATLANBLOG to get 20 percent off by March 31, 2023!
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







