A modern data lake with Fivetran Managed Data Lake Service and Databricks Unity Catalog

Over the past decade, organizations have rapidly shifted toward adopting cloud technology solutions for simple, usable, and scalable execution of their data architectures. Automated data integration through solutions like Fivetran centralizes data at scale, while cloud data providers like Databricks increasingly provide not only repositories, but suites of complementary capabilities surrounding data governance, analytics, and AI.
However, organizations are now encountering significant challenges as they scale data stacks to support growing data needs.
- Compliance issues emerge from duplicating data across multiple tools to gain access to new features.
- Data becomes increasingly difficult to govern with scale and variety, while data regulations become more stringent.
- Vendor lock-in through proprietary data formats creates restrictions and bottlenecks due to a lack of interoperability.
- Total cost of ownership rises in response to growing data volumes, advanced AI use cases, and a fragmented technology stack.
These challenges are driving data teams to a more streamlined architecture that delivers on the promise of separate storage and compute. By adopting vendor-neutral storage, organizations create a universal storage layer that can be accessed by a variety of downstream services without having to duplicate data into multiple systems.
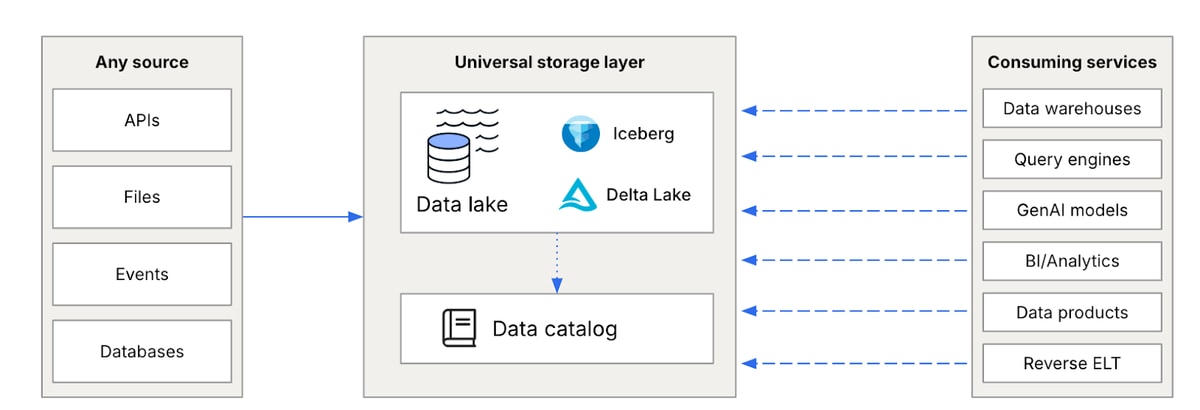
The emergence of the modern data lake with open table formats makes this pattern of “move once, query as needed” possible. This is why we have built the Fivetran Managed Data Lake Service for nearly 500 Fivetran and Databricks joint customers. We are unlocking the modern data lake by combining the usability of data warehouses and interoperability of data lakes with automated data integration.
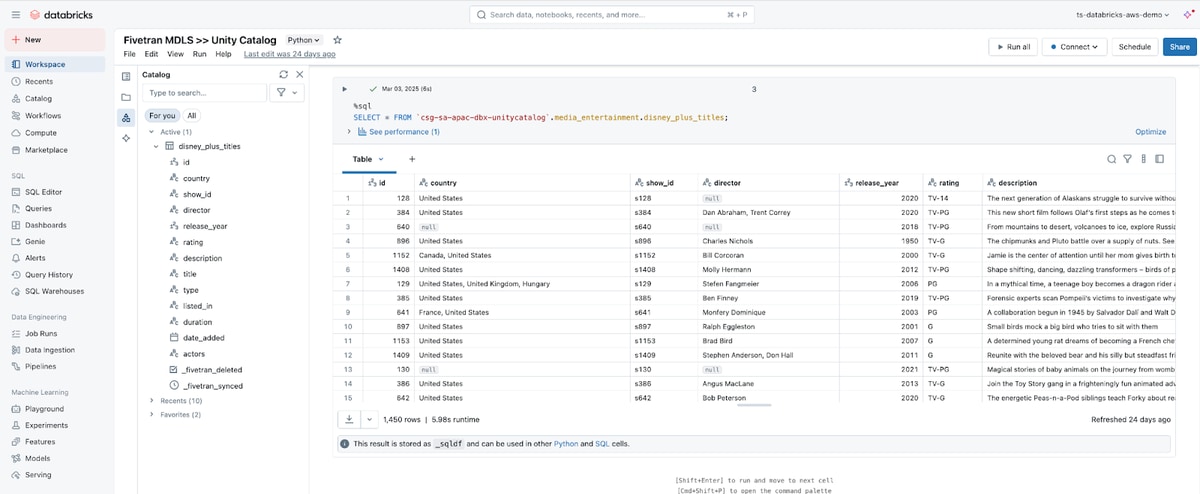
Gerard Wolfaardt, one of the co-founders of The Data Collective - a data and AI services consultancy in New Zealand - is rolling out data lake architecture leveraging Fivetran, Databricks, and Unity catalog at scale with an “ingest once and use many times” pattern.
The flexibility provided by Fivetran's Managed Data Lake Service is a real game changer. Rather than ingesting data into separate development, QA, and production environments (which can significantly increases ingest costs), we can ingest data once into shared data lake storage, register the data in Unity Catalog, and make that catalog accessible to any Databricks workspace. This allows us to leverage the centralised governance and security of Unity Catalog combined with a vendor-neutral data lake for storage, which makes for really good architecture."
—Gerard Wolfaardt, Co-founder and Principal Consultant, The Data Collective
[CTA_MODULE]
What components make up a modern data lake architecture?
A modern data lake architecture is characterized by the following four capabilities:
- Data integration: Data originates from hundreds of data sources. Automated data integration technologies like Fivetran can capture and replicate changes in these data sources accurately and in near-real time to your data lake.
- Open table format: Open table formats enable querying using SQL, schema enforcement, time travel, and other essential data management practices. We have previously discussed the criticality of open table formats to enable interoperability. Interoperability is key to how we think about data lakes, as demonstrated by our ability to write data in both Apache Iceberg and Delta Lake table format to all major data lake destinations (we write the data once, and the metadata twice), solving the problem of vendor lock-in.
- Vendor-neutral storage: Data needs to be stored somewhere that reduces vendor lock-in, is easily scalable, and is cost-effective. The major cloud providers all offer great options for object storage such as S3, ADLS, and GCS.
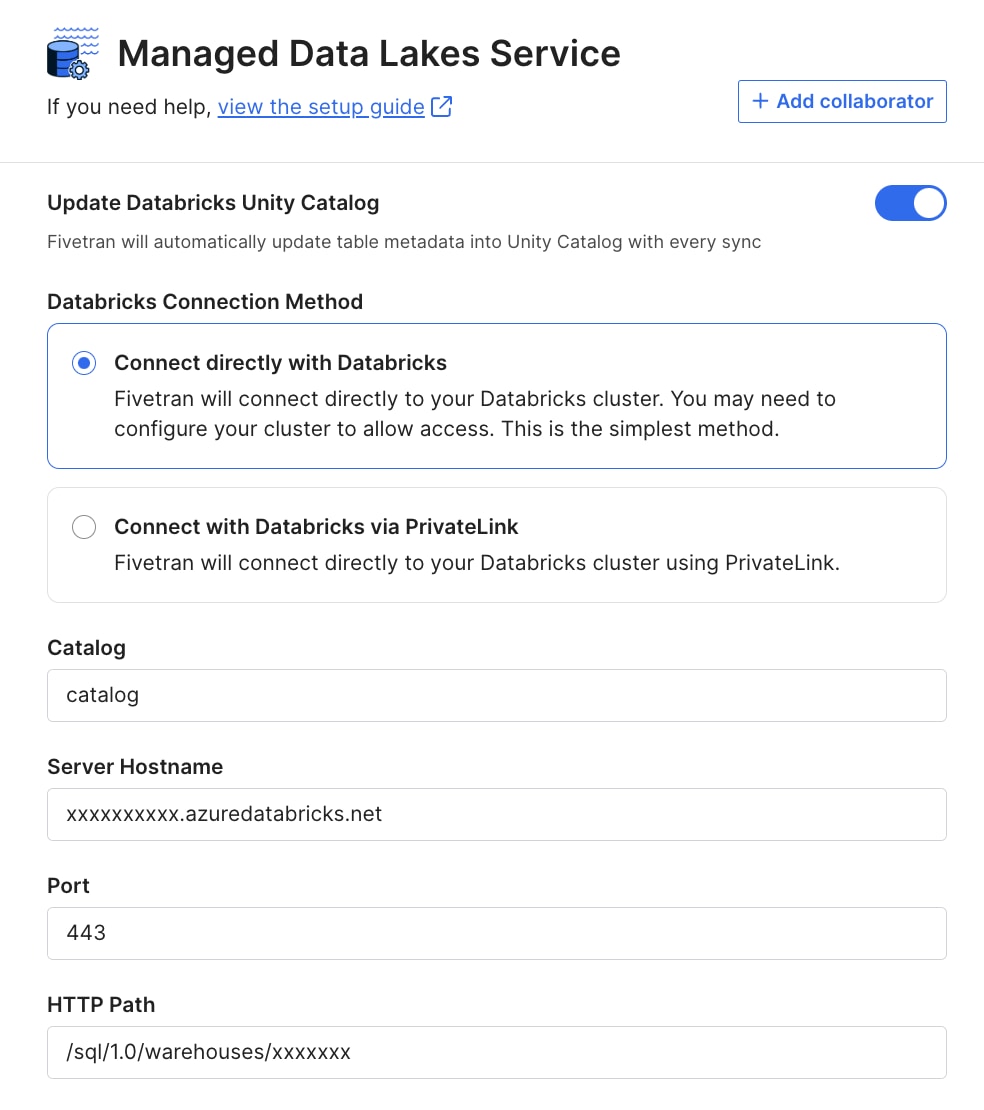
- Technical catalog: A technical catalog provides query engine interoperability and discoverability to a data lake with open table formats. For Databricks customers, Unity Catalog allows users to manage and discover technical metadata for specific tools and data sources. Fivetran automatically writes metadata to Unity Catalog with every data sync for an up-to-date view of your data.
Design decisions for a modern data lake with the Fivetran Managed Data Lake Service and Databricks
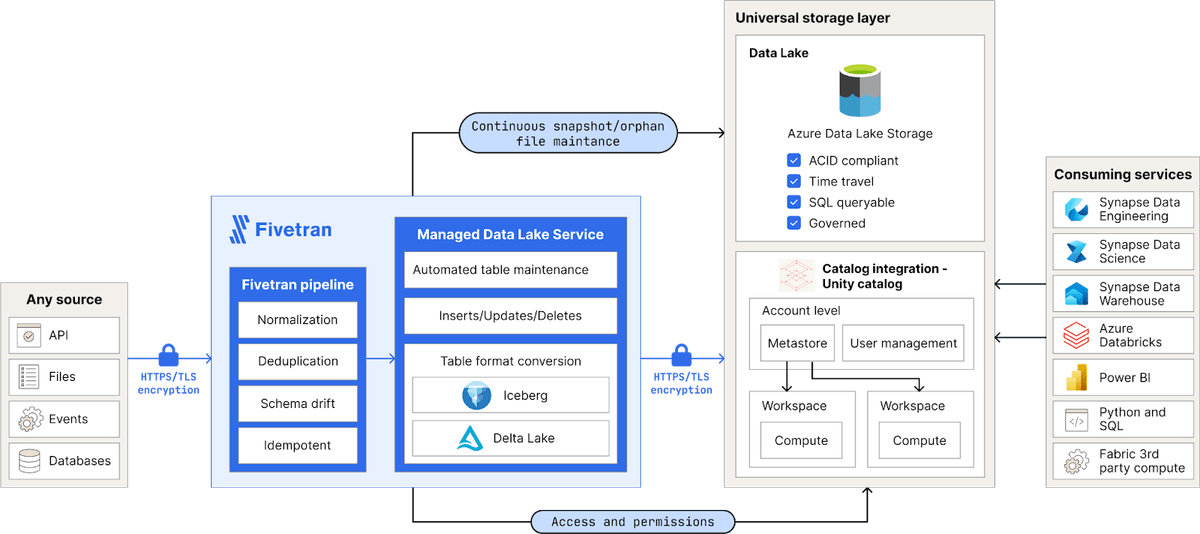
Data integration
Fivetran offers automated data integration from 700+ data sources to major data lakes. We write your data into open table formats, automate table maintenance, and host and integrate with technical catalogs. The user experience is no-code, consisting entirely of navigating a series of menus. It is as simple as selecting your data lake destination, selecting your catalog, and setting up some initial connections.
Vendor-neutral storage
In the architectural design above, we chose Azure Data Lake Storage Gen 2 as our storage solution, although Databricks also supports S3. Fivetran handles table maintenance and performance. You do not need to worry about inflating your storage location with old snapshots, metadata, and untracked data files. A copy-on-write methodology not only ensures high read and query performance but also maintains data consistency, as the atomicity of data is preserved by completely rewriting files. This ensures data remains unchanged until necessary, thereby mitigating potential data integrity issues.
Open table format
While Delta Lake table format is traditionally the default open table format for Databricks, the Fivetran Managed Data Lake Service can also write Apache Iceberg metadata to ADLS. Check out our blog on open-table formats to learn more.
Technical catalog
Databricks Unity Catalog offers unified data governance for structured and unstructured data across clouds and platforms. It is able to simplify data control, auditing, lineage, and data discovery. It is crucial for streamlining the adoption of a modern data lake architecture with Databricks.
With the Fivetran Managed Data Lake Service automatically updating Unity Catalog upon every data sync, your end users will have the same query experience - whether it is Databricks native or Azure Data Lake Storage, all visible through a single pane provided by Unity Catalog.
Technically, the Unity catalog establishes a hierarchical structure beginning with the metastore, a top-level container that is the primary control point for data assets and access rights. The metastore is essential for unifying storage and enabling scalable data lake access through Databricks workspaces, each containing a nested database object hierarchy which consists of:
- Catalog: the catalog is the primary organization layer and where the highest level of data isolation can be defined.
- Schemas: the second level of the hierarchy that contains all tables, views, volumes, and functions.
- Tables, views, functions, and models: the base level of the database object hierarchy. They live within the schema.

When using our native integration, the Fivetran Managed Data Lake Service automatically updates the schemas and tables. To build a centralized architecture, your metastore connects your storage location with Unity Catalog and acts as a hub. You can attach as many Databricks workspaces as necessary, removing the need to set up multiple Databricks workspace destinations in Fivetran or maintain multiple development environments.
Getting started
The Fivetran setup is easy and should take you no longer than 30 minutes with the appropriate credentials handy. To set up an Azure Data Lake Storage destination in Fivetran there are a couple of pre-requisites required ahead of time:
- An ADLS Gen2 account with Administrator permissions
- An ADLS Gen2 container
- Permission to create an Azure service principal
There are two methods for setting up the Unity Catalog. For manual table creation, we provide the required steps in our setup guide. Otherwise, to leverage the Unity Catalog native integration, with automatic schema and table management, the prerequisites are below:
- A Databricks account.
- Unity Catalog enabled in your Databricks workspace
- A SQL warehouse. Legacy deployments can continue to use Databricks clusters with Databricks Runtime v7.0 or above.

You have full control over the time of your snapshot retention period of older metadata/untracked files. You can omit the cleanup process or select from a predefined list of retention periods.
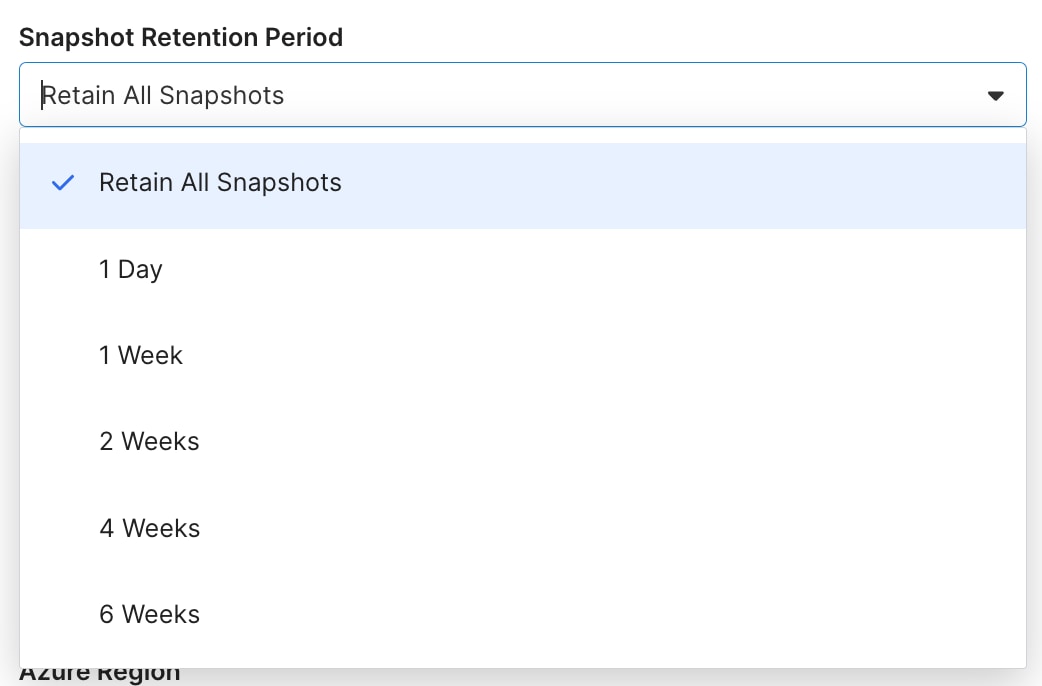
Once you have worked through all the prerequisites, and made your security and operational selections, click “Save and Test” and you are off to the races.
Modern data lakes address challenges like vendor lock-in and rising costs by automating data replication, centralizing storage into a single source of truth, optimizing data management with open table formats, and implementing a universal data governance model and data consistency through a data catalog.
Fivetran's Managed Data Lake Service unlocks the ability to combine the usability of a data warehouse with the scalability of a data lake by utilizing open table formats like Delta Lake and Apache Iceberg and integrating with data catalogs like Databrick’s Unity Catalog delivering the following benefits
- Reduced total cost of ownership: Ingest costs are optimized through the de-duplication of data into multiple downstream systems by adopting a universal storage layer.
- Optimized data lake: Fivetran automates and manages the heavy lifting when writing and maintaining data in a data lake. Schema migration and evolution are automated, preventing pipeline breaks and ensuring changes in the data lake are replicated accurately.
- Automated governance: Data blocking and hashing keep sensitive data from replicating to the lake while integrations with catalogs ensure ACID compliance and discoverability across your ecosystem.
- Reduced vendor lock-in and access to best-of-breed tooling: Interoperability of open table formats and catalogs allows your team to choose the best tooling for your use case.
[CTA_MODULE]
Related blog posts
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.







