ETL im Vergleich zu ELT: Wählen Sie den richtigen Ansatz für die Datenintegration


ETL (Extrahieren, Transformieren und Laden) und ELT (Extrahieren, Laden und Transformieren) sind Datenintegrationsmethoden, die festlegen, wie Daten von der Quelle zur Speicherung übertragen werden.
Obwohl ETL eine ältere Methode ist, wird sie auch heute noch häufig eingesetzt und kann in bestimmten Szenarien ideal sein. ELT hingegen ist eine neuere Methode, die auf Flexibilität und Automatisierung ausgerichtet ist.
Beide Verfahren umfassen drei Hauptvorgänge:
- Extraktion: Ziehen der Daten aus der ursprünglichen Quelle (z. B. einer App oder SaaS-Plattform).
- Transformation: Änderung der Struktur der Daten, damit sie in das Zieldatensystem integriert werden können.
- Laden: Ablegen von Daten in einem Speichersystem.
Die Unterschiede ergeben sich aus der Reihenfolge dieser Vorgänge. ETL konzentriert sich auf die Transformation direkt nach der Extraktion, während ELT die Daten vor der Transformation extrahiert und lädt.
In diesem Artikel befassen wir uns ausführlich mit ELT und ETL, damit Sie verstehen, wie sie funktionieren, und die richtige Datenintegrationsmethode wählen können. Wir haben eine praktische Tabelle beigefügt, in der die Unterschiede zwischen den beiden Verfahren erläutert werden.
[CTA_MODULE]
Was ist ETL?
Das Akronym „ETL“ steht für Extrahieren, Transformieren, Laden. Es handelt sich um eine beliebte Datenintegrationsmethode, die aus drei Hauptoperationen besteht:
- Sammeln und Extrahieren von Daten
- Laden von Daten in ein Ziel
- Umwandlung in Modelle, die von Analysten verwendet werden können
ETL ist der traditionelle Ansatz zur Datenintegration. Es wurde in den 1970er Jahren erfunden und ist so allgegenwärtig, dass „ETL“ oft synonym mit Datenintegration verwendet wird.
Im Rahmen von ETL extrahieren Datenpipelines Daten aus Quellen, wandeln Daten in Datenmodelle um, die Analysten in Berichte und Dashboards umwandeln können, und laden dann Daten in ein Data Warehouse.

Bei der Datentransformation werden die Daten in der Regel aggregiert oder zusammengefasst, wodurch sich ihr Gesamtvolumen verringert. Dies war entscheidend, als ETL zum ersten Mal entwickelt wurde und die meisten Unternehmen unter sehr strengen technologischen Beschränkungen arbeiteten.
Speicherplatz, Rechenleistung und Bandbreite waren extrem knapp. Durch die Umwandlung vor dem Laden verringert ETL das Volumen der im Warehouse gespeicherten Daten. Dieses Verfahren schont die Ressourcen während des gesamten Workflows.
Der ETL-Workflow umfasst die folgenden Schritte:
- Identifizieren Sie Ihre Datenquellen
- Legen Sie die genauen Datenanalyseanforderungen fest, die das Projekt erfüllen soll
- Definieren Sie das Datenmodell/Schema, das die Analysten und andere Endbenutzer benötigen
- Bauen Sie die Pipeline auf
- Führen Sie Analysen durch und gewinnen Sie Erkenntnisse

Bei ETL werden Extraktion und Transformation durchgeführt, bevor die Daten in ein Ziel geladen werden. Diese beiden Prozesse sind also miteinander verknüpft. Und da die Transformationen von den spezifischen Anforderungen der Analysten abhängen, ist jede ETL-Pipeline eine komplizierte, maßgeschneiderte Lösung.
Die Komplexität dieser Pipelines macht die Skalierung sehr schwierig, insbesondere wenn Datenquellen und Modelle hinzugefügt werden.
Der Workflow Ihrer ETL-Pipeline muss jedes Mal wiederholt und geändert werden, wenn diese beiden häufigen Bedingungen auftreten:
- Änderungen an der Quelle: Wenn Felder an der Quelle hinzugefügt, gelöscht oder bearbeitet werden, ändern sich die vorgelagerten Schemata und machen den Code ungültig, der zur Transformation der Rohdaten in die gewünschten Datenmodelle verwendet wird.
- Neue Datenkonfigurationen: Wenn ein Analyst ein Dashboard oder einen Bericht erstellen möchte, für den Daten in einer neuen Konfiguration erforderlich sind, müssen die nachgeschalteten Analysen geändert werden. Der Transformationscode muss umgeschrieben werden, um neue Datenmodelle zu erzeugen.
Jede Organisation, die ihre Datenkompetenz ständig verbessert, wird regelmäßig auf diese beiden Bedingungen stoßen.
Da Extraktion und Transformation voneinander abhängig sind, verhindert eine Unterbrechung der Transformation auch das Laden der Daten in das Ziel, was zu Ausfallzeiten führt.
Die Verwendung von ETL-Tools für die Datenintegration ist mit folgenden Herausforderungen verbunden:
- Kontinuierliche Wartung – Bei jeder Änderung der vor- oder nachgelagerten Schemata wird die Pipeline unterbrochen, und oft ist eine umfangreiche Überarbeitung der Codebasis der ETL-Software erforderlich.
- Individualisierung und Komplexität – Datenpipelines extrahieren nicht nur Daten, sondern führen auch anspruchsvolle Transformationen durch, die auf die spezifischen Analyseanforderungen der Endnutzer zugeschnitten sind. Dies bedeutet eine große Menge an benutzerdefiniertem Code.
- Arbeitsintensiv und teuer – Da das System auf einer komplexen Code-Basis läuft, ist ein Team engagierter Datenentwickler erforderlich, um es aufzubauen und zu pflegen.
Diese Herausforderungen ergeben sich aus dem kritischen Kompromiss, der bei ETL eingegangen wird, nämlich der Einsparung von Rechen- und Speicherressourcen auf Kosten der Arbeit.
Technologische Trends hin zur Datenintegration in der Cloud
Intensive Arbeit war akzeptabel, wenn die Ressourcen begrenzt und teuer und der Umfang und die Vielfalt der Daten unbedeutend waren.
ETL war ein Produkt seiner Zeit. Viele dieser Beschränkungen bestehen jedoch nicht mehr.
Insbesondere die Kosten für die Speicherung sind in den letzten vier Jahrzehnten von fast 1 Million USD auf wenige Cent pro Gigabyte (ein Faktor von 50 Millionen) gesunken.

Ebenso sind die Rechenkosten um einen Millionenfaktor und die Kosten für die Internetübertragung um einen Tausenderfaktor gesunken.
Diese Trends haben ETL für die meisten Zwecke in zweierlei Hinsicht überflüssig gemacht:
- Die Erschwinglichkeit dieser wichtigen Elemente hat zu einem explosionsartigen Wachstum cloudbasierter Dienste geführt. Mit dem Wachstum der Cloud haben auch das Volumen, die Vielfalt und die Komplexität der Daten zugenommen. Eine spröde, komplizierte Pipeline, die ein begrenztes Volumen und eine begrenzte Datengranularität integriert, ist nicht mehr ausreichend.
- Moderne Datenintegrationstechnologien haben weniger Beschränkungen hinsichtlich des zu speichernden Datenvolumens und der Häufigkeit der Abfragen innerhalb eines Warehouses.
Diese beiden Faktoren haben eine Neuordnung des Datenintegrations-Workflows sinnvoll gemacht. Vor allem aber können es sich Unternehmen jetzt leisten, nicht umgewandelte Daten in Data Warehouses zu speichern.
Was ist ELT?
Extrahieren, Laden und Transformieren (ELT) ist ein neuerer Datenintegrationsprozess, bei dem die Daten unmittelbar nach der Extraktion aus der/den Quelle(n) in ein Ziel geladen werden und der Transformationsschritt an das Ende des Workflows verschoben wird.
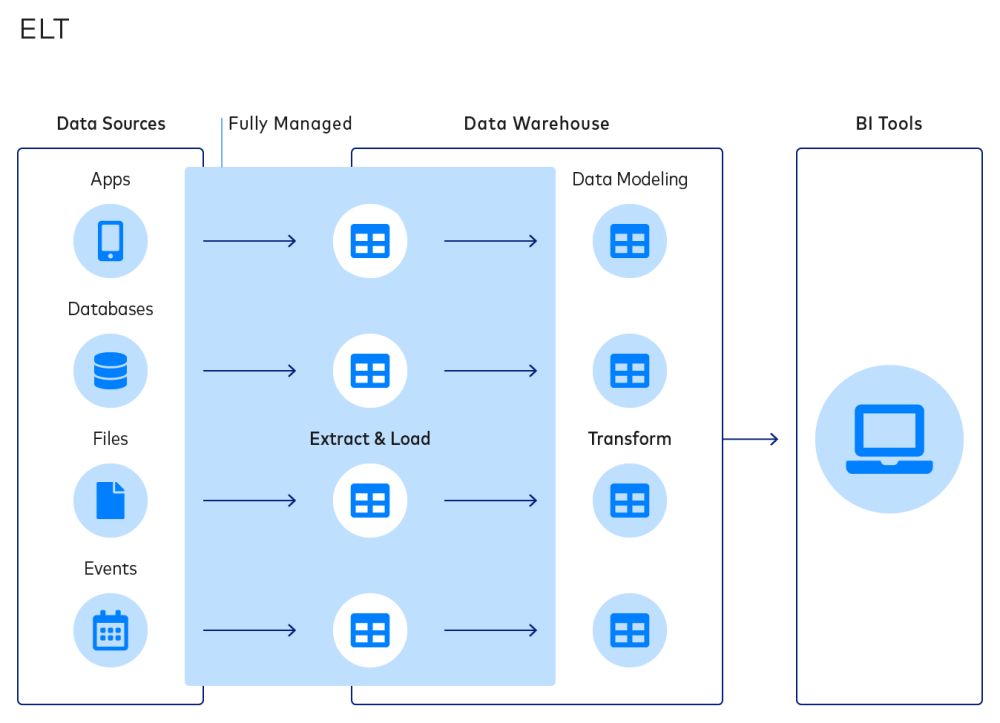
Dies ist ein grundlegend anderer Prozess als bei ELT. In den letzten Jahren sind Unternehmen aus den verschiedensten Branchen aufgrund der Vorteile von ELT von ETL auf ELT umgestiegen. Zum einen werden die Extraktions- und Transformationsprozesse entkoppelt.
Dadurch wird verhindert, dass die beiden Fehlerzustände von ETL (d. h. die Änderung von vorgelagerten Schemata und nachgelagerten Datenmodellen) die Extraktion und das Laden beeinträchtigen, was zu einem einfacheren und robusteren Ansatz für die Datenintegration führt.
Im Gegensatz zu ETL hat der ELT-Workflow einen kürzeren Zyklus:
- Identifizieren Sie die gewünschten Datenquellen
- Führen Sie eine automatisierte Extraktion/automatisiertes Laden durch
- Legen Sie die genauen Analyseanforderungen fest, die das Projekt erfüllen soll
- Erstellen Sie Datenmodelle durch den Aufbau von Transformationen
- Führen Sie tatsächliche Analysen durch und gewinnen Sie Erkenntnisse

Der ELT-Workflow ist einfacher und besser anpassbar. Dies ist besser für Analysten, die die Flexibilität wünschen, maßgeschneiderte Datentransformationen nach Bedarf zu erstellen, ohne die Datenpipeline neu aufbauen zu müssen.
Während sowohl ELT als auch ETL Daten in einem Data Warehouse als Endziel speichern, können ELT-Pipelines auch Data Lakes verwenden, um große unstrukturierte Daten während des Prozesses zu speichern. Diese Data Lakes werden mit einem verteilten NoSQL-Datenverwaltungssystem oder Big-Data-Plattformen verwaltet.
ELT-Workflows lassen sich leichter anpassen und werden oft nicht nur für Business Intelligence verwendet. Unternehmen können sie für prädiktive Analysen, Echtzeitdaten und Ereignisströme zur Steuerung von Anwendungen, künstlicher Intelligenz und maschinellem Lernen nutzen.
Warum ELT die Zukunft ist
Sowohl ETL als auch ELT haben deutliche Vorzüge, aber ELT hat sechs klare Vorteile, die es zukunftssicher und benutzerfreundlich machen:

1. Vereinfachte Datenintegration
In ELT kann das Ziel mit Daten direkt aus der Quelle befüllt werden, wobei lediglich eine leichte Bereinigung und Normalisierung erforderlich ist, um die Datenqualität und die Benutzerfreundlichkeit für Analysten zu gewährleisten.
Analysten und Datenwissenschaftler, deren Aufgaben sich oft mehr um die Datenintegration als um die eigentliche Analyse drehen, können endlich ihr Verständnis für die geschäftlichen Anforderungen nutzen und es für eine bessere Modellierung und Analyse einsetzen.
Eine vereinfachte Datenintegrationslösung rationalisiert auch das Data Engineering. So können sich Entwickler auf unternehmenskritische Projekte wie die Optimierung der Dateninfrastruktur eines Unternehmens oder die Entwicklung von Vorhersagemodellen konzentrieren, statt komplexe Datenpipelines zu erstellen und zu pflegen.
Die Implementierung von ELT bedeutet auch, dass Unternehmen Daten aus verschiedenen Datensätzen und in verschiedenen Formaten kombinieren können. Sie können auch strukturierte, unstrukturierte, verwandte oder nicht verwandte Daten zusammenstellen.
2. Geringere Ausfallraten
Bei ELT-Workflows werden die Daten vor ihrer Transformation an ihren Speicherort verschoben. Die Extraktions- und Ladevorgänge sind also unabhängig von der Transformation. Diese Unabhängigkeit verhindert Verzögerungen während des Transformationsprozesses.
Obwohl die Transformationsschicht immer noch ausfallen kann, wenn sich vorgelagerte Schemata oder nachgelagerte Datenmodelle ändern, verhindern diese Fehler nicht mehr, dass Daten in ein Data Warehouse oder einen Data Lake geladen werden.
Stattdessen kann ein Unternehmen weiterhin Daten extrahieren und laden, auch wenn die Analysten regelmäßig Transformationen neu schreiben. Da diese Daten mit minimalen Änderungen an ihrem Bestimmungsort ankommen, dienen sie als umfassende, aktuelle Quelle der Wahrheit.
3. Automatisierte Arbeitsabläufe
Ein Unternehmen, das Automatisierung mit ELT kombiniert, kann seinen Datenintegrations-Workflow drastisch verbessern.
Da das automatische Extrahieren und Laden Rohdaten liefert, kann es zur Erstellung einer standardisierten Ausgabe verwendet werden. Damit entfällt die Notwendigkeit, ständig Pipelines mit benutzerdefinierten Datenmodellen zu erstellen und zu pflegen. Außerdem können abgeleitete Produkte, wie z. B. Analysevorlagen, erstellt und auf das Zielsystem aufgesetzt werden.
Die Automatisierung der Extraktion und des Ladens macht manuelle, arbeitsintensive Aufgaben überflüssig und gibt Analysten die Möglichkeit, sich auf die eigentliche Analyse der Daten zu konzentrieren, statt sie zu sammeln und vorzubereiten.
4. Leichteres Outsourcing
Da die ETL-Pipeline standardisierte Ausgaben produzieren kann und Änderungen an der Pipeline einfacher sind, ist es leichter, die Datenintegration an Dritte auszulagern.
Plattformen wie Fivetran bieten eine nahtlose Datenerfassung und trennen sie automatisch in Spalten, Zeilen und Tabellen. Ihre Analysten können in wenigen Minuten frische, organisierte Daten erhalten. Außerdem verfügt das Unternehmen über ein Team von Entwicklern und vollständig verwaltete Konnektoren, die Ihre Pipelines für Sie warten.

Outsourcing ist auch eine günstige Option, wenn es um Sicherheit, Datenschutz und Compliance geht. Fivetran bietet Verschlüsselung in allen Phasen, die Möglichkeit, sensible Daten zu hashen, bevor sie den Bestimmungsort erreichen, volle Kontrolle über den Umgang mit Daten und sichere Anmeldeoptionen.
Der Einsatz solcher Plattformen zur Verwaltung Ihrer Datenpipelines spart Zeit und ist oft günstiger als die Einstellung eines Teams von Datenentwicklern.
5. Flexible Skalierung
Der Bedarf an Unternehmensdaten ändert sich ständig, je nach Geschäft, Markt und Kundenbeziehungen. Wenn die Datenverarbeitungslasten zunehmen, können automatisierte Plattformen, die Cloud Data Warehouses nutzen, innerhalb von Minuten oder Stunden automatisch skaliert werden.
Bei ETL ist die Skalierung viel schwieriger und zeitaufwändiger, da neue Hardware bestellt, installiert und konfiguriert werden muss.
Je nach Datenbedarf können Sie auch Ihre Datenverarbeitung und -speicherung verkleinern. Statt Hardware zu deinstallieren und physische Geräte abzubauen, können Sie mit einer Cloud-basierten Plattform wie Fivetran Ihre Pipelines in wenigen Minuten ändern.
Die Skalierung ist auch einfacher, wenn Ihre Datenintegrationsplattform Integrationen mit Ihren Datenquellen unterstützt.
6. Unterstützung von SQL-Transformationen
In einer ELT-Pipeline werden die Transformationen innerhalb der Data-Warehouse-Umgebung durchgeführt.
Es ist nicht mehr erforderlich, Transformationen über Drag-and-Drop-Schnittstellen zu entwerfen, Modifikationen mit Skriptsprachen wie Python zu schreiben oder komplexe Orchestrationen zwischen verschiedenen Datenquellen aufzubauen.
Stattdessen können Sie Transformationen in SQL schreiben, der Muttersprache der meisten Analysten. Dadurch wird die Datenintegration von einer IT- oder entwicklerzentrierten Tätigkeit zu einer Tätigkeit, die Analysten direkt und einfach übernehmen können.
Analysten haben die Freiheit, Daten nach Bedarf umzuwandeln und wertvolle Erkenntnisse zu gewinnen, die wichtige Geschäftsentscheidungen vorantreiben, die Problemlösung verbessern und besser auf Kundenbedürfnisse eingehen können.
Es gibt einige Fälle, in denen ETL gegenüber ELT immer noch vorzuziehen sein kann. Dazu gehören insbesondere folgende Fälle:
- Die gewünschten Datenmodelle sind bekannt und werden sich wahrscheinlich nicht so schnell ändern. Dies ist insbesondere dann der Fall, wenn ein Unternehmen auch Systeme entwickelt und pflegt, die Quelldaten erzeugen.
- Für die Daten gelten strenge Sicherheitsanforderungen und Vorschriften, und sie dürfen auf keinen Fall an einem Ort gespeichert werden, der gefährdet sein könnte.
Diese Bedingungen sind in der Regel charakteristisch für sehr große Unternehmen und Organisationen, die sich auf Software-as-a-Service-Produkte spezialisiert haben.
In solchen Fällen kann es sinnvoll sein, ELT für die Datenintegration mit SaaS-Produkten von Drittanbietern zu verwenden, während ETL für die Integration interner, proprietärer Datenquellen beibehalten wird.
Probieren Sie ELT kostenlos aus
ETL und ELT sind beides solide Datenintegrationsprozesse mit ihren eigenen idealen Anwendungsfällen. Heute ist ELT jedoch für die große Mehrheit der Unternehmen eindeutig die bessere Option. Sie hätten gerne einen einfacheren und schnelleren Zugang zu ihren Geschäfts- und Kundendaten? Mit ELT können Sie das erreichen.
ELT ermöglicht Automatisierung, Outsourcing und Integrationen mit Dritten. Diese Funktionalitäten sparen in Unternehmen Zeit und Geld und ermöglichen es den Analysten, die richtigen Erkenntnisse zu gewinnen.
Eine cloudbasierte Datenintegrationsplattform wie Fivetran ist die perfekte Lösung für die Implementierung sicherer Datenpipelines in verschiedenen Branchen. Mit unserem Tool können Sie Daten aus allen von Ihnen verwendeten Datenbanken und Anwendungen sammeln und an einem zentralen Ziel zusammenführen.
Wenn Sie noch unsicher sind, sollten Sie es mit eigenen Augen sehen. Das Free-Abonnement von Fivetran, das dbt Core-kompatible Datenmodelle enthält, ermöglicht es Ihnen, ELT völlig kostenlos zu testen.
[CTA_MODULE]
Verwandte Beiträge
Kostenlos starten
Schließen auch Sie sich den Tausenden von Unternehmen an, die ihre Daten mithilfe von Fivetran zentralisieren und transformieren.









