ETL vs ELT : choisir la bonne approche pour l’intégration de data


L’ETL (extraction, transformation et chargement) et l’ELT (extraction, chargement et transformation) sont des méthodes d’intégration de data qui régissent la manière dont les données sont transférées de leur source vers leur point de stockage.
Bien que l’ETL est une méthode ancienne, elle est encore largement utilisée et est même idéale dans certains cas. L'ELT est, quant à elle, une méthode plus récente, axée sur la flexibilité et l’automatisation.
Ces deux processus ont trois objectifs principaux :
- L'extraction : extraire les data de leur source d’origine (par exemple, une application ou une plateforme SaaS).
- La transformation : modifier la structure des data afin qu’elles soient intégrées dans le système data cible.
- Le chargement : déposer les data dans un système de stockage.
Les différences résident dans l’ordre d’exécution de ces opérations. L’ETL effectue la transformation juste après l’extraction, tandis que l’ELT extrait et charge les data avant de les transformer.
Dans cet article, nous explorons en détail l’ELT et l’ETL ainsi que le fonctionnement des méthodes d’intégration de data. Grâce à ces informations, vous pourrez choisir celle qui vous convient le mieux. Nous avons inclus un tableau pratique expliquant les différences entre les deux processus.
[CTA]
Qu’est-ce que l’ETL?
L’acronyme « ETL » correspond à Extract, Transform, Load en anglais, ou Extraction, Transformation, Chargement en français. Il s’agit d’une méthode d’intégration de data populaire constituée de trois opérations principales :
- Regroupement et extraction des data
- Chargement des data vers une destination
- Transformation des data en modèles utilisables par les analystes
L’ETL constitue l’approche traditionnelle de l’intégration de data. Inventée dans les années 1970, cette méthode est tellement répandue que l’acronyme « ETL » est souvent utilisé de manière interchangeable avec le terme « intégration de data ».
Dans le cadre de l’ETL, les pipelines extraient des data de sources et les transforment en modèles pour permettre aux analystes d'en tirer des rapports et tableaux de bord. Ces data sont ensuite stockées dans un data warehouse.

Généralement, les transformations de data rassemblent ou résument des data, ce qui permet de réduire leur volume global. Ce point était essentiel lors de la conception de l’ETL, à une époque où la plupart des organisations faisaient face à de réelles contraintes technologiques.
Le stockage, le calcul et la bande passante étaient alors fortement limités. En effectuant la transformation avant le chargement, l’ETL réduit le volume des data stockées dans le warehouse. Ce processus permet de préserver les ressources dans l’ensemble du flux de travail.
Le flux de travail ETL comprend les étapes suivantes :
- Identification des sources de data
- Détermination des besoins exacts en matière d’analyse de data que le projet doit résoudre
- Définition du modèle/schéma de data requis pour les analystes et d’autres utilisateurs finaux
- Construction du pipeline
- Réalisation du travail d’analyse et extraction d’informations

Dans l’ETL, l’extraction et la transformation sont effectuées avant le chargement des data vers une destination. Ces deux processus sont donc étroitement liés. En outre, puisque les transformations sont dictées par les besoins spécifiques des analystes, chaque pipeline ETL est une solution personnalisée et complexe.
La nature complexe de ces pipelines rend l’évolutivité très difficile, en particulier lors de l’ajout de modèles et de sources de data.
Le flux de travail de votre pipeline ETL doit être répété et modifié chaque fois que ces deux conditions se produisent :
- Modifications de la source : lors de l’ajout, de la suppression ou de la modification de la source, les schémas en amont sont modifiés et invalident le code utilisé pour transformer les data brutes en modèles data souhaités.
- Nouvelles configurations de data : lorsqu’un analyste souhaite construire un tableau de bord ou un rapport qui nécessite une nouvelle configuration de data, l’analyse en aval doit être modifiée. Il faut réécrire le code de transformation afin de produire de nouveaux modèles de data.
Les organisations qui améliorent en permanence leur connaissance des data sont souvent confrontées à ces deux conditions.
Étant donné que l’extraction et la transformation sont deux opérations codépendantes, des interruptions de transformation permettent également d’éviter que les data ne soient chargées vers la destination, ce qui crée un temps d’arrêt.
L’utilisation d’outils ETL pour l’intégration de data soulève les défis suivants :
- Maintenance constante : chaque fois qu’une modification est effectuée dans les schémas en amont ou en aval, le pipeline cesse de fonctionner et une révision complète de la base de code du logiciel ETL est souvent nécessaire.
- Personnalisation et complexité : les pipelines de data extraient non seulement les data, mais effectuent également des transformations sophistiquées qui s'adaptent aux besoins d'analyse spécifiques des utilisateurs. Cela se traduit par une grande quantité de code personnalisé.
- Travail fastidieux et coûteux : étant donné que le système exécute une base de code complexe, une équipe d’ingénieurs data dédiée est nécessaire pour le construire et l'entretenir.
Ces défis résultent du compromis critique de l’ETL, qui concerne la conservation des ressources de calcul et de stockage au détriment du travail.
Tendances technologiques vers l’intégration de data cloud
Un travail intensif était acceptable lorsque les ressources étaient limitées et chères, mais aussi lorsque le volume et la variété des data étaient insuffisants.
L’ETL était donc un produit de son époque. Mais aujourd’hui, bon nombre de ces contraintes ne sont plus d’actualité.
En particulier, le coût du stockage a chuté de près de 1 million de dollars à quelques centimes par gigaoctet (facteur de 50 millions) en l’espace de quatre décennies.

De même, les coûts liés au calcul ont considérablement baissé selon un facteur de plusieurs millions. Le coût du transit par internet a lui chuté selon un facteur de plusieurs milliers.
Ces tendances ont rendu l’ETL obsolète pour la plupart des utilisations, et ce de deux manières :
- Le caractère abordable de ces éléments critiques a entraîné une croissance considérable des services basés sur le cloud. À mesure que le cloud se développe, le volume, la variété et la complexité des data augmentent également. Un pipeline complexe et peu robuste intégrant un volume limité et une granularité des data n’est plus suffisant.
- Les technologies modernes d’intégration de data présentent moins de restrictions sur le volume de data à stocker et la fréquence des requêtes envoyées dans un warehouse.
Ces deux facteurs ont simplifié la réorganisation du flux de travail d’intégration de data. Plus important encore, les organisations peuvent désormais se permettre financièrement de stocker des data non transformées dans des data warehouses.
Qu’est-ce que l’ELT?
L’ELT (extraction, chargement, transformation) est un nouveau processus d’intégration de data, dans lequel les data sont immédiatement chargées d’une ou plusieurs sources vers une destination au moment de l’extraction. L’étape de transformation est déplacée à la fin du flux de travail.
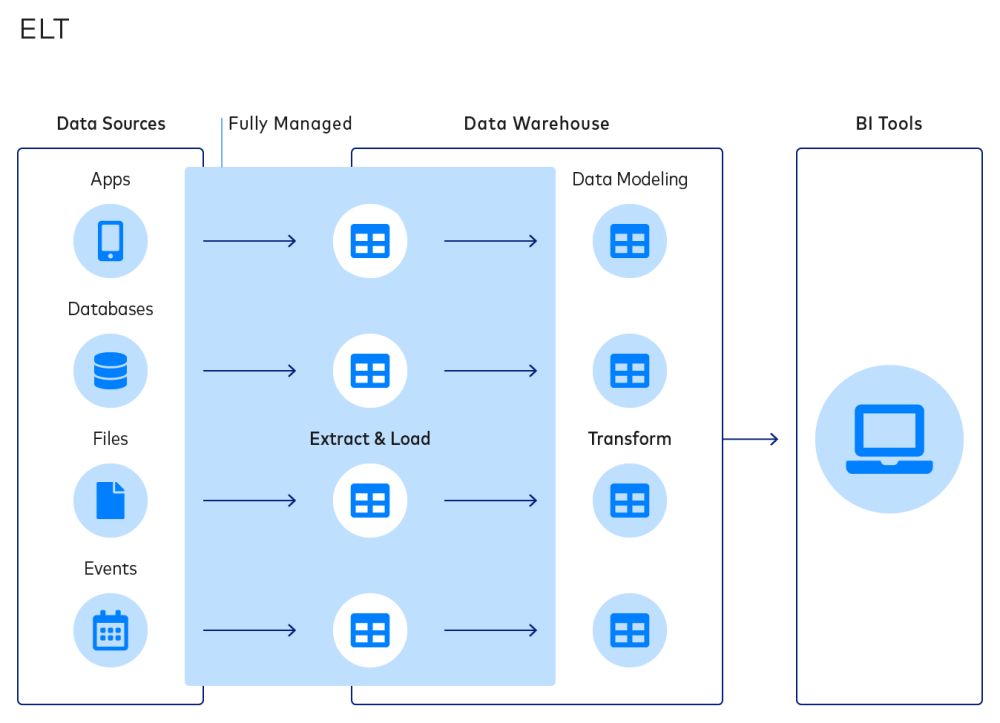
Il s’agit d’un processus fondamentalement différent de l’ELT. Ces deux dernières années, les entreprises de nombreux secteurs ont abandonné l’ETL en raison des avantages présentés par l’ELT. Par exemple, cette méthode permet de découpler les processus d’extraction et de transformation.
Cela permet d’éviter que les deux états de défaillance de l’ETL (modification des schémas en aval et des modèles de data en amont) aient un impact sur l’extraction et le chargement, ce qui donne lieu à une approche d’intégration de data plus simple et plus fiable.
Par rapport à l’ETL, le flux de travail ELT présente un cycle plus court :
- Identification des sources de data souhaitées
- Exécution de l’extraction et du chargement automatisés
- Détermination des besoins exacts en matière d’analyse que le projet doit résoudre
- Création de modèles de data via la construction de transformations
- Réalisation du travail réel d’analyse et extraction d’informations

Le flux de travail ELT est plus simple et davantage personnalisable. Cela est bénéfique pour les analystes qui souhaitent disposer de flexibilité pour créer des transformations de data au cas par cas, sans reconstructions du pipeline de data.
Tandis que l’ELT et l’ETL stockent des data dans un data warehouse comme destination finale, les pipelines ELT peuvent également utiliser des data lakes pour stocker des data non structurées à grande échelle pendant le processus. Ces data lakes sont gérés à l’aide d’un système de gestion des data NoSQL distribué ou de plateformes Big Data.
Les flux de travail ELT sont plus simples à personnaliser et souvent utilisés à des fins allant au-delà de la veille commerciale. Les organisations peuvent les utiliser pour l’analyse prédictive, les data en temps réel et la diffusion d’événements qui stimulent les applications, l’intelligence artificielle et l’apprentissage automatique.
Pourquoi l’ELT représente-t-il l’avenir?
L’ETL et l’ELT ont tous deux des mérites évidents, mais l’ELT présente six avantages principaux qui rendent cette méthode pérenne et simple d'utilisation :

1. Simplification de l’intégration de data
Dans l’ELT, la destination peut recevoir les data directement à partir de la source, avec de simples nettoyage et normalisation, qui garantissent une qualité des data et une facilité d’utilisation pour les analystes.
Les analystes et les data scientists, dont les responsabilités concernent davantage les activités d’intégration de data que l’analyse pure, peuvent enfin tirer profit de leur compréhension des besoins commerciaux et l’utiliser pour créer de meilleurs modèles et analyses.
Une solution simplifiée d’intégration de data rationalise également l’ingénierie data. Cela permet aux ingénieurs de se concentrer sur des projets critiques, par exemple l’optimisation de l’infrastructure de data d’une organisation ou la production de modèles prédictifs, au lieu de la construction et de l’entretien de pipelines de data complexes.
Mettre en œuvre l’ELT signifie également que les organisations peuvent combiner des data provenant de différents ensembles de data et dans différents formats. Il est également possible de compiler des data structurées, non structurées, liées ou non liées.
2. Réduction des taux de défaillance
Les flux de travail ELT déplacent les data vers leur destination de stockage avant leur transformation. Par conséquent, les processus d’extraction et de chargement sont indépendants de la transformation. Cette indépendance permet d’éviter les retards causés par le processus de transformation.
Bien que la couche de transformation puisse tout de même présenter des défaillances lors de la modification de modèles data en aval ou de schémas en amont, ces défaillances n’empêchent pas le chargement des data dans un data warehouse ou un data lake.
Au lieu de cela, une organisation peut continuer d’extraire et de charger des data, même lorsque les analystes réécrivent les transformations sur une base périodique. Comme les data sont arrivées à destination en ayant subi un minimum d’altération, elles représentent une source fiable, à jour et complète.
3. Flux de travail automatisés
Une organisation qui combine l’automatisation et l’ELT peut améliorer considérablement son flux de travail d’intégration de data.
Étant donné que l’extraction et le chargement automatisés renvoient des data brutes, il est possible d’utiliser l’ELT pour produire une sortie normalisée. Cela élimine le besoin de construire et d’entretenir en permanence les pipelines contenant des modèles data personnalisés. Cela permet également aux produits dérivés, comme les analyses basées sur un modèle, d’être générés et ajoutés sur la destination.
L’automatisation de l’extraction et du chargement élimine les tâches manuelles fastidieuses. Elle permet aux analystes de se concentrer sur l’analyse réelle des data afin d’obtenir des informations, plutôt que sur la collecte et la préparation des data.
4. Externalisation plus simple
Puisque le pipeline ETL peut produire des sorties normalisées et permet de modifier plus facilement le pipeline, il est plus simple d’externaliser l’intégration de vos data auprès de tiers.
Des plateformes comme Fivetran offrent une collecte de data fluide et les classent automatiquement en colonnes, en lignes et en tables. Les analystes peuvent obtenir des data récentes et organisées en quelques minutes. Elles mettent aussi à votre disposition une équipe d’ingénieurs et des connecteurs entièrement gérés afin d'entretenir vos pipelines à votre place.

L’externalisation est également une bonne option lorsqu’il s’agit de sécurité, confidentialité et conformité. Fivetran propose des solutions de chiffrement à chaque étape, telles que la capacité de hacher les data sensibles avant qu’elles n’atteignent leur destination, le contrôle complet de la gestion des data, ou des options de connexion sécurisées.
L’utilisation de telles plateformes pour la gestion de vos pipelines de data permet d’économiser du temps et de l'argent, puisque le recrutement d’une équipe d’ingénieurs est souvent plus onéreux.
5. Évolutivité flexible
Les besoins en matière de data des organisations évoluent constamment en fonction des activités, du marché et des relations client. Lorsque les charges de traitement de data augmentent, les plateformes automatisées qui exploitent des data warehouses cloud peuvent effectuer une mise à l’échelle automatique en quelques minutes ou quelques heures.
Dans l’ETL, l’évolutivité est bien plus complexe et beaucoup plus chronophage, car il est nécessaire de commander du matériel neuf, de l’installer et de le configurer.
En fonction de vos besoins en matière de data, vous pouvez également réduire les capacités de traitement des data et du data warehouse. Plutôt que de désinstaller et de démonter du matériel physique, une plateforme basée sur le cloud, comme Fivetran, vous permet de modifier vos pipelines en l'espace de quelques minutes.
L’évolutivité est également plus simple lorsque votre plateforme d’intégration de data prend en charge les intégrations avec vos sources de data.
6. Prise en charge de la transformation SQL
Dans un pipeline ELT, les transformations sont effectuées dans l’environnement de data warehouse.
Il n’y a plus besoin de concevoir des transformations sur des interfaces par glisser-déposer, d’écrire des modifications à l’aide de langages de script comme Python ou de construire des orchestrations complexes entre des sources de data disparates.
Au lieu de cela, vous pouvez écrire des transformations en SQL, le langage natif de la plupart des analystes. L’intégration de data a connu une transformation en passant d’une activité centrée sur l’ingénieur ou l’informatique à une activité dans laquelle les analystes peuvent directement et facilement exploiter les data.
Donner aux analystes la possibilité de transformer les data selon leurs besoins et d’obtenir des informations précieuses peut faciliter les décisions commerciales majeures, améliorer la résolution de problèmes et mieux satisfaire les besoins des clients.
ETL vs ELT : différences et comparaison
Le tableau suivant résume les différences entre l’ETL et l’ELT :
Il existe certains cas où il est toujours préférable d’utiliser l’ETL, et non l’ELT. Cela comprend spécifiquement les cas où :
- Les modèles data souhaités sont bien connus et il est peu probable qu’ils soient modifiés rapidement. Cela est particulièrement vrai lorsqu’une organisation construit et entretient des systèmes qui génèrent des data sources.
- Il existe des exigences strictes en matière de sécurité et de conformité réglementaire concernant les data. Elles ne doivent jamais être stockées dans un emplacement à risque.
Ces conditions ont tendance à être caractéristiques des très grandes entreprises et organisations spécialisées dans les produits Software-as-a-Service (SaaS).
Dans de tels cas, il peut être judicieux d’utiliser l’ELT pour l’intégration de data avec des produits SaaS tiers tout en conservant l’ETL pour intégrer les sources de data internes et propriétaires.
Essayer l’ELT gratuitement
L’ETL et l’ELT sont deux processus robustes d’intégration de data, avec leurs propres cas d’utilisation types. Cependant, à l’heure actuelle, l’ELT représente clairement la meilleure option pour la grande majorité des organisations. Vous souhaitez accéder plus rapidement et plus simplement aux data client et entreprise ? L’ELT est le moyen d’y parvenir.
L’ELT permet l’automatisation, l’externalisation et l’intégration avec des tiers. Ces fonctionnalités font gagner du temps et de l’argent aux organisations, tout en offrant aux analystes des informations pertinentes.
Une plateforme d’intégration de data basée sur le cloud comme Fivetran constitue la solution idéale pour mettre en œuvre des pipelines de data sécurisés dans tous les secteurs. Notre outil vous aide à rassembler les data de toutes les databases et applications que vous utilisez, ainsi qu’à les réunir dans une destination centralisée.
Si vous n’avez pas encore fait votre choix, n'hésitez pas à essayer ces deux options. Le forfait gratuit de Fivetran, qui comprend des modèles de data compatibles avec dbt Core, vous permet d’essayer l’ELT gratuitement.
[CTA_MODULE]
Articles associés
Commencer gratuitement
Rejoignez les milliers d’entreprises qui utilisent Fivetran pour centraliser et transformer leur data.









