3 ways Fivetran uses AI internally


Like many companies, Fivetran has recently piloted a number of projects and internal tools using AI. AI offers the potential to augment or accelerate a huge range of day-to-day business tasks, including better understanding and prioritizing customer requests, surfacing trends across multiple business units, and automating customer communications.
The key to delivering value using AI is to ensure that it has access to quality data and a data infrastructure capable of providing it.
[CTA_MODULE]
Don’t confuse “AI models” with “data modeling”
Before we start, we should clarify an important semantic difference between “AI models” — tools created by combining data with algorithms to perform any number of tasks — and “data modeling” — using tools like dbt to organize and define how raw data is used to represent real-world concepts, metrics, and relationships.
Where AI projects start going wrong
When teams start building with AI, they tend to pull data ad hoc from source systems, shape it for a specific use case, plug it into an AI model, and generate insights or automations. This can quickly lead to a useful technology demonstrator.
But as you scale beyond one-off pilots and move toward systematically embedding AI in company workflows, several data problems emerge. Each tool or team might define “customer” or “revenue” slightly differently. You might experience “rogue analytics,” with different teams separately transforming the same data for the same purposes, duplicating data while introducing incompatibility and confusion. The consequence is that metrics stop aligning across teams, while costs climb from repeatedly extracting and reprocessing the same data.
These are longstanding problems with data, but AI amplifies the consequences. As applications, systems, and workflows become increasingly automated or augmented by AI, the consequences of poor data operations only grow.
What actually makes AI work
For us, the biggest unlock wasn’t using a better AI model or a cleverer prompt, although advances in both have certainly made things more capable. It was the fact that all of our tools sit on top of a well-designed, centralized data repository.
That means the data is already ingested from source systems, core entities are defined consistently within our semantic layer, and transformations are built collaboratively, version-controlled, and executed only as needed. The result is data that can be reliably reused across teams, without each team redefining it for themselves. Crucially, the relationships between systems are already resolved. The AI doesn't need to figure out that a Zendesk ticket and a Gong call belong to the same customer, as that context is cataloged already.
This is all upstream of the AI layer, and a function of how the data itself is integrated, structured, and maintained. This data foundation ensures that AI projects don’t start from raw source data, but a well-understood business context.
3 examples of what AI has enabled for us
At Fivetran, we’re strong believers in dogfooding. The same connectors, dbt models, and pipelines we build for our customers power our own internal data platform. Our data infrastructure is not only centralized but continuously maintained, reliable, and designed to scale as new use cases emerge.
Customer request management
We built an internal tool to better capture, relate, and prioritize customer-requested product features, improving a process that previously lived across disjointed systems. This type of bespoke app would have been impossible to justify building and maintaining before the AI revolution.
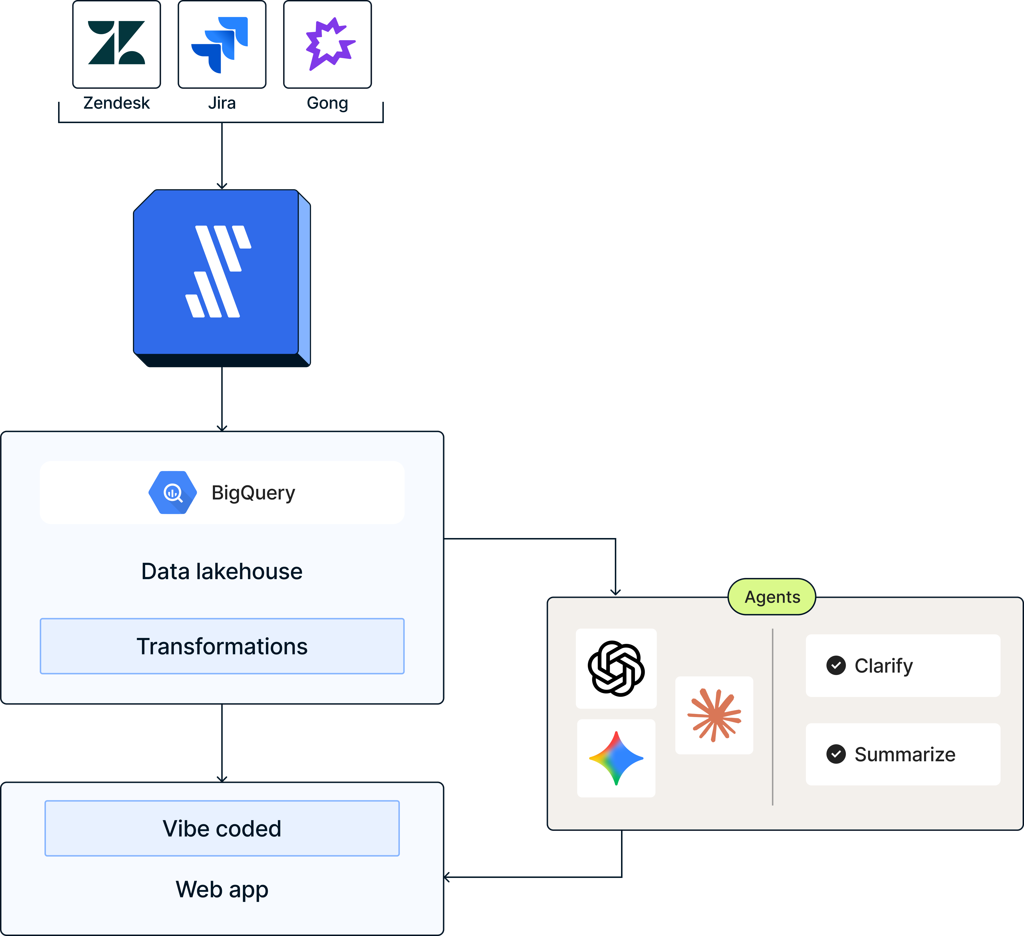
Customer feature requests come from Zendesk, while tickets come from Jira. Additional details for each account come from Salesforce, while Google Sheets contains some of Fivetran’s organizational context. We use Fivetran to integrate the data into our BigQuery lakehouse, where we transform it, then move it into a Postgres database that serves as the backend of this AI-powered web app, which we vibe coded, using AI as a copilot to free up engineering resources.

The app uses multiple agents. One AI agent reviews all feature requests, surfacing similar prior requests for deduplication and product feature shaping.

Another AI agent a drafts a customer service response, from which a user can make edits and post the portal without leaving the app. This is made possible by the data already in the warehouse: historical request patterns, customer and service context (use case, segment, usage, tier), engineering backlogs, and outcomes from prior requests. More details can be found in this blog.

The result has been significant time savings. Instead of building a narrow tool that evaluates requests in isolation, we built one that understands them in full context. We see faster customer response time and less time from product feature identification to delivery. In one recent case, a new connector feature was delivered in 4 days.
Service visibility and decision-making
Another internal application we built is a dashboard giving teams a unified view of performance across our connector services, support, product, engineering, sales, and operations.

These tools are used to make real decisions every day, relying on a steady, consistent stream of metrics. Since our data lakehouse centralizes and models Zendesk customer support data, Gong call data, and Jira project tickets, we can layer intelligence in the form of agents in a custom web app on top — surfacing anomalies, identifying patterns, and accelerating decision-making. Without that foundation, this wouldn’t be feasible at scale or trustworthy enough to act on.
Product change notification tooling
One of our earliest successful AI workflows automated and streamlined how we communicate new product features and changes to our customers. A simple online form triggers the creation of standardized tracking tickets, along with an automated drafting process to ensure a consistent tone and approach across every message. These tickets are orchestrated by an Okta Workflow and ultimately a human reviews the final result before any emails are sent.

A flexible audience generation layer, based on Fivetran usage and customer data from our production database, ensures the right customers are targeted — while respecting communication preferences and compliance rules — something that was only possible because the underlying data was already centralized and structured in our warehouse.
As a result, we’re now handling more notifications than ever with the same team, with an estimated 50% reduction in time per message.
The compounding effect of a centralized data foundation
Data infrastructure and management choices compound over time. Without a centralized data foundation, each new tool risks rebuilding its logic, each team creates its own definitions, and costs and complexity grow with every project.
With a centralized data foundation using a modern data lake, work done once benefits all applications and tools built after it. Definitions stay consistent. New use cases are faster and cheaper to build. It turns data from something you repeatedly process into something you continuously build on.
In addition, centralization prevents duplicated data processing and engineering effort. Every initiative should be built on top of a common data repository. A centralized data platform ensures that data is a shared asset that every tool, dashboard, and AI system can build on.
A simple principle for the AI era
As more teams invest in AI, we’ve found one question surprisingly clarifying:
Before building a new AI-powered tool, ask: is the data already centralized, standardized, and ready to use?
If not, then data is the real bottleneck, not the model, prompt, or any tooling.
AI will continue to evolve rapidly. Models will improve, tooling will get easier, and new use cases will emerge. But the companies that get the most value from AI won’t necessarily be the ones with the fanciest AI setup, but the ones with the strongest data foundations — ready for whatever AI best practices emerge next.
AI isn’t magic, but leverage. Leverage only works when it’s applied to something solid.
[CTA_MODULE]
Verwandte Beiträge
Kostenlos starten
Schließen auch Sie sich den Tausenden von Unternehmen an, die ihre Daten mithilfe von Fivetran zentralisieren und transformieren.









