Der Benchmark-Bericht zur Unternehmensdateninfrastruktur 2026


Unternehmen geben durchschnittlich 29,3 Millionen $ pro Jahr für Datenprogramme aus — und 2,2 Millionen $ davon werden für den Betrieb von Datenpipelines verwendet.
Daten sind zu einem der größten Posten in den Technologiebudgets von Unternehmen geworden, was auf die Notwendigkeit zurückzuführen ist, Analysen, KI und Entscheidungen in Echtzeit zu unterstützen. Doch trotz beispielloser Investitionen haben die meisten Unternehmen Schwierigkeiten, ihre Ausgaben in Wirkung umzusetzen. Pipelineausfälle, Ausfallzeiten und manuelle Abläufe verschlingen jedes Jahr stillschweigend Millionen von Dollar. Dadurch wird die Produktivität beeinträchtigt, KI-Initiativen verzögert und die Rendite begrenzt.
Um den wahren Zustand der Unternehmensdateninfrastruktur zu verstehen, befragte Fivetran mehr als 500 hochrangige Daten- und Technologieführer von Unternehmen mit über 5.000 Mitarbeitern aus verschiedenen Branchen und globalen Regionen. Die Ergebnisse zeigen, dass das Problem nicht in zu geringen Investitionen liegt, sondern in der Architektur. Die meisten Unternehmen verlassen sich weiterhin auf eine geschlossene, spröde und arbeitsintensive Datenintegration, die nicht mit wachsenden Datenmengen, Quellen oder KI-gesteuerten Anwendungsfällen skaliert werden kann.
Da Umgebungen immer komplexer werden, brechen fragmentierte und eng miteinander verbundene Systeme häufiger ab, erfordern ständiges menschliches Eingreifen und schränken den Zugriff auf Daten zwischen Teams ein. Das Ergebnis ist eine immer größer werdende Kluft zwischen Unternehmen, die Datenintegration als betriebliche Belastung betrachten, und solchen, die sie als grundlegende architektonische Ebene betrachten, die auf Offenheit, Interoperabilität und vertrauenswürdigen Zugriff ausgelegt ist.
In diesem Bericht werden die tatsächlichen Kosten von Datenoperationen anhand von Ausgaben, Zuverlässigkeit, technischem Aufwand und ROI verglichen. Er zeigt, wie architektonische Entscheidungen auf der Integrationsebene darüber entscheiden, ob Dateninvestitionen Analysen und KI beschleunigen oder ihr Potenzial stillschweigend ausschöpfen.
[CTA_MODUL]
Zusammenfassung
Das jährliche Datenbudget liegt im Durchschnitt bei über 29 Millionen US-Dollar pro Unternehmen, und ein erheblicher Teil dieser Ausgaben geht durch Pipeline-Ausfälle, Ausfallzeiten und die Anzahl der Mitarbeiter verloren, die für die Wartung immer komplexer werdender Datenumgebungen erforderlich sind.
Im Folgenden finden Sie die 3 wichtigsten Erkenntnisse aus der diesjährigen Studie:
1. Operative Ineffizienz — nicht mangelnde Investitionen — bremst Analysen und KI in großem Maßstab aus.
Datenteams widmen 53% der technischen Zeit der Wartung, wobei 2,2 Millionen $ pro Jahr von Vollzeitingenieuren für die Wartung der Pipeline ausgegeben werden. Ältere und selbstgebaute Rohrleitungen brechen 30-47% häufiger, was zu 60 Stunden Ausfallzeiten pro Monat führt. Datenexperten schätzen die geschäftlichen Auswirkungen von Ausfallzeiten auf 49.600$ pro Stunde. Dadurch sind jeden Monat fast 3 Millionen $ an potenziellem Geschäftswert gefährdet, oder mehr als 36 Millionen $ pro Jahr. Diese Auswirkungen sind in Umgebungen am stärksten ausgeprägt, in denen die Pipelines eng miteinander verbunden sind und bei deren Skalierung häufig manuelle Eingriffe erforderlich sind.
2. Die Ausgaben für die Integration sind höher als erwartet, der ROI bleibt jedoch niedrig.
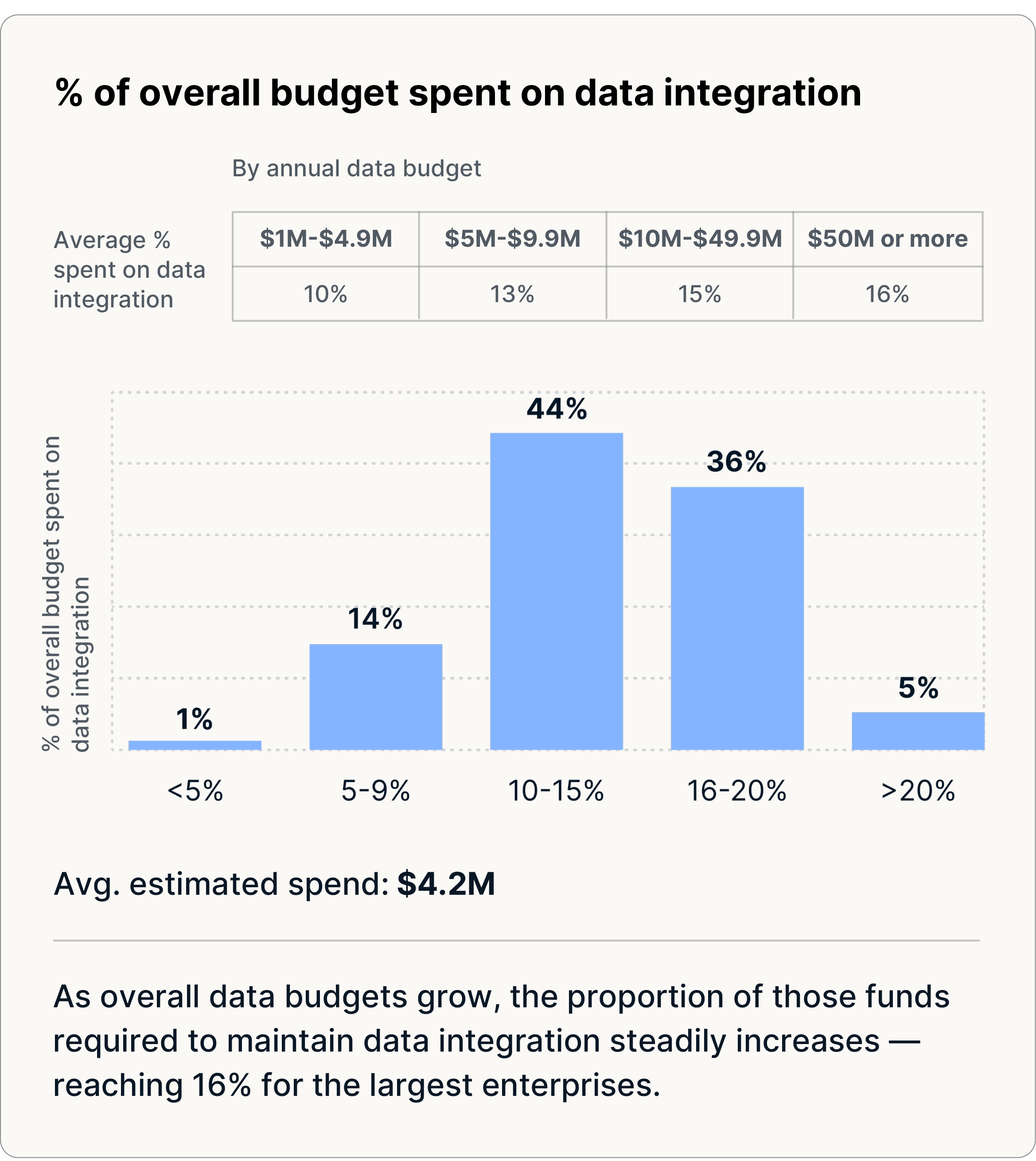
Unternehmen investieren 14% ihres gesamten Datenbudgets (~4,2 Millionen $) in die Datenintegration, doch nur 27% der Unternehmen geben an, dass ihre Dateninvestitionen die ROI-Erwartungen übertreffen. Ein Großteil dieser Ausgaben entfällt auf manuelle, fragmentierte Integrationsansätze, deren Verwaltung angesichts der wachsenden Datenmengen, Quellen und Anwendungsfälle immer schwieriger wird.
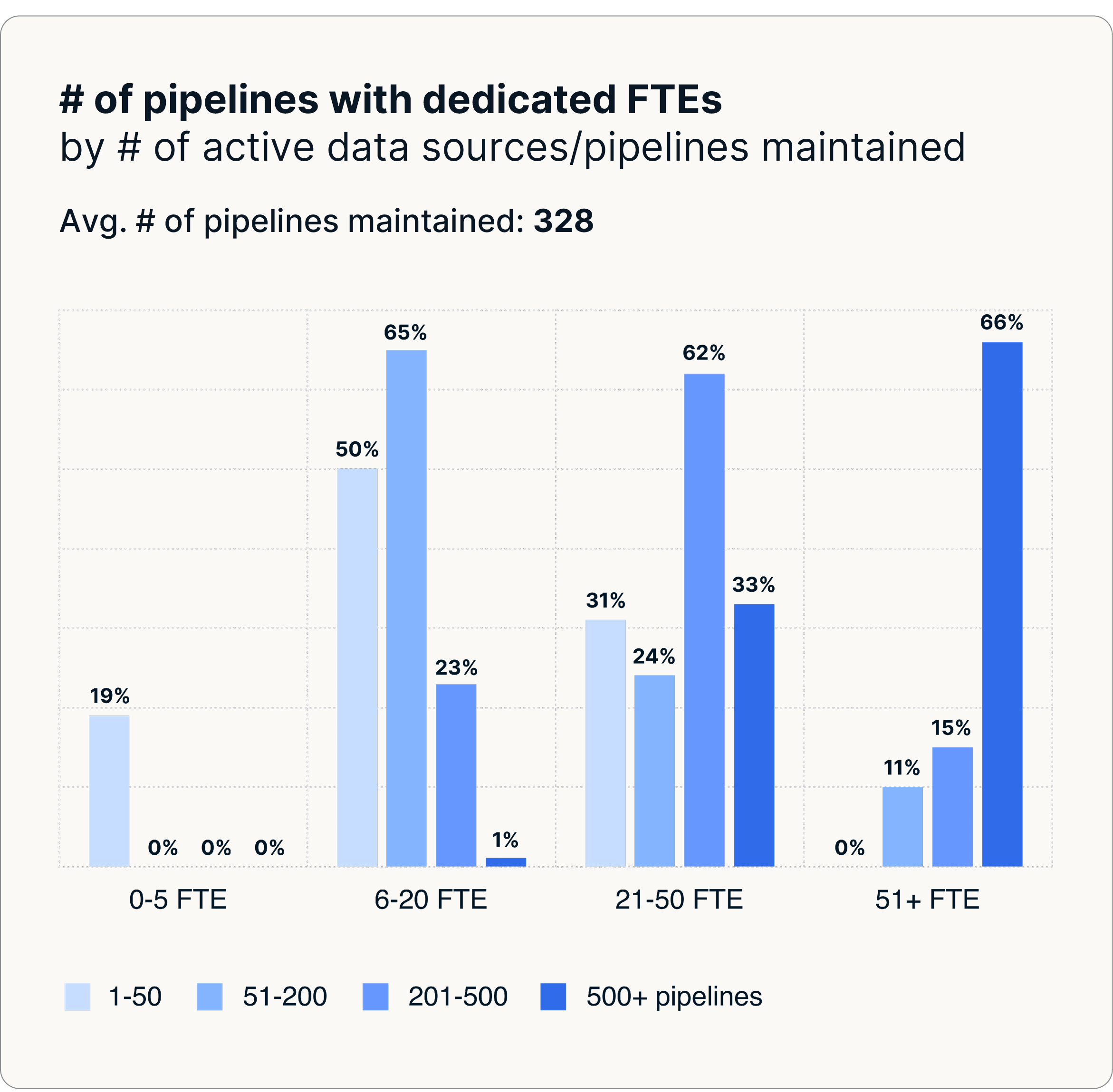
Mit durchschnittlich 328 Pipelines und bis zu 35-60 Vollzeitingenieuren, die diese verwalten, müssen Unternehmen aufgrund manueller, fragmentierter Prozesse, die sich nur schwer effizient skalieren lassen, höhere Kosten tragen.
3. Die Modernisierung der Pipeline sorgt für niedrigere Kosten, eine höhere Zuverlässigkeit und einen höheren ROI.
Durch die Einführung standardisierter und vollständig verwalteter Pipelines sichern Unternehmen die Zuverlässigkeit und Kosteneffizienz, die für den Aufbau KI-fähiger Umgebungen erforderlich sind — eine leistungsstarke Kohorte, die schnellere Wiederherstellungszeiten bietet und die Wahrscheinlichkeit, dass sie die ROI-Ziele übertrifft, fast doppelt so hoch ist (45% gegenüber 27%). Wenn der Wartungsaufwand sinkt, können die Teams ihre Anstrengungen auf Analysen, KI, Governance und andere Initiativen konzentrieren, die auf einen konsistenten, gemeinsamen und vertrauenswürdigen Zugriff auf zuverlässige Daten angewiesen sind.
Kapitel 1: Leistungsschwache Pipelines schränken den ROI ein
Die Investitionen von Unternehmen in Daten haben neue Höhen erreicht, was auf ehrgeizige Pläne für KI, Echtzeitanalysen und personalisierte Kundenerlebnisse zurückzuführen ist. Im Durchschnitt geben große Unternehmen heute jährlich 29,3 Millionen US-Dollar für Daten aus, was die zentrale Rolle widerspiegelt, die Daten für Wettbewerbsfähigkeit und Innovation spielen. Trotz dieser Investitionen geben 73 Prozent der Unternehmen an, dass ihre Dateninitiativen hinter den Erwartungen zurückbleiben.
Ein erheblicher Teil dieser Ausgaben steht in direktem Zusammenhang mit der Datenintegration, darunter:
- 14% des gesamten Datenbudgets (~4,2 Millionen $) — einschließlich Tools, Infrastruktur und internem Personal für die Übertragung, Erfassung und Vorbereitung von Daten
- Über 500.000$ pro Monat für Cloud-Ingest- und Rechenkosten
- 2,2 Millionen $ pro Jahr für technische Arbeit, die speziell für die Wartung von Pipelines ausgegeben werden — eine Belastung, die bei Teams, die auf DIY- oder Legacy-Datenintegration angewiesen sind, deutlich höher ist
Diese Investitionen spiegeln die zunehmend dringenden Geschäftsprioritäten wider. Teams verlassen sich auf Daten, um KI-Modelle zu unterstützen, personalisierte Kundenerlebnisse zu bieten und Entscheidungen in Echtzeit zu unterstützen. Betriebliche Engpässe, insbesondere fragile Pipelines und arbeitsintensive Arbeitsabläufe, verlangsamen jedoch weiterhin den Fortschritt. Mit den steigenden Erwartungen steigt auch der Druck, die Zuverlässigkeit und Effizienz der bereits vorhandenen Infrastruktur zu verbessern.
73% der Dateninitiativen in Unternehmen erfüllen trotz jährlicher Datenausgaben in Höhe von 29,3 Millionen US-Dollar nicht die Erwartungen.
KI-Ambitionen übertreffen Datenoperationen
Während die Investitionen steigen, geben fast 62 Prozent der Unternehmen an, dass ihre Datenreife „niedrig“ ist, was zeigt, wie weit Unternehmen noch gehen müssen, um einen vollständigen Self-Service und prädiktive Analysen zu entwickeln.
Unsere Ergebnisse zeigen, dass die wichtigsten betrieblichen Fähigkeiten — Zuverlässigkeit, Automatisierung, Beobachtbarkeit und standardisierte Integration — nicht mit den strategischen Ambitionen Schritt gehalten haben. Unternehmen müssen die KI skalieren, indem sie den Datenzugriff demokratisieren und die Entscheidungslatenz reduzieren. Die zugrunde liegenden Systeme sind jedoch oft zu manuell oder zu spröde, um diese Ziele zu unterstützen.
Zu den Schmerzpunkten gehören:
- Pipeline-Unterbrechungen und Ausfallzeiten beeinträchtigen die Aktualität der Daten
- Wartungsanforderungen verbrauchen mehr als die Hälfte der technischen Ressourcen
- Ältere Systeme und Heimwerkersysteme führen zu höheren Kosten und langsameren Wiederherstellungszeiten
Diese Herausforderungen nehmen in großem Umfang exponentiell zu. Große Unternehmen haben im Durchschnitt 328 bis über 400 Pipelines, wodurch schrittweise Reparaturen und manuelle Prozesse nicht nachhaltig sind und Teams eher an die Wartung der Pipeline als an innovative Projekte gebunden sind.
Unternehmen, die ihre Datenintegrationsebene mit automatisierten, vollständig verwalteten Pipelines modernisiert haben, setzen zunehmend auf KI und fortschrittliche Analysen. Unternehmen, die sich immer noch auf veraltete oder selbstgemachte Ansätze verlassen, geraten mit einer Infrastruktur, die nicht skaliert werden kann, ins Hintertreffen.
62% der Unternehmen berichten immer noch von einer geringen Datenreife, da fragile Pipelines und manuelle Abläufe 53% der Entwicklungszeit in Anspruch nehmen.
[CTA_MODULE]
Kapitel 2: Benchmarking der Kosten fragiler, wartungsintensiver Pipelines
Trotz rekordhoher Dateninvestitionen ist die Grundlage für Unternehmensanalysen und KI nach wie vor schwach. Die meisten Unternehmen verlassen sich auf selbst entwickelte Pipelines, die immer komplexer, schwieriger zu skalieren und teuer zu warten sind — was die Produktivität, Zuverlässigkeit und strategische Umsetzung beeinträchtigt.
Die folgenden Benchmarks verdeutlichen, wie stark sich die Fragilität der Pipeline auf Kosten, Betrieb und Geschäftsergebnisse auswirkt.
Zuverlässigkeit und Ausfallzeiten der Pipeline
Der Betrieb von Unternehmensdaten versagt mit einer Geschwindigkeit, die den Betrieb erheblich beeinträchtigt — obwohl viele Unternehmen mit der Operationalisierung von Daten für KI noch am Anfang stehen.
Erfahrung von Organisationen:
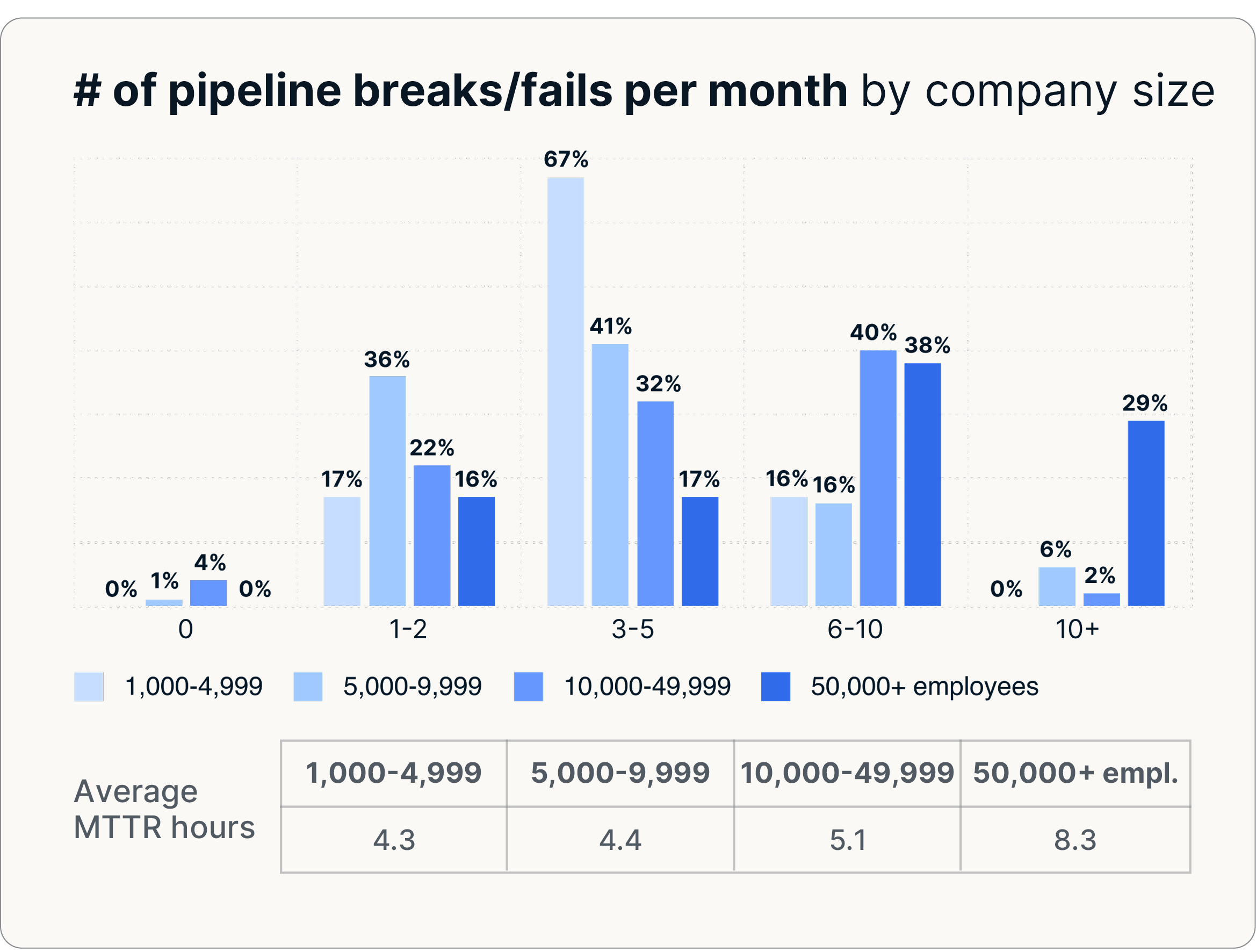
- Durchschnittlich 4,7 Pipeline-Pausen pro Monat
- 60,4 Stunden Ausfallzeit jeden Monat
- Bis zu 8,3 Pausen pro Monat in den größten Unternehmen
Obwohl die Ambitionen im Bereich KI hoch sind, berichtet nur eine Minderheit der Unternehmen von prädiktiven oder KI-Modellen in der Produktion, und Lücken in Bezug auf Datenverfügbarkeit und Zuverlässigkeit verzögern weiterhin Analysen und KI-Bereitstellung.
Ausfallzeiten sind kostspielig und eskalieren mit der Größenordnung:
- 49.600$ pro Stunde geschätzte Auswirkungen von Datenausfällen auf das Geschäft
- Steigend zu 75.200$ pro Stunde der Ausfallzeiten in großen Unternehmen
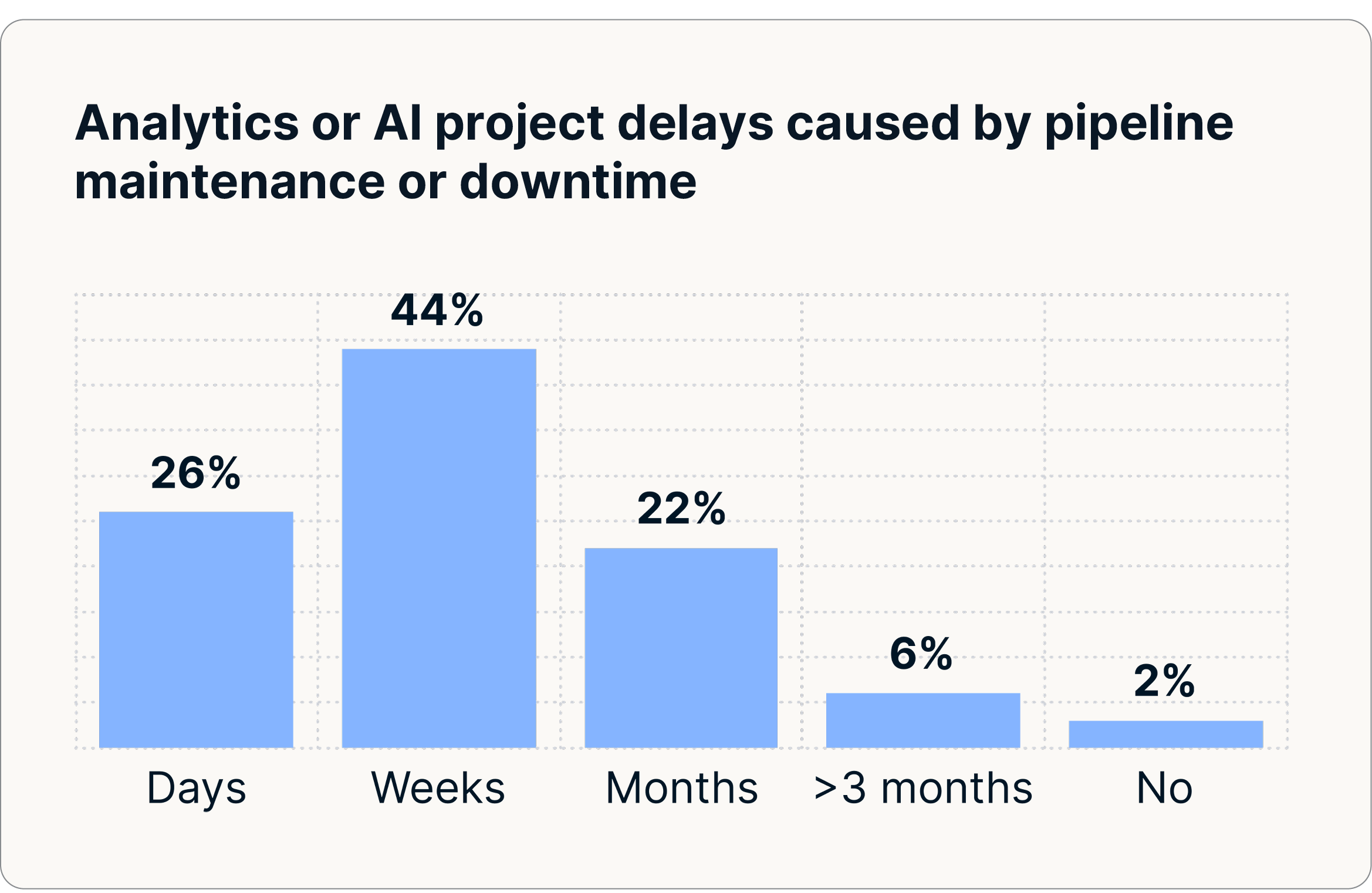
Diese Störungen verschlechtern die KI-Modelle, beeinträchtigen die Genauigkeit des Dashboards und verlangsamen die Entscheidungsfindung. Branchenführer berichten, dass eine unzuverlässige Datenintegration Analysen und KI-Initiativen routinemäßig verzögert und zu Ineffizienzen führt, die sich auf das gesamte Unternehmen auswirken. Fast 30% der Unternehmen sehen sich aufgrund von Problemen mit der Pipeline-Wartung oder Ausfallzeiten mit Verzögerungen von mindestens einem Monat bei der Bereitstellung von Analysen und KI-Projekten konfrontiert.
Entwicklungszeit, Mitarbeiterzahl und versteckte Arbeitskosten
Die Zuverlässigkeit der Datenintegration zeigt sich am deutlichsten darin, wie viel Aufwand Teams aufwenden, um die Pipelines am Laufen zu halten. Wenn Integrationen nicht zuverlässig sind, verschiebt sich die Entwicklungszeit von der Innovation zur Wartung.
Organisationen berichten:
- 53% der Engineering-Zeit für die Wartung der Pipeline ausgegeben
- 35 Vollzeitingenieure Verwaltung von durchschnittlich 328 Pipelines
- Über 50 Vollzeitingenieure Verwaltung von über 500 Pipelines in großen Unternehmen
Legacy- und DIY-Integrationsansätze verschlechtern die Betriebslast:
- 30-47% häufigere Pipeline-Unterbrechungen
- 2-4 zusätzliche Stunden für Reparaturen erforderlich
- 25% höhere Kosten pro Pipeline (alte Version 1.900$ gegenüber vollständig verwaltetem ELT 1.600$)
Ein hohes Verhältnis von Vollzeitingenieuren zu Pipelines, intensive manuelle Eingriffe und begrenzte Automatisierung reduzieren die betriebliche Agilität und sorgen dafür, dass die Entwicklungsteams reaktiv sind.
Auswirkungen von Integrationsfehlern auf das Geschäft
Eine unzuverlässige Datenintegration wirkt sich direkt auf die Unternehmensleistung aus:
- 97% der Unternehmen melden Störungen bei KI- oder Analyseinitiativen
- 70% der Unternehmen berichten von negativen Auswirkungen auf Projekte zur Kundenpersonalisierung oder Kostensenkung
- 36 Millionen $ bis 54 Millionen $ geschätzte jährliche Geschäftsauswirkungen (d. h. Umsatzeinbußen) aufgrund des fehlenden zeitnahen Zugriffs auf aktuelle Daten
Wenn Unternehmen auf veraltete oder unvollständige Daten angewiesen sind, KI-Modelle schlechter abschneiden oder nicht eingesetzt werden können, Personalisierung an Genauigkeit oder Effektivität verliert, strategische Programme aufgrund von Unsicherheit oder mangelnden vertrauenswürdigen Erkenntnissen langsamer werden und Datenteams in die reaktive Brandbekämpfung verwickelt werden, anstatt Innovationen voranzutreiben.
Die versteckten Kosten von Datenintegrationsfehlern: 2,2 Millionen US-Dollar an jährlicher Wartung, über 60 Stunden Ausfallzeit pro Monat, verzögerte KI-Initiativen und verringerte Innovationskapazität.
Kapitel 3: Die Vorteile einer Modernisierung des Datenmanagements
Nach Jahren inkrementeller Korrekturen, steigender technischer Schulden und steigendem Wartungsaufwand erkennen Unternehmen, dass herkömmliche und selbstgemachte Integrationsansätze moderne Datenmanagementanforderungen nicht mehr erfüllen können.
Im Gegensatz dazu hat sich ein vollständig verwaltetes und automatisiertes ELT als Grundlage für KI herausgestellt. Es senkt die Gesamtbetriebskosten, stabilisiert den Datenbetrieb, gibt Datenteams die Möglichkeit, sich auf Innovationen zu konzentrieren, und beschleunigt die Amortisierungszeit.
Niedrigere Kosten und verbesserte Zuverlässigkeit
Der Kostenunterschied zwischen herkömmlichen und modernen Datenintegrationsansätzen ist erheblich und wird immer größer. Unternehmen, die veraltetes ETL verwenden, geben 1.900$ pro Pipeline aus, verglichen mit 1.600$ bei vollständig verwaltetem ETL. Der Unterschied summiert sich schnell auf Unternehmensebene, wo Hunderte oder sogar Tausende von Pipelines gewartet werden müssen.
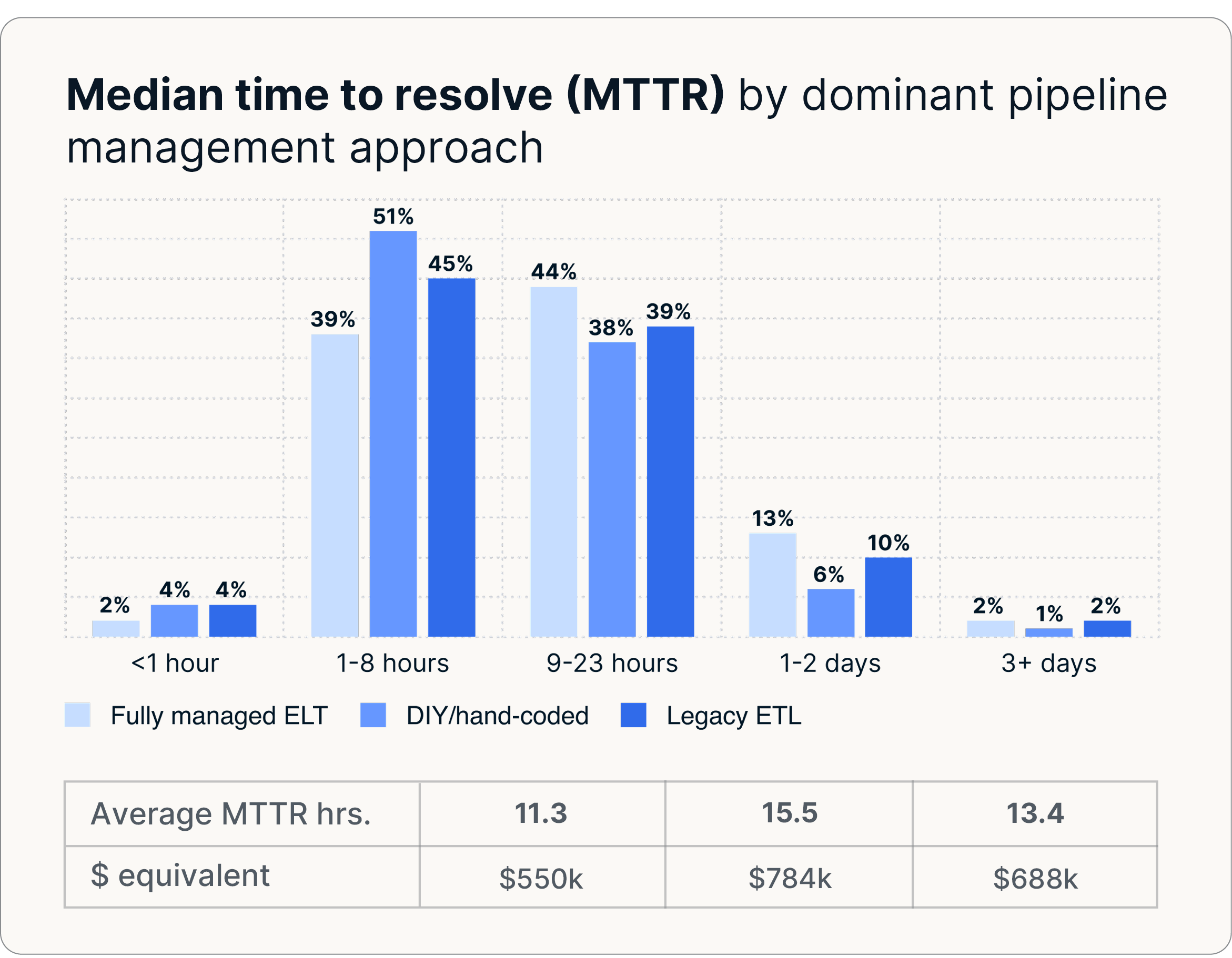
Legacy-Systeme gehen auch viel häufiger kaputt. Unternehmen, die sich auf benutzerdefinierte Skripts oder selbst entwickelte ETL-Lösungen verlassen, berichten von 30-47% mehr Pipeline-Ausfällen und längeren Wiederherstellungszeiten, wobei die Behebung von Vorfällen in der Regel 13—16 Stunden dauert. Im Gegensatz dazu reduzieren Unternehmen, die mit vollständig verwaltetem ELT modernisieren, um KI-fähig zu sein, die Wiederherstellungszeiten auf nur 11 Stunden. Durch die Reduzierung der Ausfallhäufigkeit und der Zeit bis zur Wiederherstellung verbessert ein vollständig verwaltetes ELT die betriebliche Vorhersagbarkeit und senkt das Risiko erheblich.
Das Ergebnis ist eine messbare Verbesserung der Verfügbarkeit und Zuverlässigkeit. Dank weniger Ausfällen und schnellerer Wiederherstellung haben nachgelagerte Analyse- und KI-Systeme einen konsistenteren Zugriff auf aktuelle Daten. Techniker können sich auf ihre Pipelines verlassen, Geschäftsanwender können ihren Daten vertrauen, und Führungskräfte können sich auf aktuelle Erkenntnisse verlassen, um Entscheidungen zu treffen.
Dank automatisierter Datenintegration konnten pro Pipeline jährlich 300$ eingespart werden — eine sechsstellige Einsparung auf Unternehmensebene.
Rückgewinnung technischer Kapazitäten
Eine der transformativsten Auswirkungen der Modernisierung ist die veränderte Art und Weise, wie Datenteams ihre Zeit einteilen. In älteren Umgebungen verbringen Entwicklungsteams 53% ihrer Zeit mit der Wartung von Pipelines und reaktivem Support. Moderne Datenintegration verdoppelt die Zeit, die Teams zur Verfügung haben, um an strategischen Initiativen zu arbeiten, die den Geschäftswert steigern.
Mit automatisierten, vollständig verwalteten Pipelines:
- Techniker verbringen weniger Zeit mit der Diagnose von Ausfällen und mehr Zeit mit der Unterstützung des Unternehmens
- KI-Initiativen und prädiktive Modellierung schreiten schneller voran
- Governance-, Compliance- und Echtzeitanalyseprogramme gewinnen an Dynamik
- Der Self-Service-Datenzugriff wird breiter und sicherer und reduziert die Abhängigkeit von schwer zu findenden Experten
Das Ersetzen spröder benutzerdefinierter Skripte durch eine standardisierte, automatisierte Datenintegration reduziert die Abhängigkeit von spezialisiertem Stammeswissen. Anstatt sich auf Fachexperten zu verlassen, um Fehler zu beheben oder komplexe Arbeitsabläufe aufrechtzuerhalten, arbeiten die Teams nach einem vorhersehbaren Betriebsmodell — das verbessert die Agilität und ermöglicht Skalierung ohne proportionales Mitarbeiterwachstum.
Wenn der betriebliche Aufwand sinkt, leiten Unternehmen ihre Kapazitäten auf höherwertige Initiativen um. Leistungsstarke Datenteams berichten, dass sie sich zunehmend auf folgende Themen konzentrieren:
- Prädiktive Analytik (69%)
- Selfservice-Analysen (65%)
- Unternehmensführung und Compliance (59%)
- KI-Innovation (56%)
Höherer ROI durch zuverlässigere Daten
Investitionen in vollständig verwaltete, automatisierte ELT sorgen für messbare Geschäftsrenditen. Durch die Schaffung der stabilen Grundlage, die für KI-fähige Umgebungen erforderlich ist, ist die Wahrscheinlichkeit, dass Unternehmen, die ein vollständig verwaltetes ELT verwenden, ihre ROI-Ziele fast doppelt so hoch (45% gegenüber 27%), was den Zusammenhang zwischen betrieblicher Disziplin und finanzieller Leistung verstärkt.
Drei Faktoren treiben diesen Verstärkungseffekt an:
- Wiederholbarkeit: Automatisierte Pipelines reduzieren Variabilität und minimieren Fehler, wodurch eine konsistente und standardisierte Datenbereitstellung gewährleistet wird. Skalierbarkeit: Vollständig verwaltetes ELT skaliert mit
- Skalierbarkeit: Vollständig verwaltetes ELT skaliert mit Datenmengen und Quellen ohne zusätzlichen technischen Aufwand
- Zuverlässigkeit: Vorhersagbare Datenflüsse verbessern die Qualität der Erkenntnisse, stärken die Modellleistung und beschleunigen die Entscheidungsfindung
Unternehmen mit ausgereiften Datenabläufen weisen auch eine höhere betriebliche Effektivität auf, darunter eine stärkere Einführung von Prognosemodellen, umfassendere Self-Service-Analysen und eine engere Abstimmung zwischen Datenteams und Geschäftsbeteiligten. Durch die Reduzierung des Zeitaufwands für die Infrastruktur erschließen Unternehmen die Kapazitäten, die für schnelle und skalierbare Innovationen erforderlich sind.
45% übertreffen die ROI-Ziele mit vollständig verwaltetem ELT gegenüber 27%, die DIY- oder Legacy-Ansätze verwenden.
[CTA_MODULE]
Wichtige Implikationen für Datenführer
Unternehmen, die ihren Datenbetrieb modernisieren, übertreffen ihre Mitbewerber in Bezug auf Kosteneffizienz, Zuverlässigkeit und KI-Bereitschaft.
Die Daten zeigen, dass die größten Vorteile nicht durch schrittweise Korrekturen erzielt werden, sondern durch die Abkehr von fragilen, wartungsintensiven Integrationen hin zu Betriebsmodellen, die einfacher zu verwalten, wiederzuverwenden und zu skalieren sind, wenn die Datenumgebungen wachsen. Auf der Grundlage dieses Benchmarks ist der Weg in die Zukunft klar. Um die Gesamtkosten der Daten zu senken, den ROI zu erhöhen und die KI-Bereitschaft zu beschleunigen, sollten Datenverantwortliche:
1. Bewerten Sie die Gesamtkosten ganzheitlich
Denken Sie über die Werkzeugkosten hinaus und berücksichtigen Sie die gesamte betriebliche Belastung der Datenintegration, einschließlich Entwicklungszeit, Ausfallzeiten, Reparaturzyklen und nachgelagerter Geschäftsauswirkungen. Versteckte Kosten — wie etwa 49.600$ pro Stunde für Ausfallzeiten und 2,2 Millionen $ an jährlichen Wartungsausgaben — überwiegen oft den Preis des Tools selbst, sodass herkömmliche und selbstgemachte Lösungen weitaus teurer sind, als sie scheinen.
2. Priorisieren Sie die Automatisierung, um den Wartungsaufwand zu reduzieren
Da 53% der Entwicklungszeit für die Wartung der Integration aufgewendet werden, ist Automatisierung der schnellste Weg, um Kapazität zurückzugewinnen. Durch die Reduzierung manueller Eingriffe wird die Zeit, die für höherwertige technische Arbeiten zur Verfügung steht, fast verdoppelt, ohne die Mitarbeiterzahl zu erhöhen.
3. Standardisieren Sie die Datenintegration, um das Betriebsrisiko zu reduzieren
Fragmentierte, benutzerdefinierte Integrationen führen zu Variabilität und Risiken, wenn Datenumgebungen erweitert werden. Herkömmliche und selbstgemachte Ansätze gehen 30-47% häufiger kaputt und die Wartung kostet 25% mehr pro Pipeline. Die standardisierte Integration verbessert die Zuverlässigkeit, Konsistenz und Skalierbarkeit, wenn die Komplexität zunimmt.
4. Stärken Sie die Datengrundlagen, bevor Sie KI skalieren
KI-Initiativen hängen von frischen, konsistenten und gut verwalteten Daten ab. Ohne vorhersehbare Datenbereitstellung geraten selbst gut finanzierte KI-Programme ins Stocken oder schneiden unterdurchschnittlich ab. Der Aufbau einer starken Datengrundlage stellt sicher, dass KI-Investitionen in der Produktion zuverlässig unterstützt werden können.
5. Richten Sie die Ausgaben an den Geschäftsergebnissen aus — nicht an der Wartung der Infrastruktur
Verlagern Sie Investitionen weg von der Wartung spröder Systeme hin zu Plattformen, die die Analytik beschleunigen, die Datenqualität verbessern und die KI-Bereitschaft unterstützen. Durch die Einführung eines vollständig verwalteten ELT schaffen Unternehmen die zuverlässige Grundlage, die für KI-fähige Umgebungen erforderlich ist. Die Wahrscheinlichkeit, dass sie die ROI-Erwartungen übertreffen, ist fast doppelt so hoch. Dies zeigt, wie sich die betriebliche Reife im gesamten Datenökosystem verbessert.
Datenbudgets allein schaffen keinen Wert. Unternehmen, die Investitionen mit Integrationspraktiken kombinieren, die auf Skalierbarkeit, Betriebssicherheit und umfassenden Datenzugriff ausgelegt sind, erzielen einen höheren ROI, schnellere KI-Fortschritte und einen nachhaltigen Wettbewerbsvorteil.
Für Datenführer liegt die Chance auf der Hand: Verlagerung der Investitionen weg von fragilen, wartungsintensiven Integrationen und hin zu modernen Datengrundlagen, die für zuverlässige Analysen und skalierbare KI konzipiert sind.
[CTA_MODULE]
Methodologie und Demografie
Dieser Bericht basiert auf einer weltweiten Umfrage unter 500 führenden Daten- und Technologieführern, die im vierten Quartal 2025 in den USA, Großbritannien, EMEA und APAC mit einem Konfidenzniveau von 95% (Fehlerquote ± 4,4%) durchgeführt wurde. In der Umfrage wurden vier Kernbereiche des Datenbetriebs in Unternehmen untersucht: Betriebsmodell und Umfang, Kosten und Wartung, Datenkapazität, Zugriff und Flexibilität sowie Budget, ROI und KI-Bereitschaft. Die Ergebnisse wurden analysiert, um globale Muster in Bezug auf die Zuverlässigkeit der Pipeline, den betrieblichen Reifegrad, die Integrationsausgaben und die Auswirkungen der Modernisierung auf den ROI zu identifizieren.
Die Unternehmensgröße tendierte zu größeren Organisationen, wobei 70% von Unternehmen mit 5.000-9.999 Mitarbeitern, 23% von 10.000-49.999 Mitarbeitern und 5% von Unternehmen mit über 50.000 Mitarbeitern stammten.
Die Umfrage umfasste einen breiten Branchenmix, darunter Finanzdienstleistungen (23%), Fertigung (20%), Technologie (20%), Einzelhandel/Konsumgüter (19%), Gesundheitswesen (15%) und Gastgewerbe (3%). Die Befragten hatten leitende Positionen wie VP of Data Engineering/Data Integration/Data Analytics (26%), VP of IT/IS/Enterprise Systems/Technology (21%), CIO (16%), CTO (16%), CDO (16%) und Chief Digital Officer (5%) inne.
Verwandte Beiträge
Kostenlos starten
Schließen auch Sie sich den Tausenden von Unternehmen an, die ihre Daten mithilfe von Fivetran zentralisieren und transformieren.









