Rapport de référence 2026 sur l'infrastructure de données d'entreprise


Les entreprises dépensent en moyenne 29,3 millions de dollars par an pour les programmes de données, dont 2,2 millions de dollars sont consacrés au fonctionnement des pipelines de données.
Les données sont devenues l'un des éléments les plus importants des budgets technologiques des entreprises, en raison de la nécessité de renforcer l'analyse, l'IA et la prise de décision en temps réel. Pourtant, malgré des investissements sans précédent, la plupart des organisations ont du mal à traduire leurs dépenses en impact. Les pannes de pipeline, les temps d'arrêt et les opérations manuelles consomment discrètement des millions de dollars chaque année, ce qui réduit la productivité, retarde les initiatives d'IA et limite les rendements.
Pour comprendre l'état réel de l'infrastructure de données d'entreprise, Fivetran a interrogé plus de 500 hauts responsables des données et de la technologie issus d'organisations comptant plus de 5 000 employés issus de différents secteurs et régions du monde. Les résultats révèlent que le problème n'est pas le sous-investissement mais l'architecture. La plupart des entreprises continuent de s'appuyer sur une intégration de données fermée, fragile et exigeante en main-d'œuvre, qui ne peut pas s'adapter à l'augmentation des volumes de données, des sources ou des cas d'utilisation basés sur l'IA.
À mesure que les environnements deviennent plus complexes, les systèmes fragmentés et étroitement couplés tombent en panne le plus souvent, nécessitent une intervention humaine constante et limitent l'accès aux données entre les équipes. Il en résulte un fossé croissant entre les organisations qui considèrent l'intégration des données comme une charge opérationnelle et celles qui la considèrent comme une couche architecturale fondamentale conçue pour l'ouverture, l'interopérabilité et un accès sécurisé.
Ce rapport compare le coût réel des opérations de données en termes de dépenses, de fiabilité, d'efforts d'ingénierie et de retour sur investissement, et montre comment les choix architecturaux au niveau de la couche d'intégration détermine si les investissements dans les données accélèrent l'analytique et l'IA ou limitent discrètement leur potentiel.
[CTA_MODULE]
Resumé
Les budgets annuels de données s'élèvent en moyenne à plus de 29 millions de dollars par organisation, et une part importante de ces dépenses est perdue en raison de pannes de pipeline, d'interruptions de service et de l'effectif requis pour gérer des environnements de données de plus en plus complexes.
Voici les trois principaux enseignements de l'étude de cette année :
1. L'inefficacité opérationnelle, et non le manque d'investissement, ralentit les analyses et l'IA à grande échelle.
Les équipes chargées des données consacrent 53 % du temps d'ingénierie à la maintenance, 2,2 millions de dollars par an étant consacrés à l'entretien des pipelines par des ingénieurs à plein temps. Les canalisations traditionnelles et artisanales se cassent de 30 à 47 % plus souvent, ce qui entraîne 60 heures d'arrêt par mois. Les responsables des données estiment l'impact commercial des interruptions de service à 49 600 dollars par heure, ce qui représente un risque de près de 3 millions de dollars de valeur commerciale potentielle chaque mois, soit plus de 36 millions de dollars par an. Ces impacts sont particulièrement prononcés dans les environnements où les pipelines sont étroitement couplés et nécessitent une intervention manuelle fréquente à mesure qu'ils évoluent.
2. Les dépenses d'intégration sont plus élevées que prévu, mais le retour sur investissement reste faible.
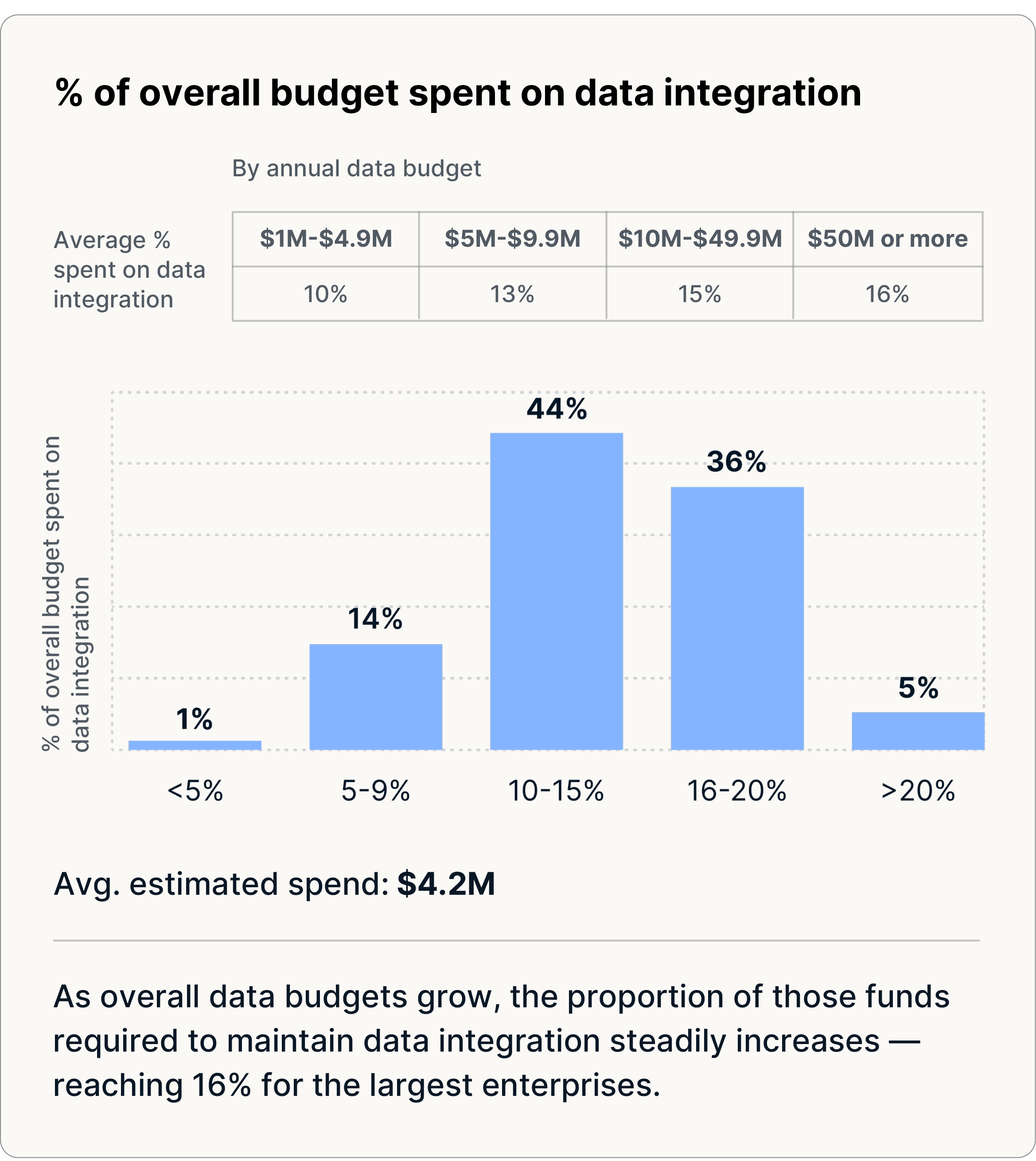
Les entreprises consacrent 14 % de leur budget total aux données (~4,2 millions de dollars) à l'intégration des données, mais seules 27 % des organisations déclarent que leurs investissements dans les données dépassent les attentes en matière de retour sur investissement. Une grande partie de ces dépenses est absorbée par des approches d'intégration manuelles et fragmentées qui deviennent de plus en plus difficiles à gérer à mesure que les volumes de données, les sources et les cas d'utilisation augmentent.
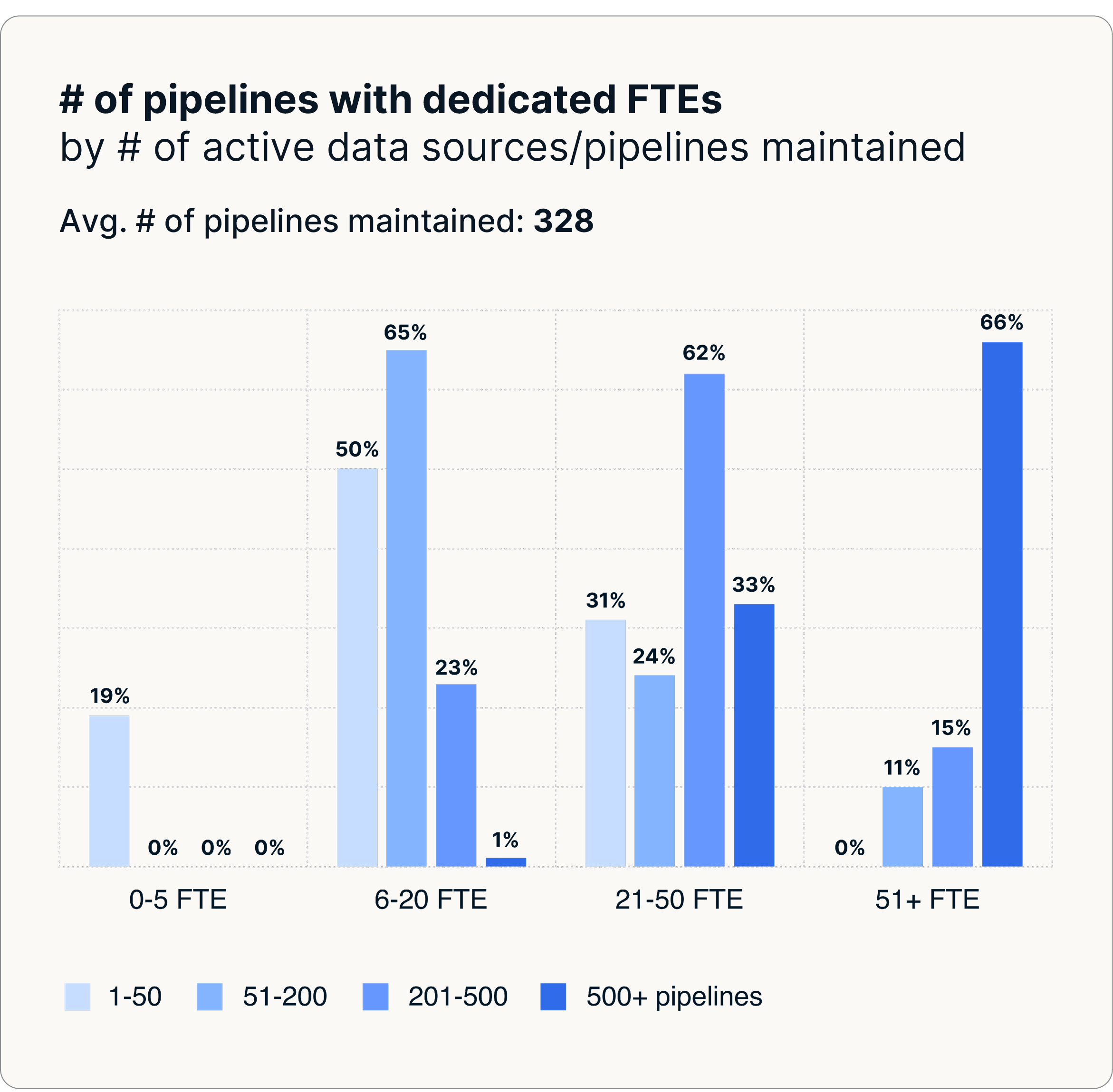
Avec 328 pipelines en moyenne et 35 à 60 ingénieurs à plein temps qui en assurent la maintenance, les organisations supportent des coûts plus élevés en raison de processus manuels fragmentés qui ont du mal à évoluer efficacement.
3. La modernisation des pipelines permet de réduire les coûts, d'améliorer la fiabilité et d'augmenter le retour sur investissement.
En adoptant des pipelines standardisés et entièrement gérés, les entreprises garantissent la fiabilité et la rentabilité nécessaires pour créer des environnements compatibles avec l'IA : une cohorte performante qui offre des temps de restauration plus rapides et est presque deux fois plus susceptible de dépasser les objectifs de retour sur investissement (45 % contre 27 %). À mesure que les frais de maintenance diminuent, les équipes peuvent rediriger leurs efforts vers l'analyse, l'IA, la gouvernance et d'autres initiatives qui dépendent d'un accès cohérent, partagé et fiable à des données fiables.
Chapitre 1 : Les pipelines peu performants limitent le retour sur investissement
Les investissements des entreprises dans les données ont atteint de nouveaux sommets, grâce à des plans ambitieux en matière d'IA, d'analyses en temps réel et d'expériences client personnalisées. En moyenne, les grandes entreprises dépensent aujourd'hui 29,3 millions de dollars par an en données, ce qui reflète le rôle central que jouent les données dans la compétitivité et l'innovation. Malgré ce niveau d'investissement, 73 % des entreprises déclarent que leurs initiatives en matière de données ne répondent pas aux attentes.
Une part importante de ces dépenses est directement liée à l'intégration des données, notamment :
- 14 % du budget total consacré aux données (~4,2 millions de dollars), y compris les outils, l'infrastructure et le personnel interne chargé du transfert, de l'ingestion et de la préparation des données
- Plus de 500 000$ par mois en coûts d'ingestion et de calcul dans le cloud
- 2,2 millions de dollars par an en main-d'œuvre d'ingénierie dépensés spécifiquement pour la maintenance des pipelines, une charge nettement plus lourde pour les équipes qui ont recours au bricolage ou à l'intégration des données existantes
Ces investissements reflètent des priorités commerciales de plus en plus urgentes. Les équipes s'appuient sur les données pour alimenter les modèles d'IA, proposer des expériences clients personnalisées et prendre des décisions en temps réel. Cependant, les goulots d'étranglement opérationnels, en particulier les pipelines fragiles et les flux de travail à forte intensité de main-d'œuvre, continuent de ralentir les progrès. À mesure que les attentes augmentent, la pression pour améliorer la fiabilité et l'efficacité de l'infrastructure déjà en place augmente également.
73 % des initiatives en matière de données d'entreprise ne répondent pas aux attentes malgré 29,3 millions de dollars de dépenses annuelles liées aux données.
Les ambitions en matière d'IA dépassent les opérations de données
Alors que les investissements augmentent, près de 62 % des entreprises déclarent que la maturité de leurs données est « faible », ce qui révèle le chemin qu'elles doivent encore parcourir pour parvenir à un self-service complet et à des analyses prédictives.
Nos résultats montrent que les capacités opérationnelles de base (fiabilité, automatisation, observabilité et intégration standardisée) n'ont pas suivi le rythme des ambitions stratégiques. Les entreprises doivent faire évoluer l'IA en démocratisant l'accès aux données et en réduisant la latence des décisions, mais les systèmes sous-jacents sont souvent trop manuels ou trop fragiles pour atteindre ces objectifs.
Les points faibles incluent :
- Les ruptures de pipeline et les interruptions nuisent à la fraîcheur des données
- Les demandes de maintenance consomment plus de la moitié des ressources d'ingénierie
- Les systèmes existants et DIY entraînent des coûts plus élevés et des temps de restauration plus lents
Ces défis augmentent de façon exponentielle à grande échelle. Les grandes entreprises possèdent en moyenne 328 à plus de 400 pipelines, ce qui rend les réparations progressives et les processus manuels non durables et oblige les équipes à se consacrer à la maintenance des pipelines plutôt qu'à des projets innovants.
Les entreprises qui ont modernisé leur couche d'intégration de données grâce à des pipelines automatisés et entièrement gérés évoluent vers l'IA et l'analytique avancée. Ceux qui s'appuient encore sur des approches traditionnelles ou artisanales prennent du retard en raison d'une infrastructure qui ne peut pas évoluer.
62 % des entreprises signalent toujours une faible maturité des données, car les pipelines fragiles et les opérations manuelles occupent 53 % du temps d'ingénierie.
[MODULE_CHAT]
Chapitre 2 : Analyse comparative du coût des oléoducs fragiles nécessitant de nombreux travaux de maintenance
Malgré des niveaux records d'investissement dans les données, les bases sur lesquelles reposent les analyses d'entreprise et l'IA restent fragiles. La plupart des organisations s'appuient sur des pipelines de plus en plus complexes, difficiles à adapter et coûteux à entretenir, ce qui nuit à la productivité, à la fiabilité et à l'exécution stratégique.
Les points de référence ci-dessous illustrent à quel point la fragilité des pipelines influe sur les coûts, les opérations et les résultats commerciaux.
Pipelines Fiability and stop time
Les opérations de données d'entreprise échouent à un rythme qui perturbe considérablement les opérations, même si de nombreuses organisations n'en sont qu'à leurs débuts dans l'opérationnalisation des données pour l'IA.
Organisations Experience :
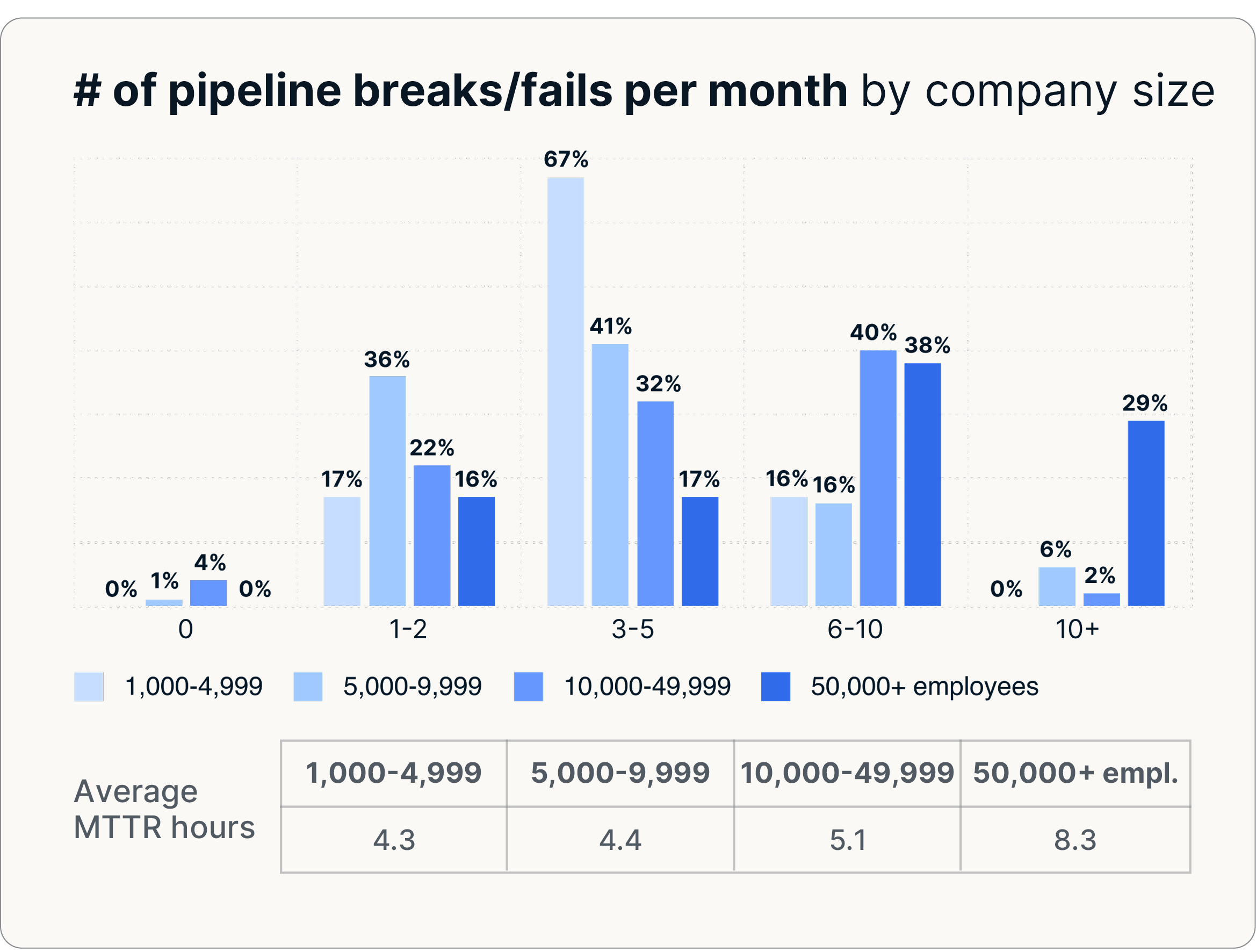
- 4,7 ruptures de canalisations par mois en moyenne
- 60,4 heures d'arrêt par mois
- Jusqu'à 8,3 pauses par mois dans les plus grandes entreprises
Bien que les ambitions en matière d'IA soient élevées, seule une minorité d'entreprises font état de modèles prédictifs ou d'Ia en production, et les lacunes en matière de préparation et de fiabilité des données continuent de retarder les analyses et la fourniture de l'IA.
Les temps d'arrêt sont coûteux et s'intensifient avec l'échelle :
- 49 600$ par heure en termes d'impact commercial estimé des interruptions de données
- S'élevant à 75 200 dollars de l'heure des temps d'arrêt dans les grandes entreprises
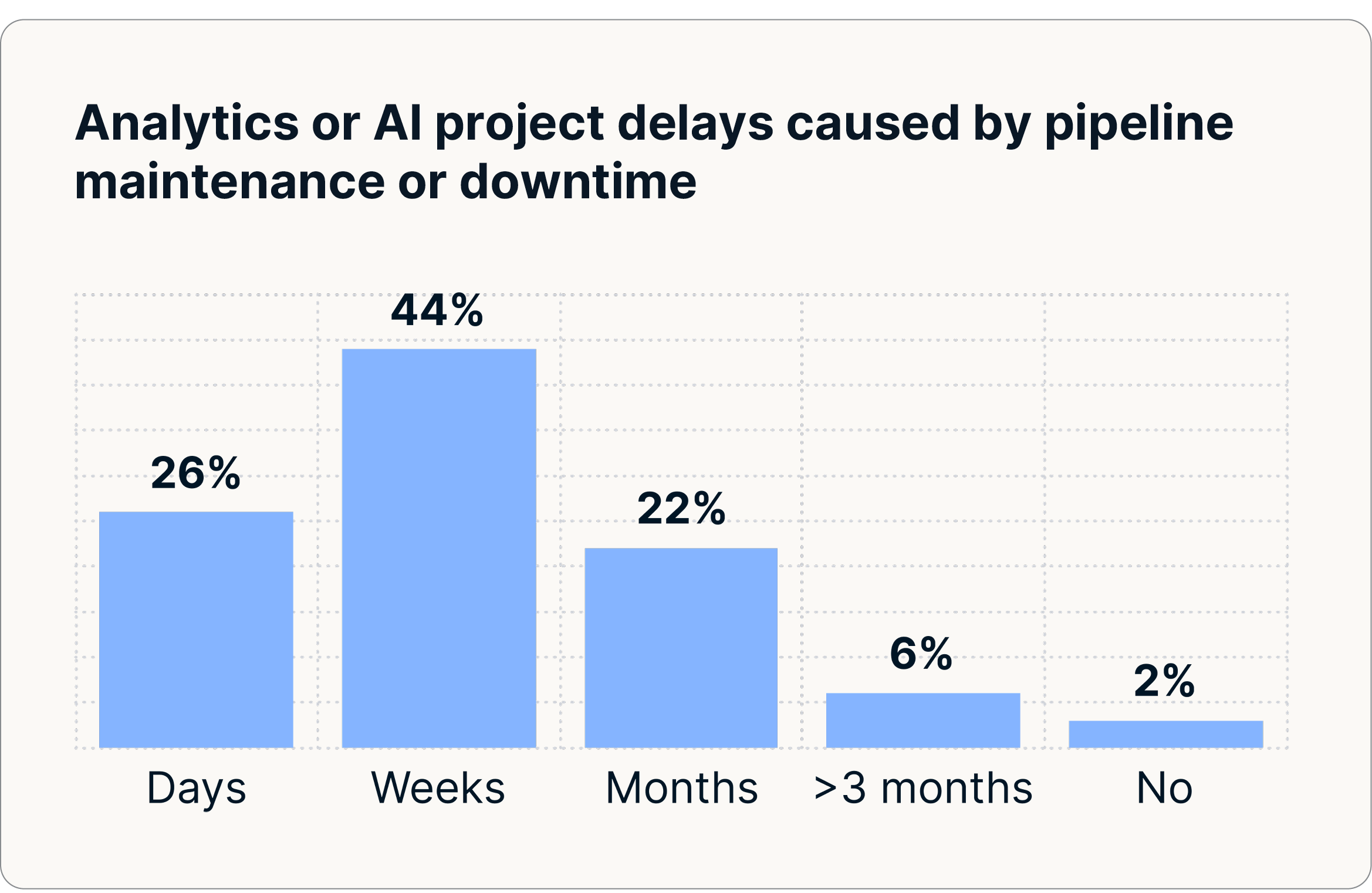
Ces perturbations dégradent les modèles d'IA, nuisent à la précision des tableaux de bord et ralentissent la prise de décision. Les leaders de tous les secteurs signalent que l'intégration peu fiable des données retarde régulièrement les initiatives d'analyse et d'IA, créant ainsi des inefficacités qui se répercutent sur l'entreprise. Près de 30 % des organisations sont confrontées à des retards d'un mois ou plus dans la livraison de leurs projets d'analyse et d'IA en raison de problèmes de maintenance du pipeline ou de temps d'arrêt.
Temps d'ingénierie, effectifs et coûts de main-d'œuvre cachés
La fiabilité de l'intégration des données se reflète le plus clairement dans les efforts déployés par les équipes pour assurer le bon fonctionnement des pipelines. Lorsque les intégrations ne sont pas fiables, le temps d'ingénierie passe de l'innovation à la maintenance.
Report of organisations :
- 53 % du temps d'ingénierie dépenses consacrées à l'entretien des pipelines
- 35 ingénieurs à plein temps gérant en moyenne 328 pipelines
- Plus de 50 ingénieurs à temps plein gestion de plus de 500 pipelines dans de grandes entreprises
Les approches d'intégration traditionnelles et artisanales aggravent la charge opérationnelle :
- 30 à 47 % plus fréquentes canalisations ruptures
- 2 à 4 heures supplémentaires requises pour les réparations
- Cost by pipeline 25 % plus élevé (1 900 dollars traditionnels contre 1 600 dollars d'Elt entièrement gérés)
Les ratios ingénieurs à temps plein élevés par rapport au pipeline, les interventions manuelles intensives et l'automatisation limitée réduisent l'agilité opérationnelle et maintiennent les équipes d'ingénierie en mode réactif.
Impact des échecs d'intégration sur les entreprises
L'intégration peu fiable des données a un impact direct sur les performances de l'entreprise :
- 97 % des entreprises signalent des perturbations dans leurs initiatives d'IA ou d'analyse
- 70 % des entreprises signalent des impacts négatifs sur les projets de personnalisation des clients ou de réduction des coûts
- 36 millions de dollars à 54 millions de dollars impact annuel estimé sur les activités (c'est-à-dire la perte de revenus potentiels) du manque d'accès en temps opportun à de nouvelles données
Lorsque les entreprises dépendent de données périmées ou incomplètes, que les modèles d'IA sont sous-performants ou ne sont pas déployés, que la personnalisation perd en précision ou en efficacité, que les programmes stratégiques ralentissent en raison de l'incertitude ou du manque d'informations fiables, et que les équipes chargées des données sont entraînées dans une lutte réactive au lieu de stimuler l'innovation.
Le coût caché des échecs d'intégration des données : 2,2 millions de dollars en maintenance annuelle, plus de 60 heures d'arrêt par mois, des initiatives d'IA retardées et une capacité d'innovation réduite.
Chapter 3 : Les avantages de la modernisation de la gestion des données
Après des années de corrections progressives, d'endettement technique croissant et de frais de maintenance croissants, les entreprises reconnaissent que les approches d'intégration traditionnelles et personnalisées ne peuvent plus répondre aux exigences modernes de gestion des données.
En revanche, l'ELT entièrement gérée et automatisée est devenue la base de l'IA, réduisant le coût total de possession, stabilisant les opérations relatives aux données, permettant aux équipes chargées des données de se concentrer sur l'innovation et accélérant le délai de rentabilisation.
Coûts réduits et fiabilité accrue
La différence de coût entre les approches d'intégration des données traditionnelles et modernes est significative et ne cesse de croître. Les organisations utilisant un ETL traditionnel dépensent 1 900 dollars par pipeline, contre 1 600 dollars avec un ETL entièrement géré. La différence s'accumule rapidement à l'échelle de l'entreprise, où des centaines, voire des milliers de pipelines doivent être entretenus.
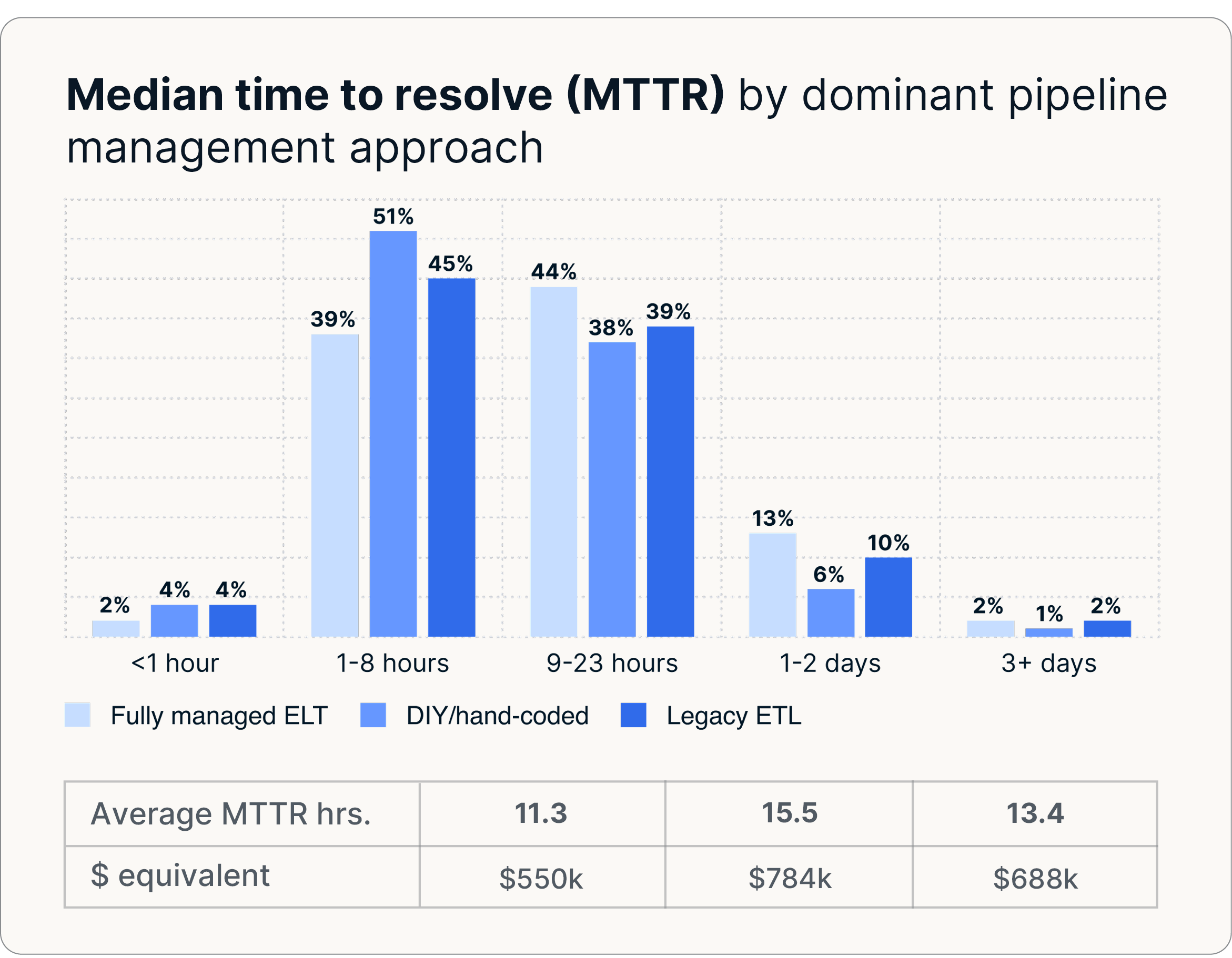
Les anciens systèmes tombent également en panne beaucoup plus fréquemment. Les entreprises qui s'appuient sur des scripts personnalisés ou des solutions ETL développées en interne signalent 30 à 47 % de défaillances de pipeline en plus et des délais de restauration plus longs, les incidents nécessitant généralement de 13 à 16 heures pour être résolus. En revanche, les entreprises qui se modernisent grâce à une ELT entièrement gérée pour se préparer à l'IA réduisent les délais de restauration à 11 heures seulement. En réduisant à la fois la fréquence des pauses et le temps nécessaire à la reprise, l'ELT entièrement gérée améliore la prévisibilité opérationnelle et réduit considérablement les risques.
Il en résulte une amélioration mesurable de la disponibilité et de la fiabilité. Avec moins de pannes et une reprise plus rapide, les systèmes d'analyse en aval et d'IA bénéficient d'un accès plus cohérent aux nouvelles données. Les ingénieurs peuvent se fier à leurs pipelines, les utilisateurs professionnels peuvent avoir confiance en leurs données et les dirigeants peuvent compter sur des informations opportunes pour orienter leurs décisions.
300$ d'économies par pipeline par an grâce à l'intégration automatisée des données, soit une économie à 6 chiffres à l'échelle de l'entreprise.
Recovery of Engineering Capacity
L'un des impacts les plus transformateurs de la modernisation est la modification de la façon dont les équipes chargées des données répartissent leur temps. Dans les environnements existants, les équipes d'ingénierie consacrent 53 % de leur temps à la maintenance des pipelines et au support réactif. L'intégration moderne des données permet de doubler le temps dont disposent les équipes pour travailler sur des initiatives stratégiques qui génèrent de la valeur commerciale.
Grâce à des pipelines automatisés et entièrement gérés :
- Les ingénieurs passent moins de temps à diagnostiquer les défaillances et plus de temps à dynamiser l'entreprise
- Les initiatives en matière d'IA et de modélisation prédictive progressent plus rapidement
- Les programmes de gouvernance, de conformité et d'analyse en temps réel prennent de l'ampleur
- L'accès aux données en libre-service devient plus large et plus sûr, réduisant ainsi la dépendance à l'égard des experts difficiles à trouver
Le remplacement de scripts personnalisés fragiles par une intégration de données standardisée et automatisée réduit la dépendance à l'égard des connaissances tribales spécialisées. Au lieu de faire appel à des experts du domaine pour résoudre les problèmes ou gérer des flux de travail complexes, les équipes fonctionnent selon un modèle opérationnel prévisible, ce qui améliore l'agilité et permet une évolutivité sans augmentation proportionnelle des effectifs.
À mesure que les charges opérationnelles diminuent, les entreprises réorientent leurs capacités vers des initiatives à plus forte valeur ajoutée. Les équipes de données les plus performantes font état d'une attention accrue portée aux points suivants :
- Analyses prédictives (69 %)
- Analyses en libre-service (65 %)
- Gouvernance et conformité (59 %)
- Innovation en matière d'IA (56 %)
Un retour sur investissement plus élevé grâce à des données plus fiables
Les investissements dans des ELT entièrement gérés et automatisés génèrent des rendements commerciaux mesurables. En établissant les bases stables nécessaires à des environnements adaptés à l'IA, les organisations utilisant une ELT entièrement gérée ont presque deux fois plus de chances de dépasser leurs objectifs de retour sur investissement (45 % contre 27 %), renforçant ainsi le lien entre la discipline opérationnelle et la performance financière.
Trois facteurs sont à l'origine de cet effet d'amplification :
- Répétability: Les pipelines automatisés réduisent la variabilité et minimisent les erreurs, garantissant ainsi la cohérence et la standardisation de la fourniture de données Évolutivité : les balances ELT entièrement gérées avec
- Évolutivity: ELT Scale entièrement gérée avec des volumes et des sources de données sans effort d'ingénierie supplémentaire
- Fiability: Des flux de données prévisibles améliorent la qualité des informations, renforcent les performances des modèles et accélèrent la prise de décision
Les entreprises dont les opérations de gestion des données sont parvenues à maturité font également preuve d'une plus grande efficacité opérationnelle, notamment en adoptant davantage de modèles prédictifs, en élargissant les analyses en libre-service et en renforçant l'alignement entre les équipes chargées des données et les parties prenantes de l'entreprise. En réduisant le temps consacré aux infrastructures, les entreprises libèrent les capacités nécessaires pour innover rapidement et à grande échelle.
45 % dépassent les objectifs de retour sur investissement avec une ELT entièrement gérée, contre 27 % en utilisant des approches personnalisées ou traditionnelles.
[CTA_MODULE]
Principales implications pour les responsables des données
Les entreprises qui modernisent leurs opérations de données obtiennent de meilleurs résultats en termes de rentabilité, de fiabilité et de préparation à l'IA.
Les données montrent que les gains les plus importants ne proviennent pas de corrections incrémentielles, mais de l'abandon d'intégrations fragiles nécessitant beaucoup de maintenance au profit de modèles d'exploitation plus faciles à gérer, à réutiliser et à adapter à mesure que les environnements de données se développent. Sur la base de ce point de référence, la voie à suivre est claire. Pour réduire le coût total des données, augmenter le retour sur investissement et accélérer la préparation à l'IA, les responsables des données devraient :
1. Evaler le coût total de manière holistique
Ne vous limitez pas aux coûts d'outillage et prenez en compte l'intégralité de la charge opérationnelle liée à l'intégration des données, notamment le temps d'ingénierie, les temps d'arrêt, les cycles de réparation et l'impact commercial en aval. Les coûts cachés, tels que 49 600 dollars par heure d'arrêt et 2,2 millions de dollars de dépenses de maintenance annuelles, l'emportent souvent sur le prix de l'outil lui-même, ce qui rend les approches traditionnelles et artisanales bien plus coûteuses qu'il n'y paraît.
2. Priorisez l'automatisation pour réduire les tâches de maintenance
53 % du temps d'ingénierie étant consacré à la maintenance de l'intégration, l'automatisation est le moyen le plus rapide de récupérer de la capacité. La réduction des interventions manuelles permet de quasiment doubler le temps disponible pour des travaux d'ingénierie à plus forte valeur ajoutée, sans augmenter les effectifs.
3. Standardisez l'intégration des données pour réduire les risques opérationnels
Les intégrations personnalisées et fragmentées introduisent de la variabilité et des risques à mesure que les environnements de données s'étendent. Les approches traditionnelles et artisanales échouent de 30 à 47 % plus souvent et coûtent 25 % de plus par pipeline à entretenir. L'intégration standardisée améliore la fiabilité, la cohérence et l'évolutivité à mesure que la complexité augmente.
4. Renforcez les bases de données avant de faire évoluer l'IA
Les initiatives d'IA dépendent de données récentes, cohérentes et bien gérées. En l'absence de diffusion prévisible des données, même les programmes d'IA bien financés stagnent ou ne donnent pas les résultats escomptés. La mise en place d'une base de données solide garantit que les investissements dans l'IA peuvent être soutenus de manière fiable en production.
5. Aligner les dépenses sur les résultats commerciaux, et non sur la maintenance de l'infrastructure
Passez de la maintenance de systèmes fragiles à des plateformes qui accélèrent les analyses, améliorent la qualité des données et favorisent la préparation à l'IA. En adoptant une ELT entièrement gérée, les entreprises établissent les bases fiables nécessaires pour créer des environnements compatibles avec l'IA et sont presque deux fois plus susceptibles de dépasser les attentes en matière de retour sur investissement, démontrant ainsi comment la maturité opérationnelle influe sur les rendements au sein de l'écosystème de données.
Les budgets de données à eux seuls ne créent pas de valeur. Les organisations qui associent leurs investissements à des pratiques d'intégration conçues pour l'évolutivité, la fiabilité opérationnelle et un large accès aux données sont celles qui obtiennent un retour sur investissement plus élevé, des progrès plus rapides en matière d'IA et un avantage concurrentiel durable.
Pour les leaders des données, l'opportunité est claire : réorienter les investissements d'une intégration fragile et nécessitant une maintenance intensive vers des bases de données modernes conçues pour des analyses fiables et une IA évolutive.
[CTA_MODULE]
Méthodologie et démographie
Ce rapport est basé sur une enquête mondiale menée auprès de 500 hauts responsables des données et de la technologie au quatrième trimestre 2025 avec un niveau de confiance de 95 % (marge d'erreur de ± 4,4 %) aux États-Unis, au Royaume-Uni, dans la région EMEA et dans la région APAC. L'enquête a examiné 4 domaines principaux des opérations de données d'entreprise : le modèle d'exploitation et l'échelle, les coûts et la maintenance, la capacité des données, l'accès et la flexibilité, ainsi que le budget, le retour sur investissement et la préparation à l'IA. Les résultats ont été analysés afin d'identifier les tendances mondiales en matière de fiabilité des pipelines, de maturité opérationnelle, de dépenses d'intégration et d'impact de la modernisation sur le retour sur investissement.
La taille des entreprises était orientée vers les grandes organisations, 70 % provenant d'entreprises comptant 5 000 à 9 999 employés, 23 % de 10 000 à 49 999 employés et 5 % d'entreprises comptant plus de 50 000 employés.
L'enquête a porté sur un large éventail de secteurs, notamment les services financiers (23 %), l'industrie manufacturière (20 %), la technologie (20 %), la vente au détail/CPG (19 %), la santé (15 %) et l'hôtellerie (3 %). Les personnes interrogées ont occupé des postes de direction tels que vice-président de l'ingénierie des données/de l'intégration des données/de l'analyse des données (26 %), vice-président de l'IT/des systèmes/technologies de l'information et des systèmes d'entreprise (21 %), directeur informatique (16 %), directeur technique (16 %) et directeur numérique (5 %).
Articles associés
Commencer gratuitement
Rejoignez les milliers d’entreprises qui utilisent Fivetran pour centraliser et transformer leur data.









