4 data architecture challenges modern data lakes solve


Solve 4 key data management issues with the modern data lake
Fivetran Managed Data Lake Service solves complexity, vendor lock-in, rising compute costs, and long-term data retention.
We have previously discussed the architecture of the modern data lake, characterized by interoperability with a wide range of open table formats and catalogs, as well as the full decoupling of storage and compute. The management and maintenance of open table formats can be further simplified with the help of the Fivetran Managed Data Lake Service, lightening engineering loads on data teams.
As the centerpiece of a unified data architecture, the modern data lake also directly solves four data management challenges — reducing architectural complexity, avoiding vendor lock-in, controlling compute costs, and enabling long-term data retention.
1. Complexities causing compliance headaches
The first challenge is that posed by a complex architecture involving multiple data integration approaches, destinations, and cloud platforms. This architecture can result from mergers and acquisitions, longstanding siloes between business units, or the separation of operational and analytical data stacks.
The many-to-many nature of these connections between sources and destinations duplicates data across many destinations and clouds. Each of these data assets and pipelines must be audited for regulatory compliance, posing an unmanageable data governance burden.
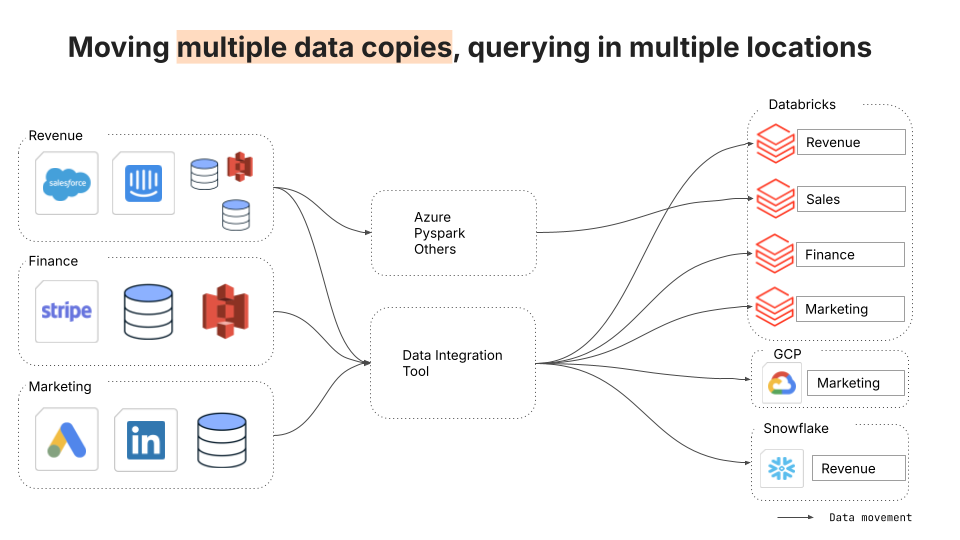
The solution to this complexity is a universal storage layer with a single data integration tool and a single destination. A universal storage layer not only radically reduces the number of pipelines but also ensures that data is centralized, deduplicated, standardized, easily governed, and accessible to all consuming services.

2. Limited optionality and vendor lock-in risk
This second challenge still features multiple data integration approaches, but instead of integrating data into multiple clouds, moves all the data into a single data warehouse. The problem here is no longer complexity per se but the strict coupling between storage and compute. While storage is a commodity, different compute engines are optimized for different kinds of use cases, offering different capabilities and tradeoffs in terms of cost, performance, and scalability. In the architecture below, all users across an organization are forced to accept the tradeoffs made by the query engine coupled with the data warehouse.
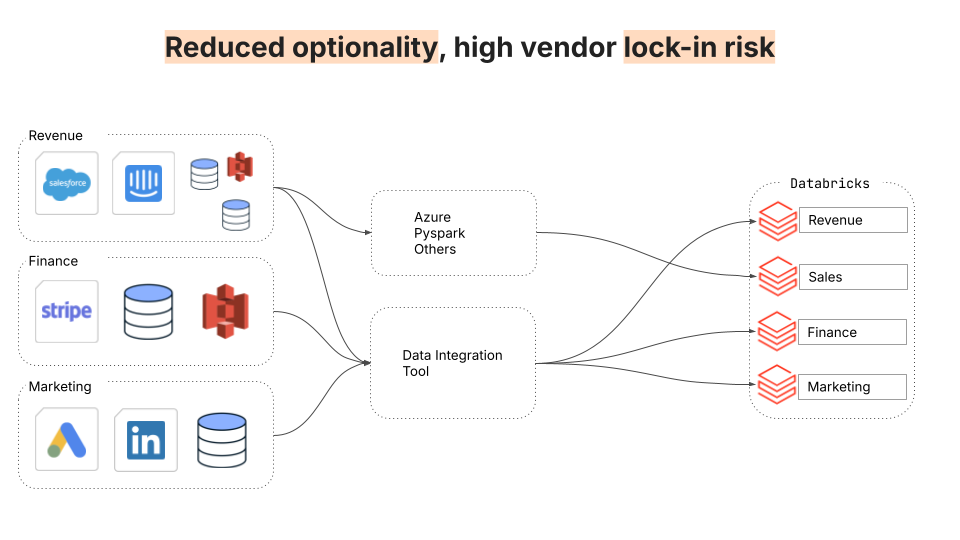
Switching from a data warehouse to a modern data lake enables different end users to select query engines tailored to their specific use cases, such as web applications, machine learning, high-performance computing, and more

3. Ever-increasing TCO of data compute
The third challenge once again concerns data integration in a complex architecture with multiple destinations. This leads to the duplication of data and, with it, increased compute costs related to ingestion.
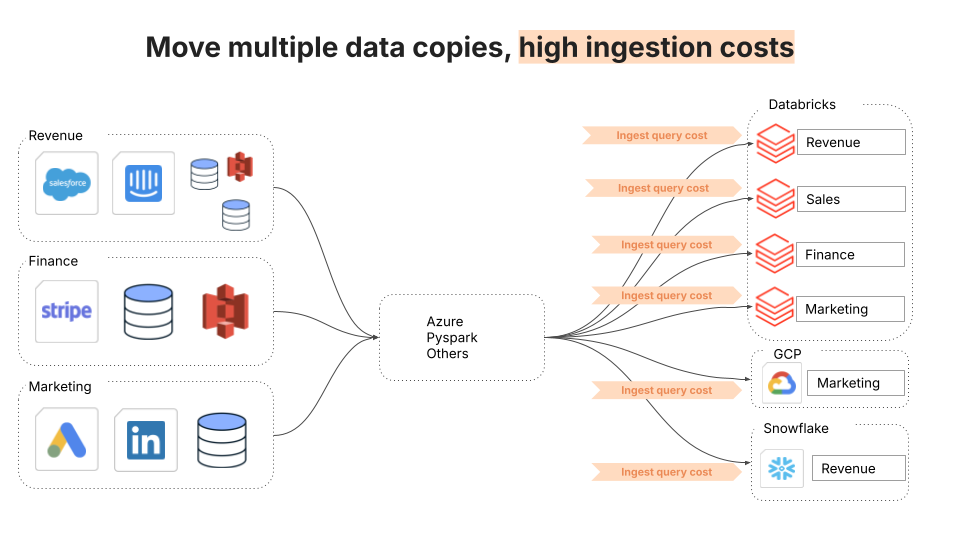
Fivetran Managed Data Lake Services solves this problem in two ways. The first is by using a modern data lake as a single, canonical destination. The second, unique to the Fivetran Managed Data Lake Service, is by absorbing the cost of data ingestion outright. Data ingestion accounts from 20-30% of the compute costs in a data warehouse (other major contributors are transformations, reads, and exports).
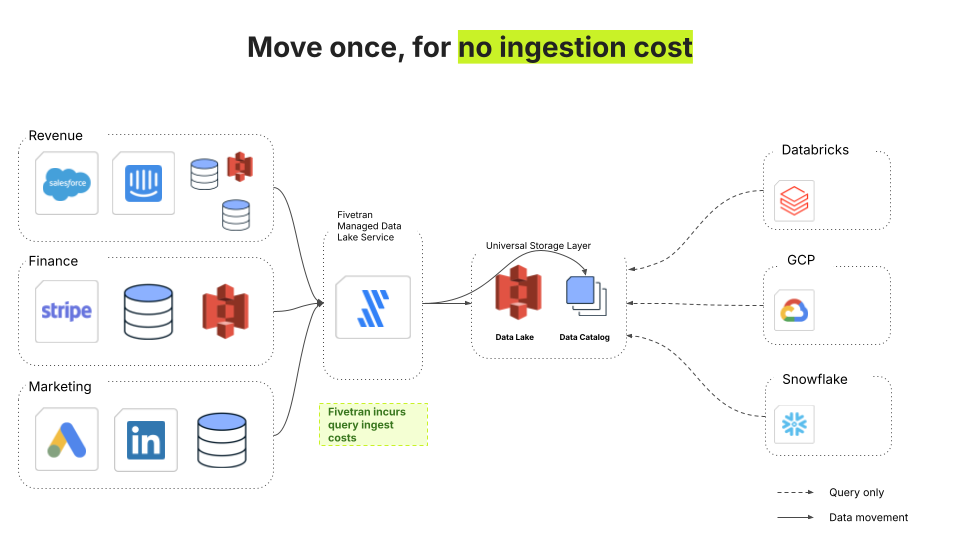
4. Long-term storage of historical data
The fourth challenge concerns the importance of preserving historical snapshots to analyze long-term trends, create audit trails, and data recovery from system failures. Some destinations offer extremely limited capabilities for time travel; Google BigQuery, for instance, only enables time travel to the past seven days. Moreover, these time travel capabilities are tightly coupled with the respective query engines of the data warehouses.
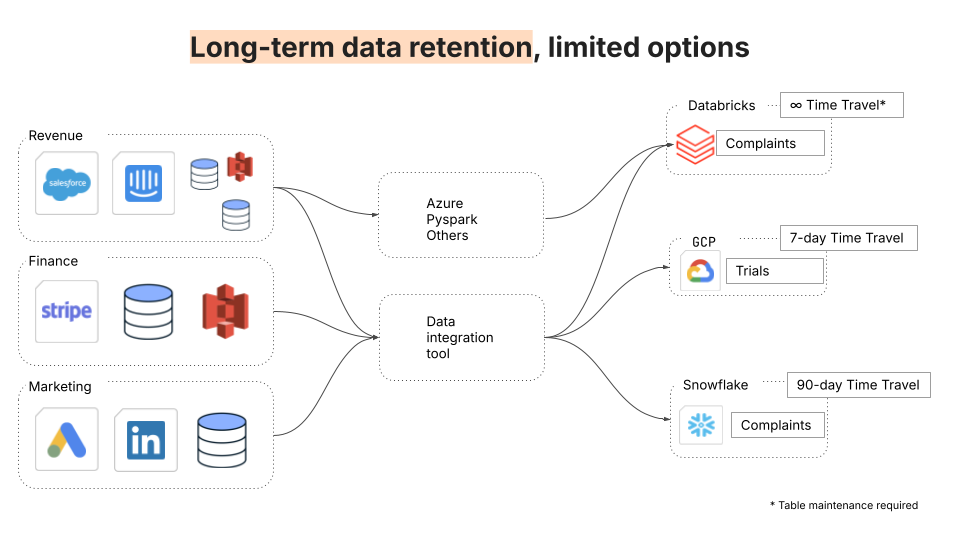
As a cost-effective, highly scalable storage layer, data lakes not only offer teams unlimited cold storage but also a choice of any query engine for compute.
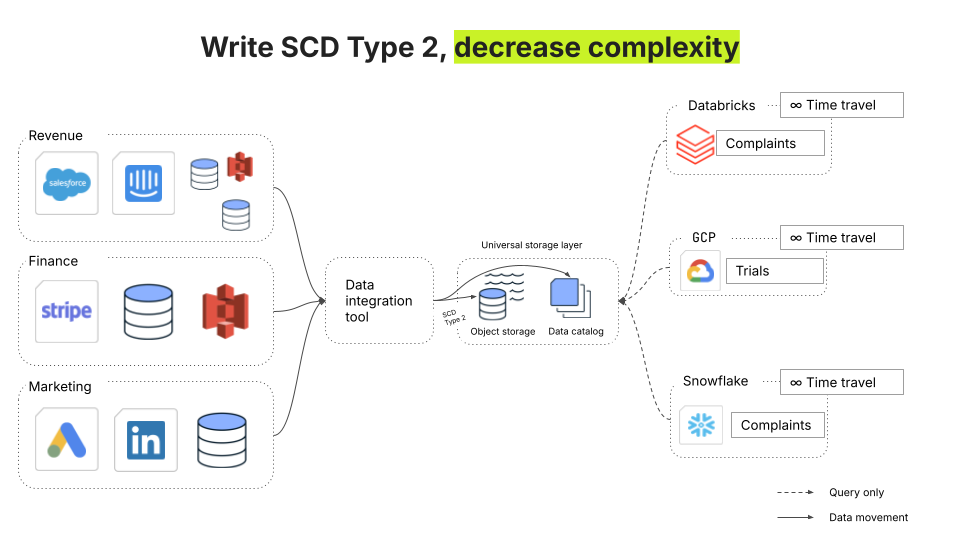
Fivetran’s Managed Data Lakes Service is the answer
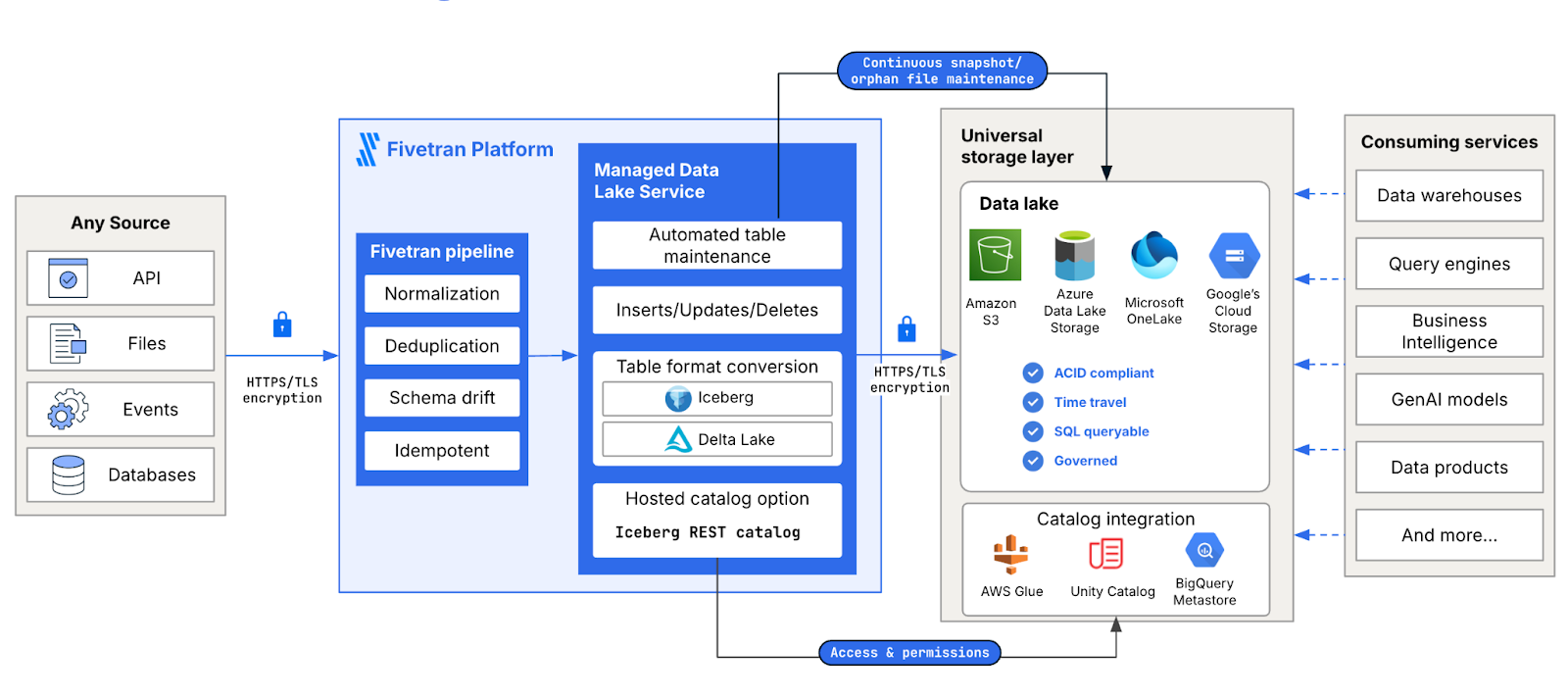
With the use of open table formats and catalogs, modern data lakes combine interoperability and scalability with the essential functionality of data warehouses. The Fivetran Managed Data Lake service further augments these capabilities with the absorption of ingest costs as well as automation of both data integration and the management of open table formats. In doing so, Fivetran Managed Data Lake Service solves four major categories of data management problems – complexity, vendor lock-in, rising compute costs, and long-term data retention.
[CTA_MODULE]
Verwandte Beiträge
Start for free
Join the thousands of companies using Fivetran to centralize and transform their data.










