4 défis d'architecture data résolus par les data lakes modernes


Si vous avez déjà construit ou entretenu une plate-forme data, vous connaissez les compromis. Les architectures deviennent rapidement désordonnées. Les coûts augmentent à chaque nouveau pipeline. La conservation des data historiques est un combat permanent. Et une fois que l'on est enfermé dans l'écosystème d'un seul fournisseur, la flexibilité disparaît.
Il ne s'agit pas de problèmes abstraits, mais de réalités quotidiennes qui ralentissent les ingénieurs et les architectes data. C'est pourquoi de plus en plus d'équipes se tournent vers des data lakes modernes comme base de leurs plate-formes. En découplant le stockage du calcul et en adoptant les formats open table, les data lakes créent une architecture plus simple, plus flexible et plus rentable.
Avec le service Fivetran Managed Data Lake, vous pouvez aller encore plus loin : automatiser l'ingestion, absorber les coûts de pipeline lourds en calcul et libérer votre équipe de l'entretien d'une infrastructure fragile. Dans cette publication, nous allons examiner les 4 défis les plus courants auxquels les équipes techniques sont confrontées – et comment un data lake géré permet de les résoudre.
[CTA_MODULE]
1. Des complexités à l'origine de problèmes de conformité
Les architectures existantes ressemblent souvent à un patchwork de pipelines, d'entrepôts et d'intégrations sur mesure. Les data sont copiées vers de multiples destinations à travers de multiples clouds (c'est-à-dire une relation de plusieurs à plusieurs), ce qui crée des ensembles de data redondants, des pipelines fragiles et des risques pour la conformité lorsqu'il n'est pas clair où se trouvent les data sensibles ou quelle est la version définitive.
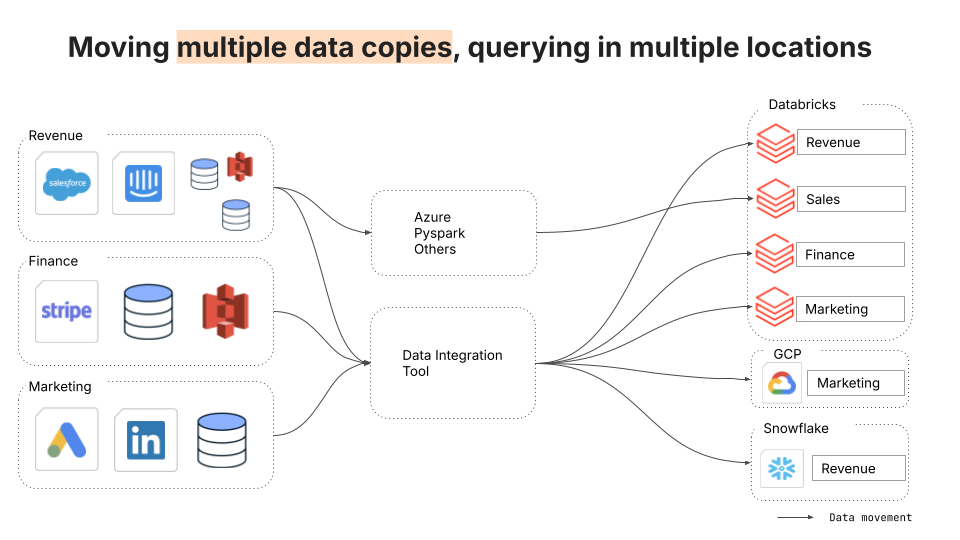
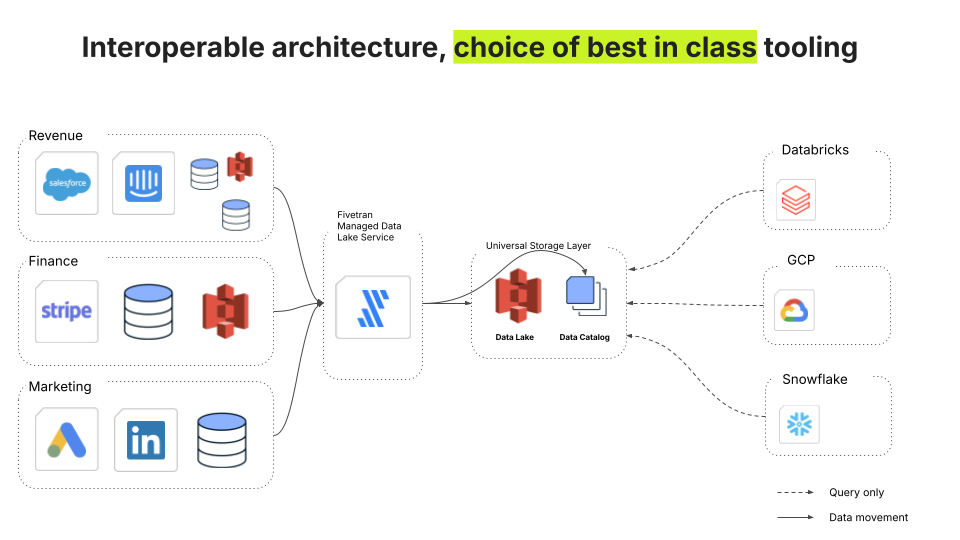
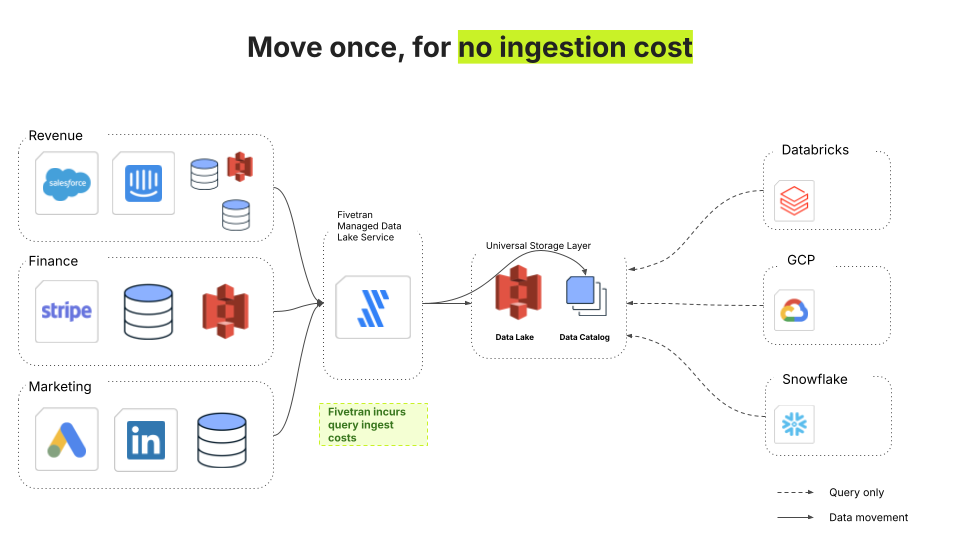
La solution à cette complexité est une couche de stockage universelle avec un chemin d'intégration unique. Avec Fivetran Managed Data Lake, les données sont ingérées une seule fois dans un stockage centralisé et dédupliqué. À partir de là, tout service en aval peut l'interroger - Databricks, Snowflake, GCP ou tout ce que requiert votre pile.
Les ingénieurs gèrent moins de pipelines, simplifient les audits et évoluent sans multiplier la complexité.
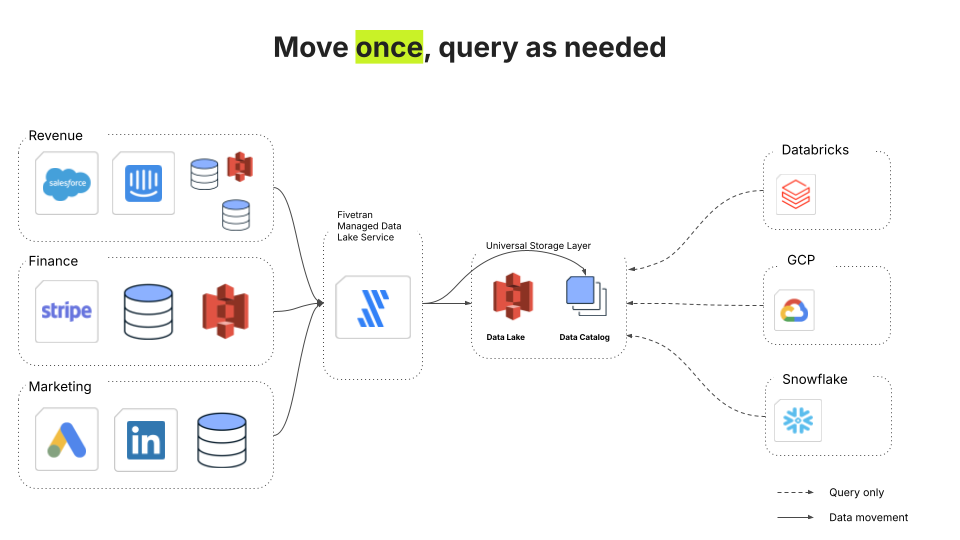
2. Options limitées et risque de dépendance aux fournisseurs
Les entrepôts traditionnels vous obligent à utiliser un seul moteur de calcul, associant étroitement le stockage et le calcul. Chaque équipe, qu'elle élabore des modèles ML ou qu'elle exécute des tableaux de bord d'informatique décisionnelle, est confrontée aux mêmes compromis en matière de performances, même si différents moteurs de calcul sont optimisés pour différents types de cas d'utilisation.
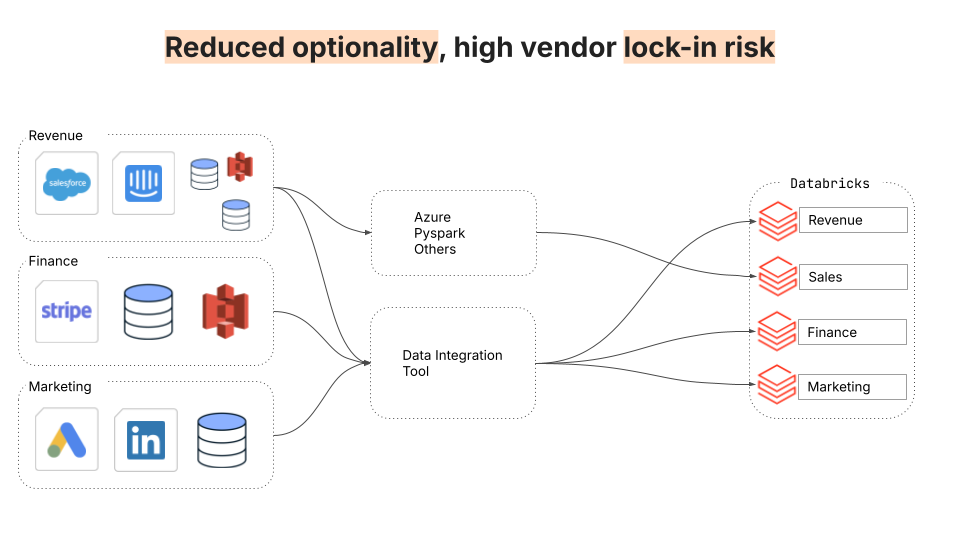
La solution est un data lake moderne qui dissocie le stockage du calcul, donnant à chaque équipe la liberté de choisir le bon outil pour le travail. Fivetran Managed Data Lake prend en charge les formats de tables et les catalogues ouverts, ce qui vous permet d'utiliser le meilleur moteur de requête pour chaque charge de travail sans avoir à réécrire les pipelines. Les ingénieurs retrouvent de la flexibilité : Databricks pour ML, Snowflake pour l'informatique décisionnelle, PySpark pour les travaux par lots – le tout sans dépendance aux fournisseurs.
3. Augmentation des coûts de calcul
L'ingestion et la réingestion de data sur plusieurs plate-formes peuvent faire grimper les coûts en flèche. La duplication des data signifie que les organisations paient souvent plusieurs fois pour les mêmes charges de travail. Dans de nombreux cas, l'ingestion représente à elle seule 20 à 30 % des coûts de calcul du warehouse.
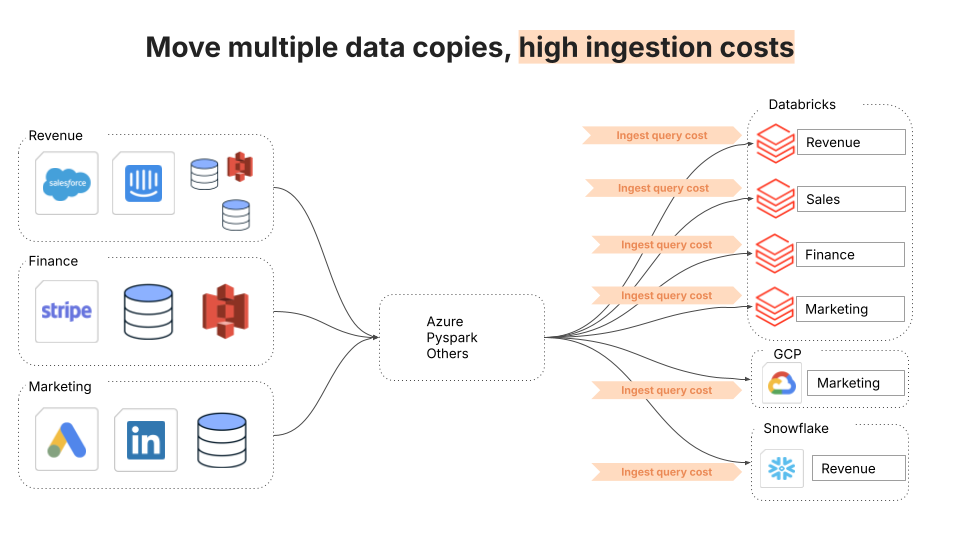
Fivetran Managed Data Lake répond à ce problème de deux façons : Les data se retrouvent une fois dans le lake, ce qui élimine l'ingestion redondante. Fivetran absorbe également les coûts d'ingestion (qui représentent 20 à 30 % des coûts de calcul dans un data warehouse). Il ne s'agit pas d'une remise, mais d'un changement architectural fondamental qui élimine l'un des principaux facteurs du coût total de possession.
4. Conservation à long terme des data historiques
Les data historiques sont essentielles pour les audits, les analyses à long terme et la reprise, mais la plupart des warehouses plafonnent la conservation. BigQuery, par exemple, ne prend en charge que 7 jours de « voyage dans le temps ». Les équipes finissent par élaborer des solutions de contournement ou par payer des frais élevés de stockage à froid.
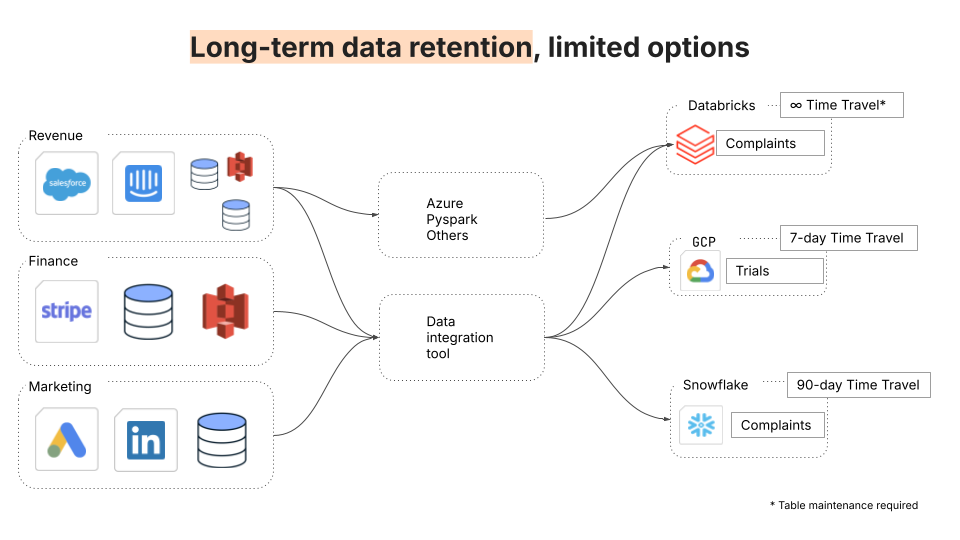
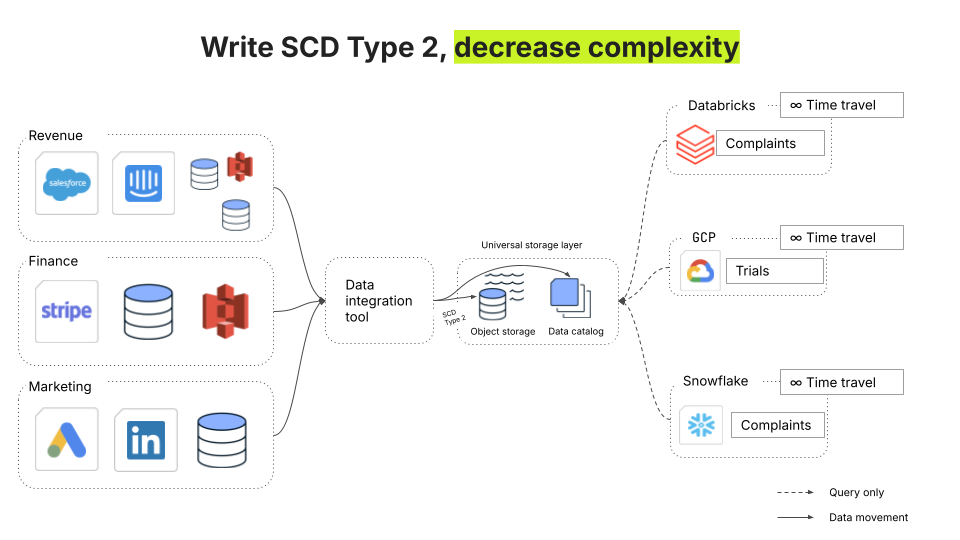
Un data lake offre un stockage à froid illimité et rentable et vous permet de l'associer à n'importe quel moteur de recherche. Il est ainsi possible de conserver un contexte historique complet, de créer des pistes d'audit et d'effectuer des recherches dans le temps avancées sans se heurter à des limites. Grâce au service Fivetran Managed Data Lake, les équipes data peuvent préserver l'historique sans sacrifier les coûts ou les performances.
Pourquoi Fivetran Managed Data Lakes Service
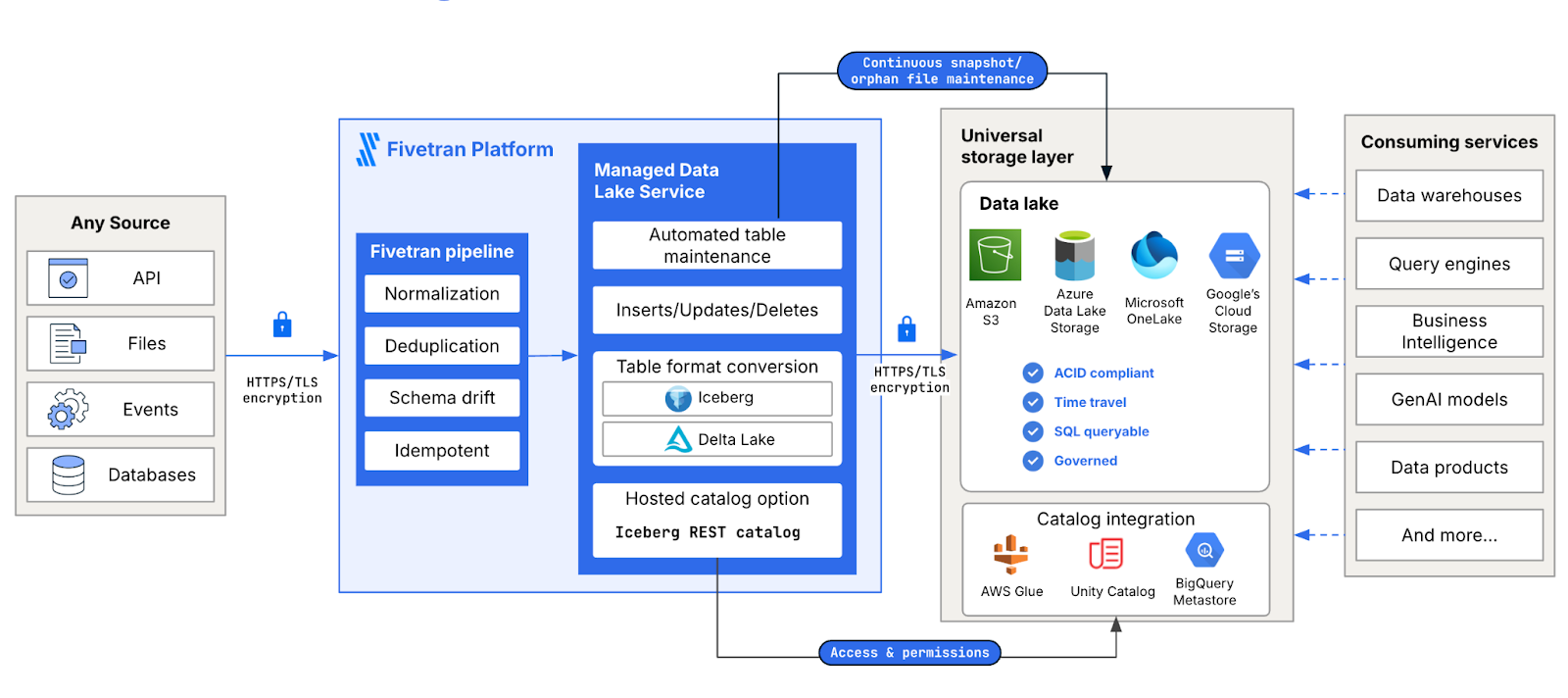
Avec des formats de table ouverts, une intégration automatisée et des coûts d'ingestion couverts, le service Fivetran Managed Data Lake combine l'évolutivité des lakes avec la facilité d'utilisation des warehouses. Pour les équipes data, cela signifie :
- Moins de pipelines à gérer et à déboguer
- Liberté de choisir les meilleurs moteurs de recherche
- Coût total de possession plus faible et plus prévisible
- Conservation illimitée et flexible des data
Au lieu de passer des cycles à gérer des pipelines fragiles, les ingénieurs peuvent se concentrer sur la construction de modèles, d'applications et d'informations qui font avancer l'entreprise.
Si vous construisez une architecture data à l'épreuve du temps, un data lake géré élimine les obstacles techniques les plus difficiles à surmonter, tout en vous offrant davantage de contrôle, de flexibilité et d'efficacité.
[CTA_MODULE]
Articles associés
Commencer gratuitement
Rejoignez les milliers d’entreprises qui utilisent Fivetran pour centraliser et transformer leur data.









