
La fondation des données pour l'IA
Data automatisées pour des agents autonomes
Déplacez, gérez et transformez les données en toute sécurité pour optimiser les analyses, les opérations et l'IA à grande échelle.
Commencer gratuitement

Pfizer fait progresser ses essais cliniques grâce aux données en temps réel, réduisant ainsi le temps de traitement de plusieurs heures à quelques minutes tout en garantissant la conformité.



National Australia Bank accélère l'innovation en matière d'IA, réduisant les coûts liés aux données de 50 % et améliorant les performances du ML de 30 %.



Coke One North America stimule l'innovation en matière d'IAet de ML grâce aux données SAP en temps réel pour environ 35 000 utilisateurs.


Tinuiti réalise l'intégration des clients 120 fois plus rapidement et réduit les coûts grâce à un data lakeévolutif et prêt pour l'IA.
PARTENAIRE DE CONFIANCE DES PRINCIPALES ENTREPRISES SPÉCIALISÉES DANS LES DATA ET L'IA



Tout le contexte dont votre IA a besoin
Fournissez en continu des data fiables provenant d'applications SaaS, de bases de données, de progiciels de gestion intégrée (ERP) et de connecteurs vers votre data warehouse ou data lake, puis exploitez-les dans les analyses des applications commerciales, les opérations et l'IA pour générer un impact concret.
Découvrez plus de 900 sources et destinations



























Effortlessly move data from any source to any destination
Our automated, high-performance pipelines reliably move critical business data from 700+ sources including SaaS applications, databases, ERPs, and files to data warehouses, data lakes, and more.





























La plateforme Fivetran
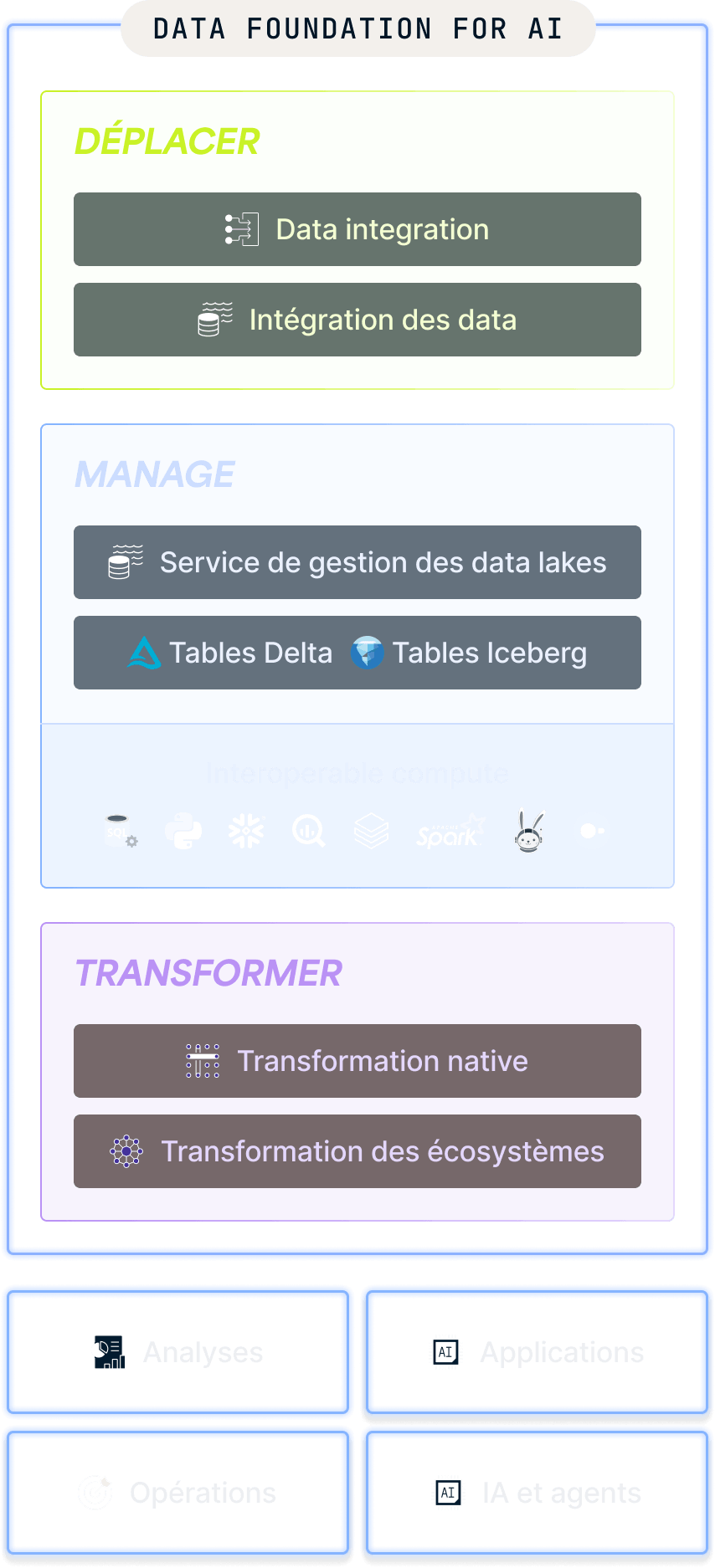
Déplacez des data de manière fiable et sécurisée
Fournissez des data fiables et de haute qualité à partir de n’importe quelle source à vos data warehouses, data lakes et applications, en optimisant les analyses et l’IA grâce à des pipelines haute performance entièrement gérés.
Gérez les data dans des formats ouverts
Le Service de gestion des data lakes (Managed Data Lake Service) de Fivetran fournit des data dans des formats de table ouverts tel que Iceberg et Delta Lake, ce qui contribue à normaliser l'architecture du data lake et à réduire les doublons ainsi que les coûts d'infrastructure
Transformez les data en informations fiables
Exécutez des transformations SQL directement dans votre destination selon un calendrier fiable, en transformant les data brutes en ensembles de data fiables et prêts pour l’analyse, sans orchestration manuelle.
Conçu pour répondre aux normes exigées par les équipes de sécurité
La confiance dans l’IA commence par des data fiables. Les certifications d'entreprise, les contrôles des data en temps réel et la flexibilité de déploiement aident les organisations à réduire les risques et à développer leurs capacités d'analyse, leurs opérations et l’IA en toute confiance.
En savoir plus sur les fonctionnalités de sécurité





Nos clients exécutent les analyses, les opérations et l'IA à partir de data auxquelles ils font confiance et d'une infrastructure conçue pour être évolutive, ce qui accélère la mise en œuvre et génère un impact commercial durable.
.avif)
.svg)





Chiffres à l’appui
Chez Fivetran, nous nous concentrons sur la fiabilité et le déploiement pour nos clients.
+ de 500 Go/h
Débits historiques
+ de 9,1 pétaoctets
Volume de data synchronisées par mois
+ de 33,5 millions
Modifications de schémas traitées par mois
102,9 millions
Modèles de transformation exécutés par mois
+ 156,5 millions
Synchronisations de pipelines par mois
+ de 2 milliards
Lignes synchronisées par mois
Fonctionnalités de niveau professionnel, intégrées
Sécurité
Protégez les data sensibles avec des réseaux privés, l’anonymisation de colonnes, le déploiement privé et bien plus encore.
.svg)
Gouvernance
Connaissez, protégez et faites évoluer vos data grâce au déplacement de data gérées

Extensibilité
Intégrez Fivetran de manière fluide dans votre écosystème data.
Déploiement hybride
Déplacez toutes vos data en toute sécurité sans compromettre les performances.




